在Python中使用Flask、Requests、BeautifulSoup和 TextBlob构建一个文本分析应用程序


介绍
本文介绍了如何构建一个基于Python和Flask的web应用程序,用于在互联网资源(比如博客页面)上执行文本分析。为了执行文本分析,我将使用Requests获取web页面,使用BeautifulSoup解析html和提取可视文本,并应用TextBlob包来计算一些情感得分。本文的代码托管在GitHub上,所以请复刻并使用它进行试验。

TextBlob情感分析基础
TextBlob Python包是自然语言工具包(NLTK)库的一个包装器,目的是抽象其复杂性。
使用TextBlob与实例化TextBlob主类一样简单,你只需要向它传入要分析的文本数据。
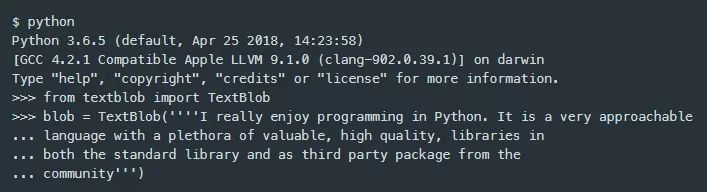
基本的TextBlob对象有一个名为情感(sentiment)的命名元组字段,它本身有两个字段: 极性和主观性。这两个字段都是情感的数值测量,极性在-1到1之间,-1表示语言上是消极的句子,值达到+1时被认为语言上是积极的句子,值为0时表示语言上是中性的句子。主观性字段的范围是从0表示客观情感到1表示主观或固执己见。sentalizer演示应用程序将报告页面总情感的这些值。
对于上面的例子来说,这就是它的总情感。

