NeurIPS 2019 | 全参数化分布,提升强化学习中的收益分布拟合能力
编者按:强化学习正在游戏领域中被广泛应用,其中基于分布拟合的强化学习算法是目前性能最好的一类方法。在这类方法中,如何参数化收益分布是算法设计的核心问题。现有的参数化方法在对累积概率分布进行拟合的时候,往往是选择固定的分位点概率或者随机采样的分位点概率。但是不同分位点概率带来的拟合误差往往差别很大。为了更好的拟合收益分布,微软亚洲研究院提出了可自适应的累积分布分位点概率,可以找出对于拟合累积分布函数最关键的几个分位点概率,实现了全参数化的分位函数,大大提升了对收益分布的拟合能力。
目前,强化学习正广泛应用于游戏领域。由于游戏环境本身的不确定性,玩家(agent)的总收益(return)实际上是一个随机变量,而强化学习的目标则是找到能最大化该随机变量的期望的策略。近年来,强化学习领域的研究者发现,在深度强化学习中,相比于仅仅考虑总收益的期望,逼近总收益这个随机变量的分布能够带给网络更多信息。基于分布拟合的一系列算法,C51、QR-DQN、IQN 在常用的游戏测试环境 Atari Game 上取得了非常大的突破。
如何参数化收益分布是基于分布的强化学习算法(distributional reinforcement learning)的核心问题,现有工作中对分布的拟合往往是在固定的几个点上。比如,在最早提出的 C51 算法中,计算了总收益为-10到10之间均匀分布的51个值的各自的概率。而在随后的 QR-DQN 工作中,目标从概率分布函数成为了拟合累积分布函数,计算在0到1之间均匀分布的分位点概率(quantile fraction)所对应的分位点值(quantile value)。这些均匀分布的位置显然对拟合分布是有很大限制的,并没有将分布完全的参数化表示。因此随后提出的 IQN,对随机采样的分位点概率进行拟合,在网络中建模了从分位点概率到分位点值的映射,效果也十分明显,超越了过去所有的算法。
微软亚洲研究院在此基础之上,提出了可自适应的累积分布分位点概率位置,可以找出对于拟合累积分布函数最关键的某几个分位点概率,从而将分布函数完全地参数化,大大提升了对分布函数的拟合能力。现有的工作通常只参数化了概率轴或者价值轴,我们的算法能够同时学习分位点概率位置和分位值, 同时参数化了分布函数的两个轴,因此我们的算法称为全参数化的分位函数(Fully-parameterized Quantile Function),简称FQF。FQF 在 Atari Game 中也超越了 IQN,取得了当前非分布式(non-distributed)算法中最高的分数。值得一提的是,当前取得最高分数的分布式(distributed)算法使用的数据样本远远多于 FQF。
FQF 的核心思想是最小化拟合分布与目标分布的 Wasserstein 距离,其定义即为图1所示的分位函数(即累积概率分布函数的反函数)与其阶梯状拟合阴影部分面积。
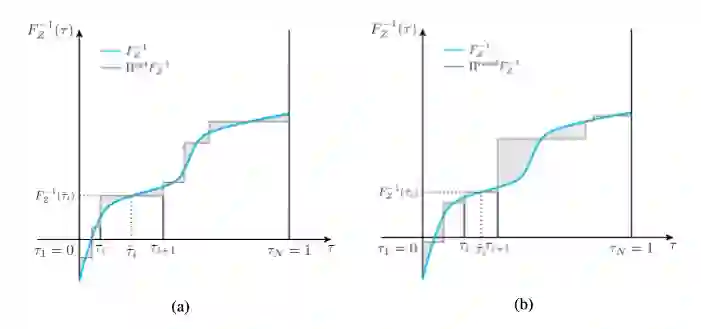
图1:在两组随机采样的分位点下的累积概率分布(Cumulative Distribution Function, CDF)的逆函数, 分位函数(quantile function)的不同的拟合误差(阴影部分面积)
图1中蓝色曲线为真实分布,左图为一组良好的分位点概率下拟合出的阶梯状分布,而右图为随机的分位点概率位置下拟合出的阶梯状分布。可以看到,良好与非良好之间带来的差距是极大的,这种差距会直接影响到对总收益期望的估计。因此,找到良好的分位点概率位置对拟合分位函数至关重要。
