拔掉机器人的一条腿,它还能学走路?| 三次元里优化的DRL策略
行走栗 发自 凹非寺
量子位 出品 | 公众号 QbitAI

迪士尼的机器人,不管剩几条腿 (n>0) ,都能学会走路。
那么,是怎么学的?
研究团队不用模拟器,直接在硬件上修炼深度强化学习 (DRL) 的策略。
真实世界,或许比模拟器要单调一些。不过,有物理支持的经验,可能更加珍贵。
除了有清新脱俗的训练环境,这只机器人,也并不是一只机器人而已。
想要几条腿,问过机器人吗?

机器人的腿是模块化的,就是说,你想给它装上一条、两条、三条腿,都可以。
嫌腿太多,拔掉一些也可以。反正只要有腿,机器人还可以重新学走路。
另外,机器人的腿还分三种,运动方式各不相同——
在分别介绍之前,先给各位一些方向感。
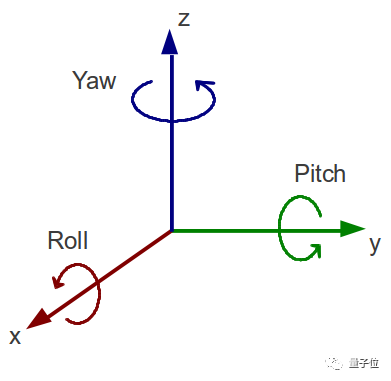
A腿,Roll-Pitch,横轴加纵轴。

B腿,Yaw-Pitch,竖轴加纵轴。

C腿,Roll-Yaw-Pitch,横轴加竖轴加纵轴。

于是,C腿比另外两条腿粗壮一些,似乎也可以理解了。
如果按最多能装六条腿来算,一共可以拼出多少种不同的机器人?

这样一来,即便不是模拟器,也算多姿多彩了。
两种DRL同步走
由于,不知道机器人什么时候,就会多条胳膊少条腿,迪士尼团队准备了两种深度强化学习算法。

一是TRPO (信赖域策略优化) 算法,沿用既定策略 (On-Policy) 的批量学习方法,适合优化大型非线性的策略。
二是DDPG (深度确定性策略梯度) 算法,用“演员-评论家 (Actor-Critic) ”的方法,优化策略。
不同的算法,不同的姿势
那么,在三次元学习过程中优化的策略,有多优秀?
按照腿的数量,分别来看一下。
一条腿

图中下者,是用TRPO学习完毕的A腿,与没有学过的A腿相比,走路姿势已经明显不同,速度也真的加快了一点点。
两条腿

这是两条B腿在TRPO熏陶之下形成的姿势,轻快地触地,轻快地弹起。

这同样是两条B腿,但算法换成了DDPG,姿势又完全不同了,好像慵懒地向前翻滚。
三条腿

这次,机器人长了三条B腿。有了TRPO的加成,它用欢脱地节奏点着地,和双腿TRPO的操作很相似。
总体看上去,用TRPO训练过后,机器人会比较活跃,用DDPG修炼之后,机器人就有了佛系属性。
不管它有怎样的个性,研究人员都很开心。毕竟,那表示深度强化学习算法,是有效的。一看就知道,是谁带出的徒弟。
你也想被支配一下?

同性交友网站的章鱼猫 (假装) 表示,它也想接受DRL算法的蹂躏,然后解锁更娇嫩的舞姿。
论文传送门:
https://s3-us-west-1.amazonaws.com/disneyresearch/wp-content/uploads/20180625141830/Automated-Deep-Reinforcement-Learning-Environment-for-Hardware-of-a-Modular-Legged-Robot-Paper.pdf
— 完 —
加入社群
量子位AI社群18群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot8入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot8,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态