TextBlob还会将情感分解为更细的粒度级别,比如句子甚至单个单词。实际上,TextBlob类有一个名为句子的列表字段,其中包含一个 Sentence对象的集合。Sentence 对象与TextBlob类本身非常相似,只不过它只表示句子,而不表示整个文档。与TextBlob一样, Sentence 对象也有一个情感命名元组和一个名为words的Word对象集合。该sentalizer应用会对Sentence对象集合进行评估,并找出极性最强和最不强的句子,以及最客观和最主观的句子。
下面是前一个示例的情感值。
TextBlob包中包含了很多的功能,我鼓励读者在优秀的TextBlob文档中去发现这些功能,并进行进一步的实验,但是,我在这里只演示在文档和句子级别情感的用法。
Flask 应用程序开发本地环境设置
首先,创建一个Python3虚拟环境,激活它,然后安装所需的库。

激活虚拟环境(Windows)

激活虚拟环境(Mac / Linux)

安装Python包

获取Text Blob (NLTK)语料库文件
NLTK语料库文件用于指导文本数据的评估。此命令将在用户的主目录中名为nltk_data的目录中安装语料库数据文件。

构建Flask Sentalizer文本分析应用程序
安装了必要的Python库和支持数据文件后,我开始构建应用程序,首先创建一个名为sentalizer的应用程序包,然后在我最喜欢的文本编辑器/ IDE,Visual Studio Code,中打开它。

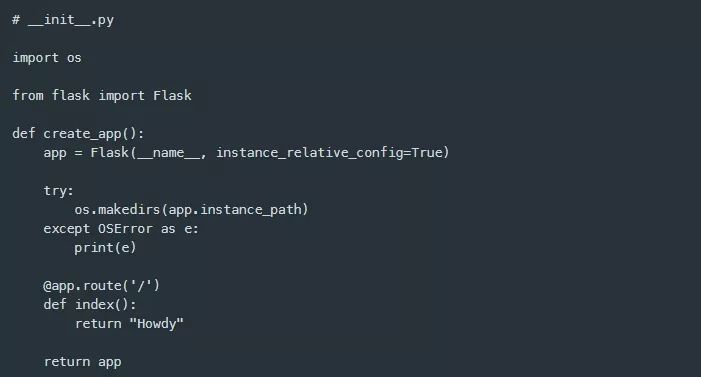
我添加了一个将目录转换为包的 __init__.py模块。在 __init__.py模块中,我创建了一个应用程序工厂函数,用于创建Flask应用程序的实例,如官方Flask文档中所示。
首先,我想通过运行flask开发服务器来测试设置,并确保在进一步深入之前可以从浏览器中访问它。
运行开发服务器 (Mac / Linux)
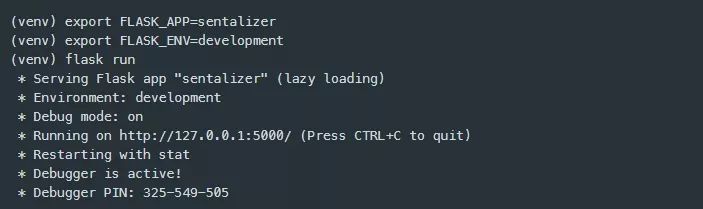
运行开发服务器 (Windows)
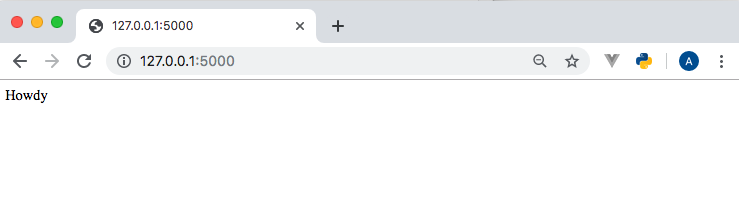
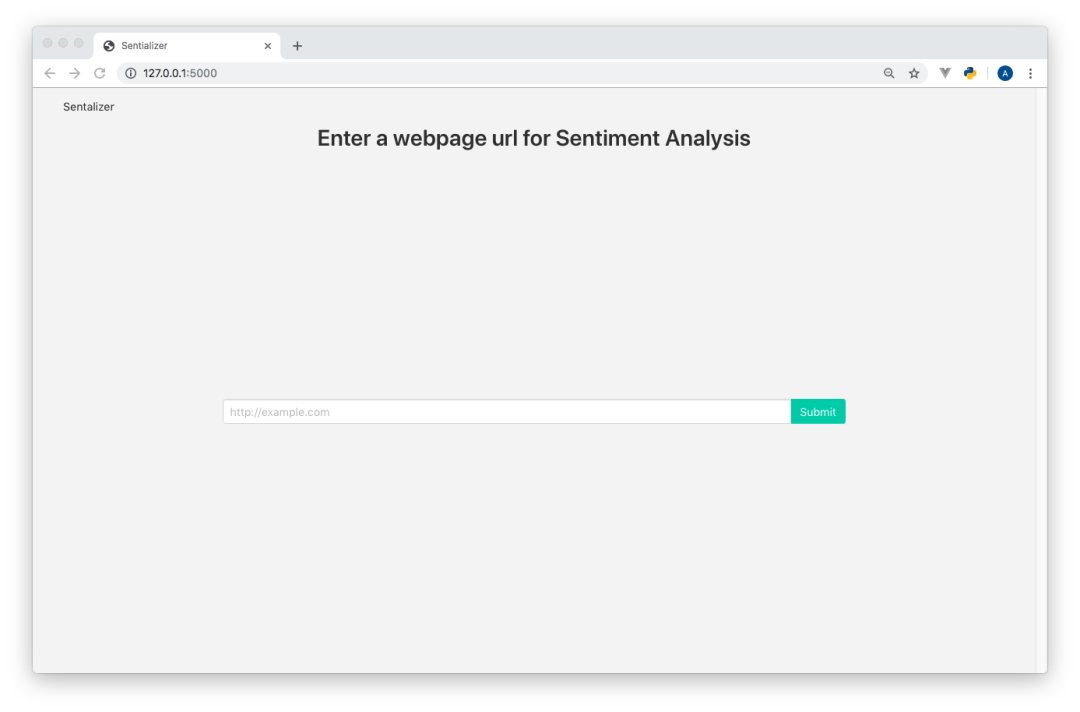
我将浏览器指向http://127.0.0.1:5000,显示如下。
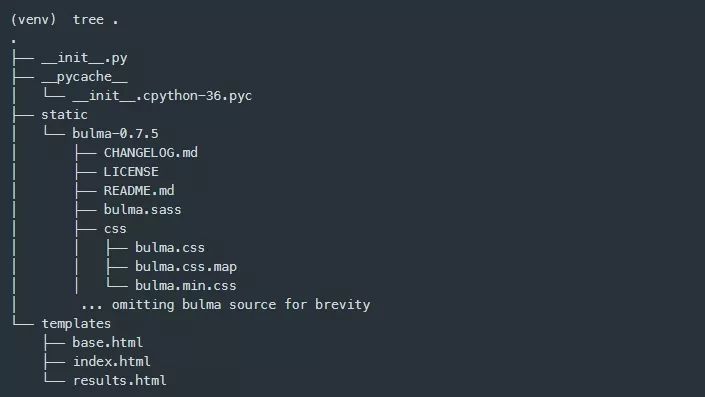
显然这并不令人兴奋,所以我将继续。接下来,我将在sentializer包中添加两个新的目录。一个目录名为templates,用于存放Jinja HTML模板。另一个目录名为static,它包含一个名为Bulma的CSS框架,用于去掉单调的HTML外观。下面是tree命令的输出,所以你可以看到我在做什么。
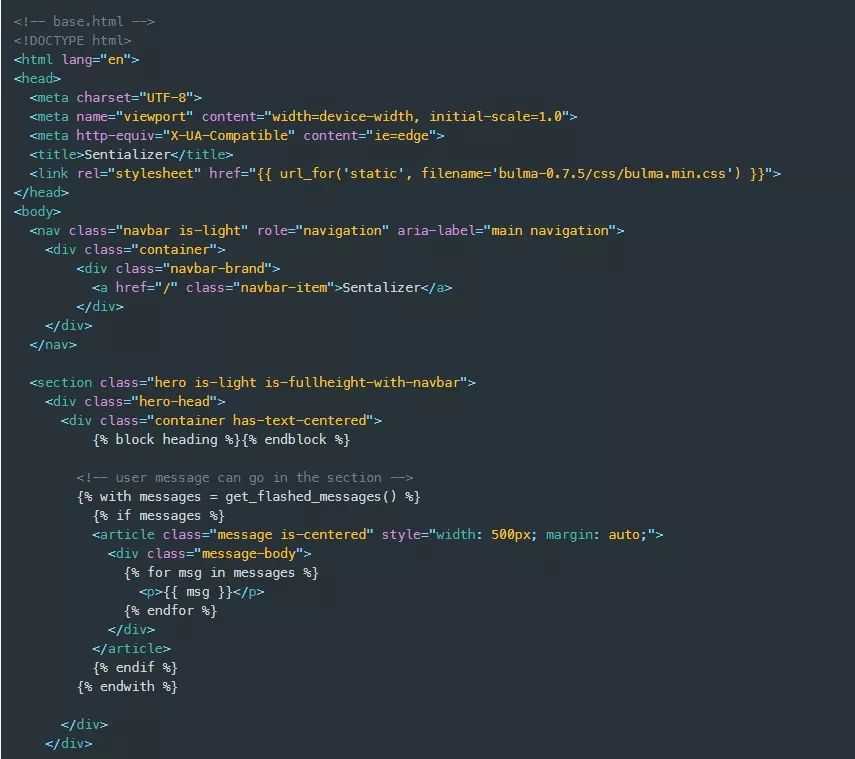
我首先构建base.html模板,它是另外两个页面的主布局。这个base.html模板引用了bulma css的源代码,并创建了一个导航条,其中包含一个指向主页路径的logo链接。此外,我使用{% block %}语法定义了两个Jinja代码块部分。这些代码块用于通过index.html和results.html模板来将标题和主要内容注入其中,这些模板将扩展base.html。
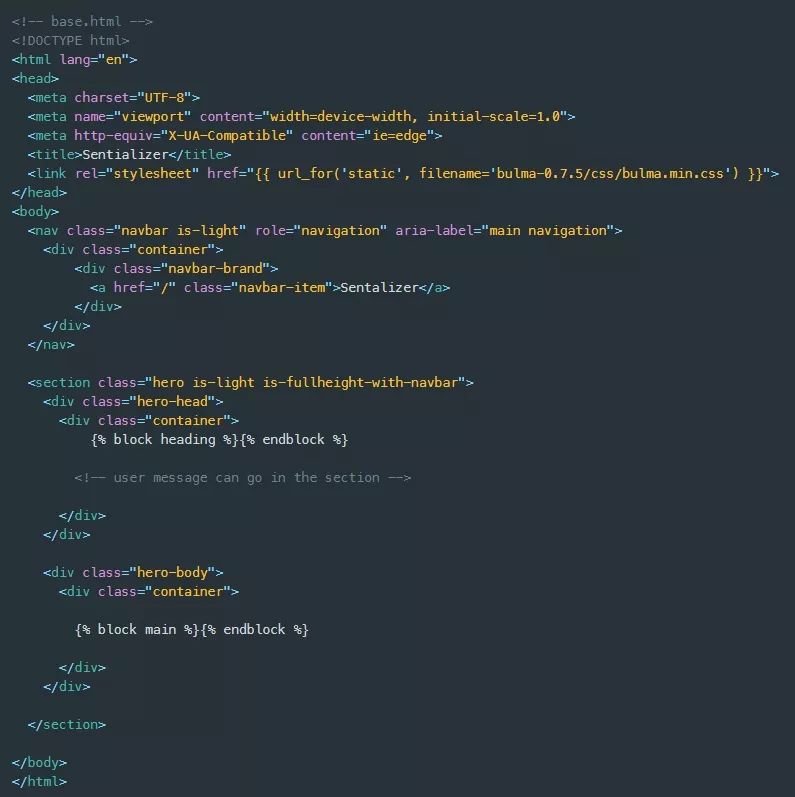
注意为模板构建资源的引用URI路径所使用的url_for(…)模板过滤器。此模板过滤器函数可用于所有模板的上下文。这里我使用它来引用bulma css文件。另一个值得注意的部分是围绕url_for函数的部分,此

内插大括号用于计算Python代码并将其内容输出到相应位置。还有一种使用大括号的插值构造,

它与程序控制语言元素一起使用。
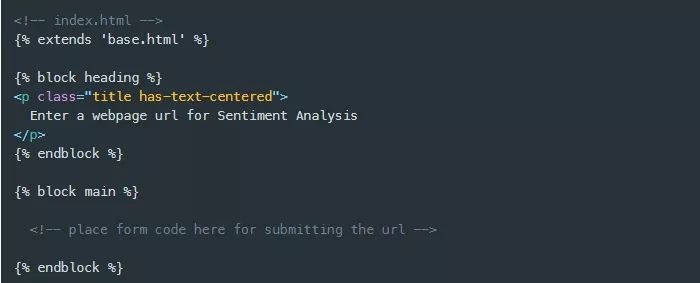
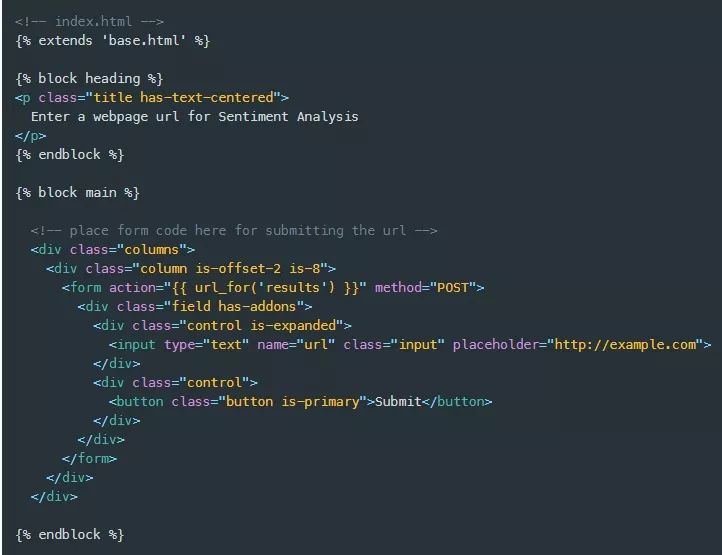
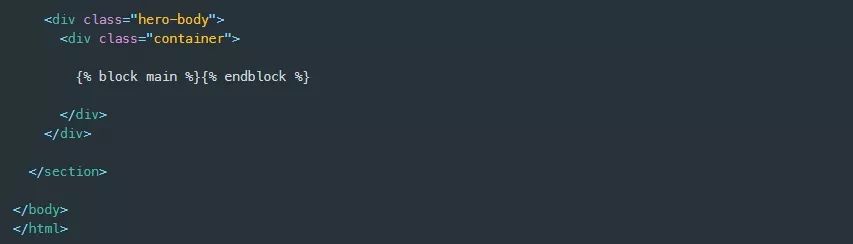
接下来,我将构建index.html模板,首先从扩展base.html模板开始,使用extends模板上下文帮助器跟着用引号括起来的base.html文件的名称来完成。然后,我为标题和主区块提供了一个实现。现在标题就包含一个段落元素,主块包含一个占位符注释,稍后我将在其中添加一个表单和一个用于收集网页url的输入字段,以及一个提交按钮。
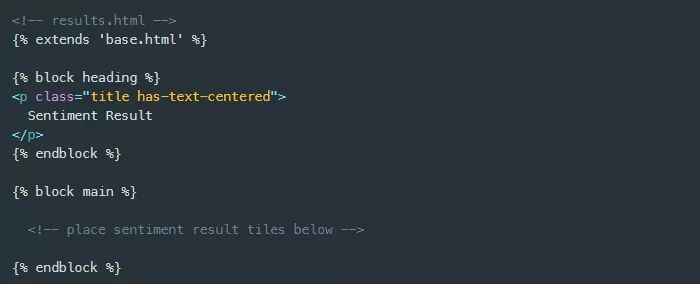
我对results.html模板做了类似的处理,它最终将显示一系列块,每个块都包含一个计算出的情感值,用于提交的url页面的文本分析输出。
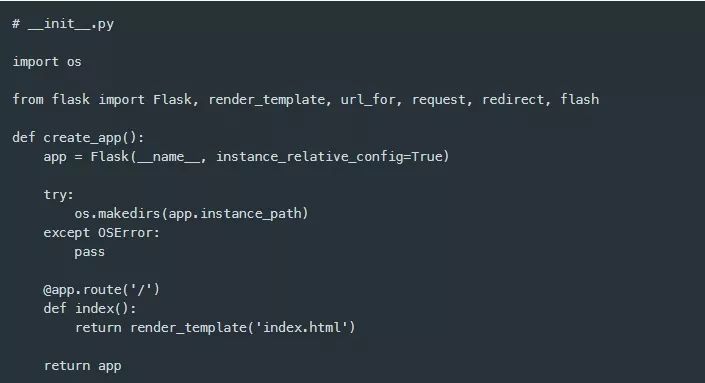
这是模板的一个良好开端,因此,我将继续让Flask应用程序提供index.html和results.html模板。回到前面的__init__ .py模块中,我从将要使用的Flask包中添加了一些常见的导入。我现在要关注的导入是render_template函数, 我将使用它来加载index.html模板,该模板将被处理并作为html返回。当/ url被请求时,Flask应用程序将返回所有这些内容。下面是更新后的__init__ .py模块。
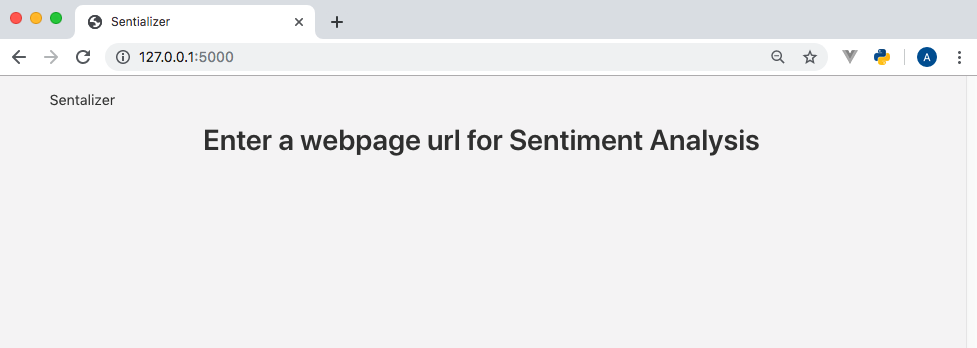
保存了__init__ .py模块之后,如果开发服务器仍在运行,Flask开发服务器应该会重新加载自己,否则就需要重新启动。重新加载指向http://127.0.0.1:5000/的浏览器,现在会显示如下内容。
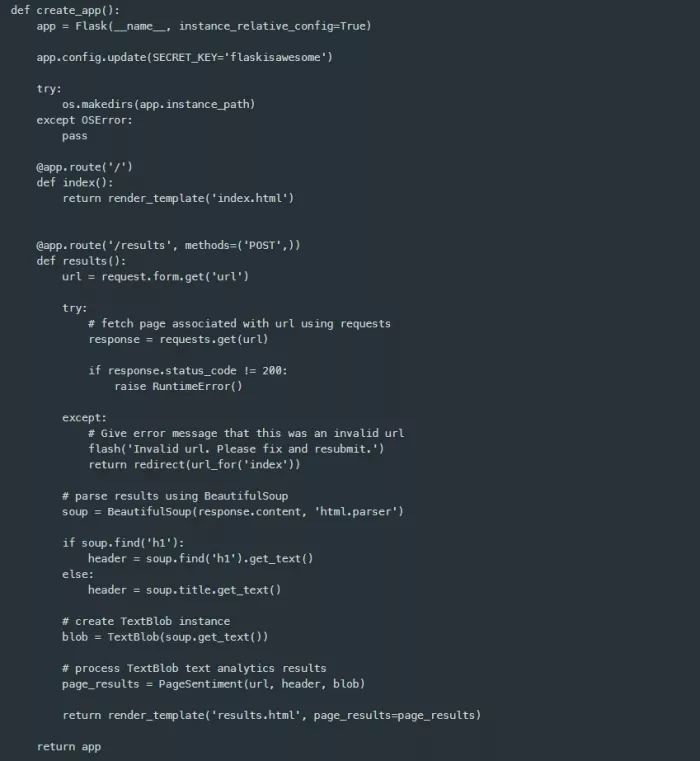
现在,我可以创建一个新的route(路由)和视图函数来提供result.html模板。为此,我在@app.route('/results')装饰器下面定义了一个名为results(…)的新函数,并类似地使用render_template来返回results.html模板。但是,这需要在装饰器中进行一个更改,使其只接受POST请求方法,如下所示。
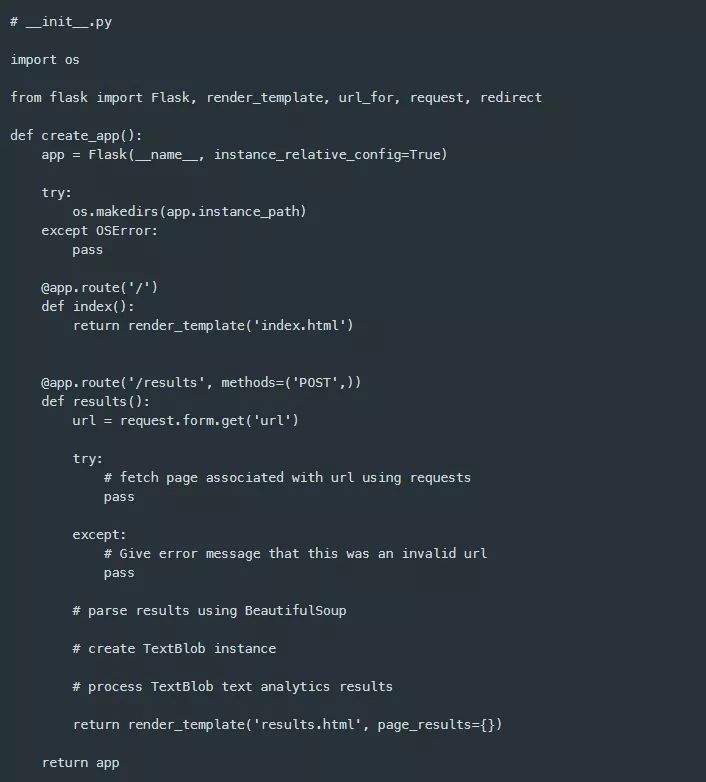
新引入的results()视图函数需要一个名为url的表单字段,它可以由我之前从flask包中导入的全局请求对象上的表单字典字段进行检索。我还添加了一些注释来描述执行文本分析所需的程序流,然后再次使用了render_template函数,但是使用了一个新的关键字参数page_results,目前它只是一个空字典。
现在我有了一个/results路由来POST(请求)一个url,因此,我可以向index.html添加一个表单。注意,在下面的表单元素中,我再次使用了url_for(…)方法,但这次我提供了一个名为“results”的参数,它是view_function函数的名称,用于我希望将表单数据POST到的路由。
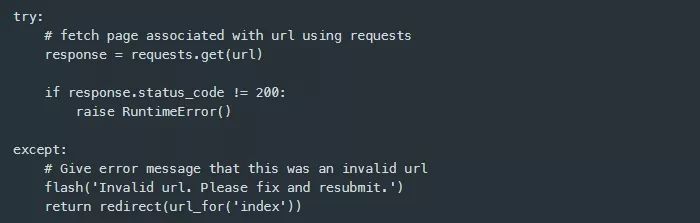
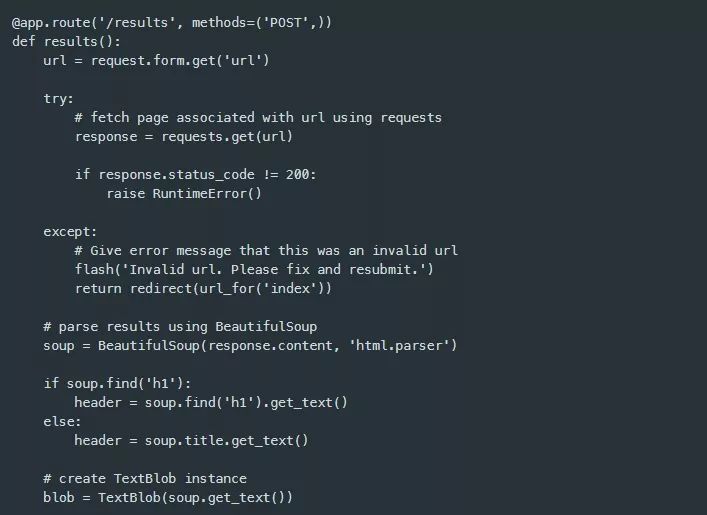
该应用程序能够接受一个代表页面的url来对其实执行情感分析,所以,我现在可以来实现文本分析功能。正如我在results(…)视图函数注释中已经提到的,首先需要使用已POST的url来获取该页面。为此,我导入了requests库,并使用url来调用requests.get(…)方法。这是一个使用未验证url发出的HTTP请求,该url可能指向或不指向一个真实的web资源,因此,引发异常是很有可能的。如果一个异常被捕获,应用程序会向用户显示一条错误消息。
为了显示错误消息,我将通过前边从Flask包中导入的flash方法来使用消息闪烁功能。此外,我需要给应用程序一个密钥,因为消息闪烁用到了session,该session过程需要在应用程序实例的配置字典中设置一个秘钥,如下所示。

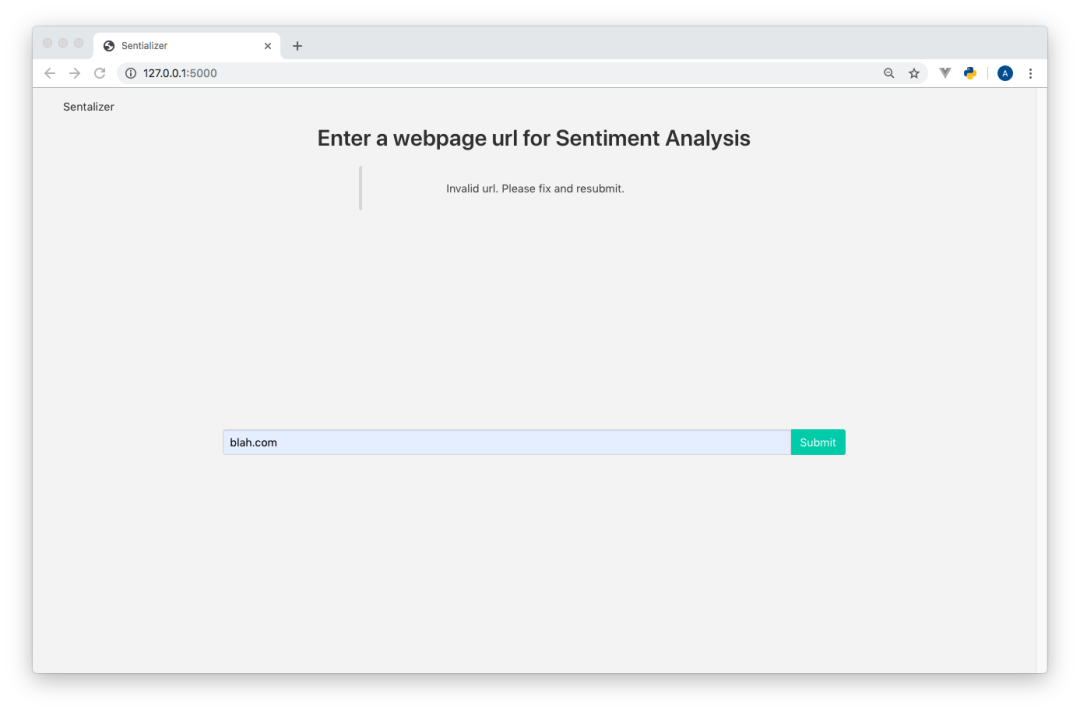
现在,如果由于web页面没有成功返回而引发异常,应用程序就会调用flash(…)方法,并将用户重定向到index.html页面。
要在此UI中看到闪烁的消息,我们还需要做一些工作。在base.html中的上面,在消息注释下面,我添加了一个{% with…%}模板块,用于调用get_flashed_messages模板函数(对所有模板都可用),并将返回的集合分配给一个messages变量。然后对该messages变量进行遍历并显示。
下一步是从bs4包中导入BeautifulSoup类,以及从textblob包中导入TextBlob类。假设一个网页被成功获取,程序控制通过try / except部分进行传递,返回的内容被解析为一个BeautifulSoup对象中的可查询的文档对象模型(DOM)表示形式,并被分配给一个soup变量。h1元素或者页面标题(如果h1不存在的话)会在将所有可视化文本传给TextBlob之前被从soup变量中提取,然后在其实例化期间被分配给一个名为blob的变量。
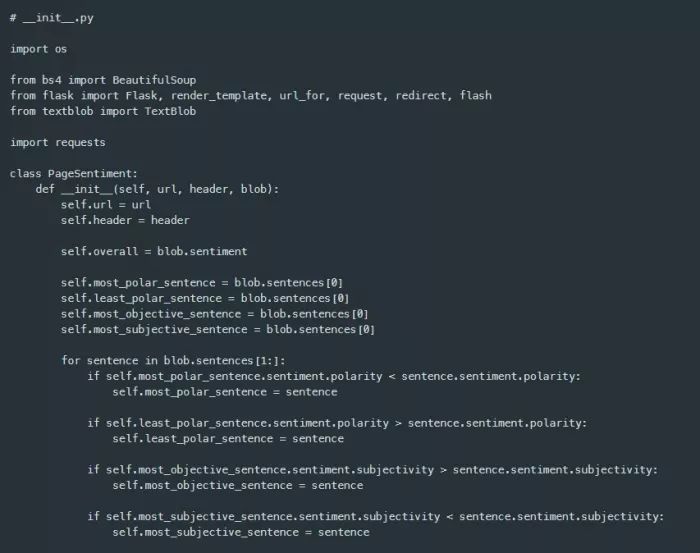
收集了所有必要的数据后,我现在可以查询TextBlob对象的字段来显示页面的整体情感以及页面包含的各种句子的倾向性。为此,我将创建一个名为PageSentiment的自定义Python类型或类,它将维护关于一个页面的url、标题、总体情感以及具有最高情感得分的句子的信息。我将PageSentiment类放在create_app函数上方,如下所示。
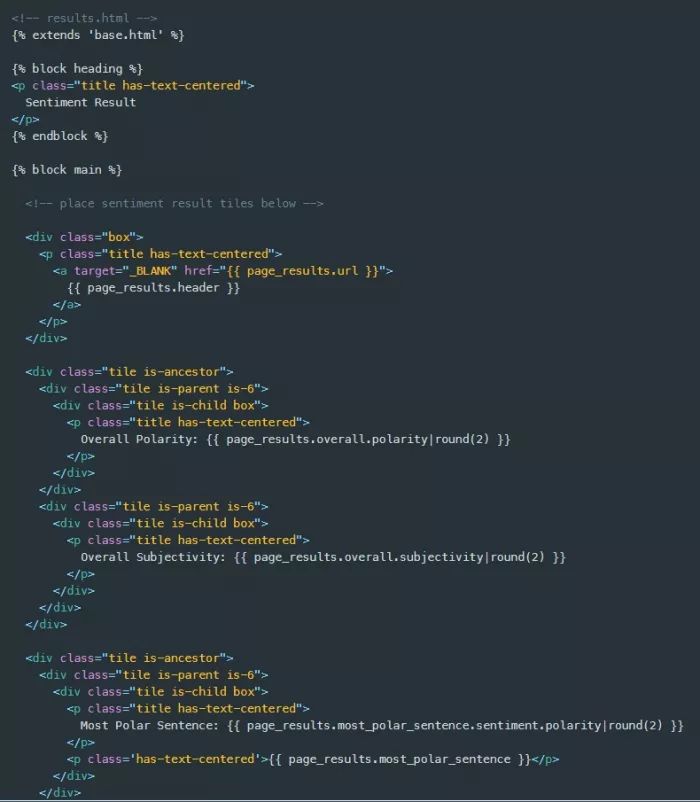
现在剩下的是在results.html模板中显示提交的url页面的情感信息。为此,我将PageSentiment类对象page_results中的每条信息进行分组,并通过bulma tile组件中的render_template页面传递给results.html模板,如下所示。
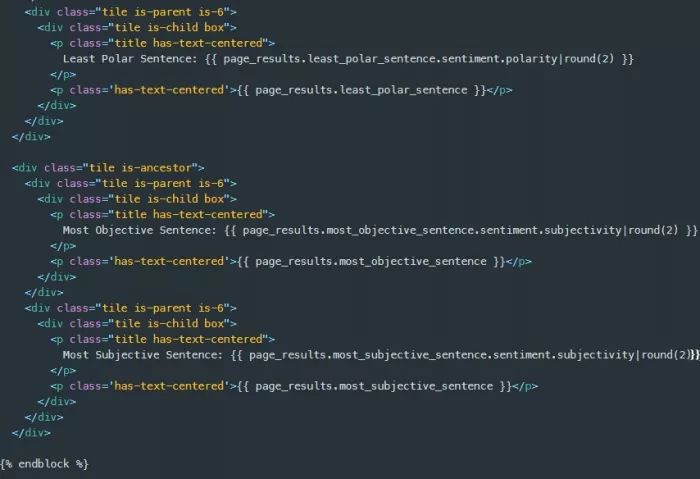
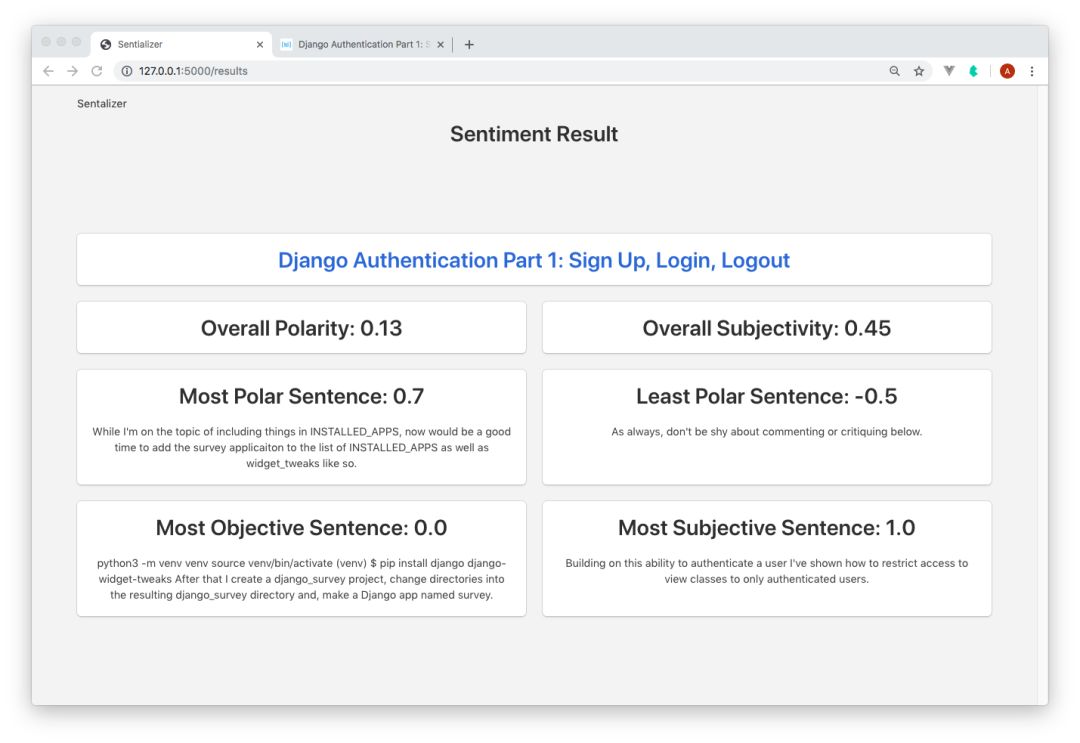
下面是在thecodinginterface.com上运行第一篇名为《Django Authentication Part 1: Sign Up, Login, Logout》的博客文章的输出。
进一步学习Python、Flask 和Webscraping的一些资源
使用Python进行Web爬取: 《从现代Web收集更多数据》是一本关于Web爬取的好书,它演示了如何使用BeautifulSoup从Web页面中提取内容。
Miguel Grinberg的新编写的Flask Web 开发: 《使用Python开发Web应用》是迄今为止市场上质量很好的Flask书籍。
结论
在本文中,我演示了如何使用Flask构建一个简单的基于Python的web应用程序,该程序会使用Requests、BeautifulSoup和TextBlob包获取web页面并对其执行文本分析。我很感谢你的跟进,并希望本文对你来说既有用又有趣。在后续文章中,我将展示如何集成Redis和Celery来实现后台异步任务去获取和分析页面,以及如何将此应用程序部署到一个云端的虚拟专用服务器中。
英文原文:https://thecodinginterface.com/blog/text-analytics-app-with-flask-and-textblob/
译者:忧郁的红秋裤