显然,找到良好的分位点概率位置中最复杂的一步便是计算上图中的阴影部分面积。计算该面积会涉及到积分,在实际算法实现中不仅耗费资源而且必然存在误差。但是在推导了最小化阴影面积所对应的分位点取值后,该阴影面积有了一个良好的数学形式,使得其对分位点概率位置的导数中不包含积分,从而避免大量计算。
基于上述优化方法,我们提出了预测最优概率位置的网络(fraction proposal network)来预测对每个状态最优的分位点概率(quantile fraction)。基于合理选择的分位点概率,我们参考IQN中对该概率做嵌入(embedding)后送入分位数计算网络(quantile function network),采用 Quantile Huber Loss 进行更新,便可以得到完整的上述的阶梯状分布拟合。
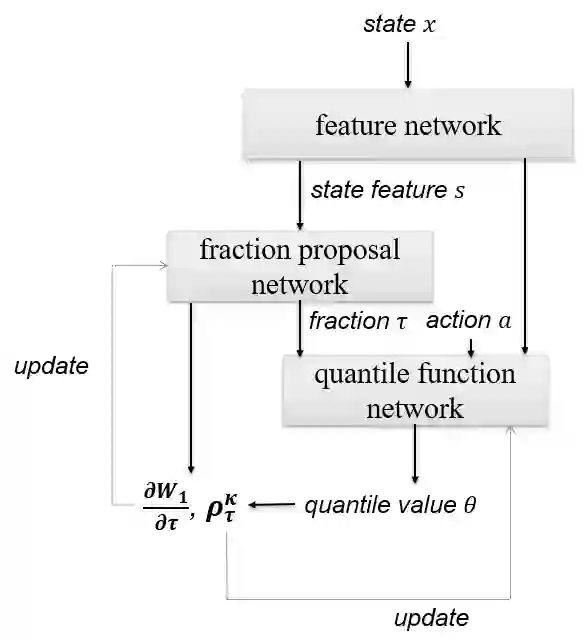
图2:分位点概率生成网络(fraction proposal network)和分位数计算网络(quantile function network)以及迭代更新流程
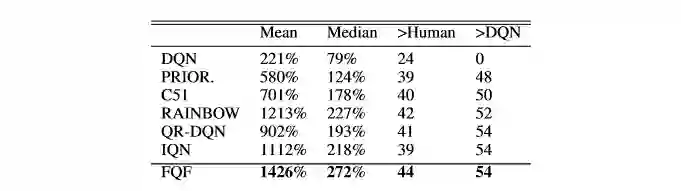
表1:全参数化分布算法(FQF)在 Atari Game 环境上与其它强化学习算法的对比
表1为全参数化分布算法(FQF)对比其它强化学习算法在 Atari Game 环境上的实验结果。目前在非分布式的强化学习算法中,全参数化分布算法取得了最好的成绩。而在通过表2的训练初期游戏实际画面我们也可以看到,由于在不同状态时总收益的分布都不同,所对应的良好分位点概率位置也都不同。

表2:IQN 和 FQF 在不同分位点数目(N)下在某6个 Atari Game 上的平均分数
对比随机选择分位点概率位置的 IQN,可以看到当所选分位点概率个数较小的时候,两者差距较大,当选择个数较多的时候差距缩小,这符合随机取样的特性。
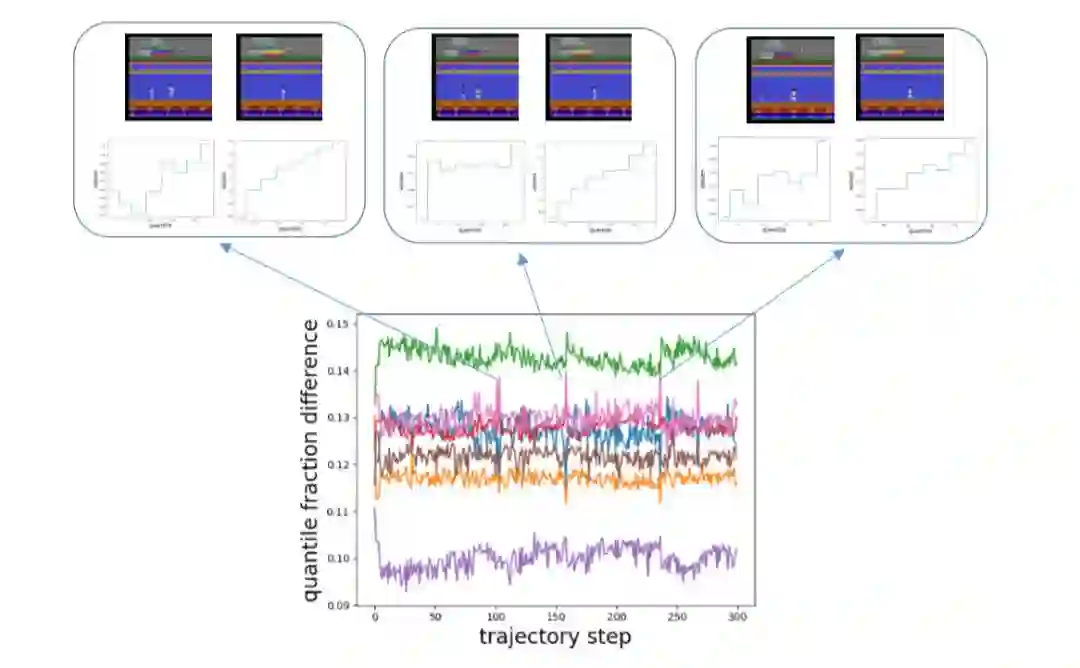
图3:在某次游戏的路径上,相邻分位点的概率之差
图3中不同颜色的曲线代表着不同的相邻分位点概率位置的差值,比如绿色曲线代表第二个分位点与第一个分位点的概率之差。可以看到,在画面中有一个人和有两个人的时候,我们的网络给出的分位点概率位置是非常不同的,在分位点概率之差的曲线上会有一个跳变。更详细的差值变化请观看下方视频。
机器学习中往往有需要拟合的目标,而强化学习的不同之处在于,这个目标(总收益)的真值是未知的。在基于神经网络的强化学习中,刻画目标的多维属性(分布)能够比刻画单一属性(期望)更加有效地学习。而受限于网络无法刻画无穷多维的属性,选择刻画哪些属性才能更好的描述目标就显得尤为重要。
该篇论文从减小分布拟合误差的角度出发,提出了一种全参数化的分布,有效刻画了总收益分布,在强化学习环境中表现出了优异的性能。在其他领域中,刻画多维属性的方法也能够提供非常大的帮助。比如我们熟悉的知识蒸馏就是非常典型的从单一目标属性出发,刻画多维属性的例子。相信这种思想在未来也能够应用于各个领域。
了解更多技术细节,请点击阅读原文查看论文:
Fully Parameterized Quantile Function for Distributional Reinforcement Learning
论文链接:https://arxiv.org/abs/1911.02140
你也许还想看:








