房价会崩盘吗?教你用 Keras 预测房价!(附代码)

雷锋网 AI 研习社按:本文为雷锋字幕组编译的技术博客,原文 Custom Loss functions for Deep Learning: Predicting Home Values with Keras for R ,作者 Ben Weber 。
翻译 | 宥佑 林骁 整理 | 凡江

我最近在读「深度学习与 R」,R 对于深度学习的支持着实让我惊艳!
书中其中一个应用例子就是用于预测波士顿的房价,这是一个有趣的问题,因为房屋的价值变化非常大。这是一个机器学习的问题,可能最适用于经典方法,如 XGBoost,因为数据集是结构化的而不是感知的。然而,这也是一个数据集,深度学习提供了一个非常有用的功能,就是编写一个新的损失函数,有可能提高预测模型的性能。这篇文章的目的是来展示深度学习如何通过使用自定义损失函数来改善浅层学习问题。
我在处理财务数据时遇到过几次的问题之一是,经常需要构建预测模型,其中输出可以具有各种不同的值,且在不同的数量级上。例如,预测房价时可能会发生这种情况,其中一些住房的价值为 10 万美元,其他房屋的价值为 1000 万美元。如果您在这些问题(如线性回归或随机森林)中使用标准机器学习方法,那么通常该模型会过拟合具有最高值的样本,以便减少诸如平均绝对误差等度量。然而,你可能真正想要的是用相似的权重来处理样本,并使用错误度量如相对误差来降低拟合具有最大值的样本的重要性。

实际上,你可以在 R 中使用非线性最小二乘法(nls)等软件包明确地做到这一点。上面的代码示例演示了如何使用内置优化器来构建线性回归模型,该优化器将使用大标签值对样本进行超重,并介绍如何对预测值和标签执行对数转换的 nls 方法,这将会给样品比较相等的重量。第二种方法的问题是,你必须明确说明如何使用模型中的特征,从而产生特征工程问题。这种方法的另一个问题是,它不能直接应用于其他算法,如随机森林,而无需编写自己的似然函数和优化器。这是针对特定的场景,您希望将错误术语放在日志转换之外,而不是只需将日志转换应用于标签和所有输入变量的场景。
深度学习提供了一个优雅的解决方案来处理这类问题,替代了编写自定义似然函数和优化器,您可以探索不同的内置和自定义损失函数,这些函数可以与提供的不同优化器一起使用。本文将展示如何在使用 Keras 时编写 R 中的自定义损失函数,并展示如何使用不同的方法对不同类型的数据集有利。
下面的图片是我将要用做文章预览封面的,它显示了根据波士顿房价数据集训练的四种不同 Keras 模型的培训历史。每个模型使用不同的损失函数,但是在相同的性能指标上评估,即平均绝对误差。对于原始数据集,自定义损失函数不会提高模型的性能,但基于修改后的数据集,结果更喜人。
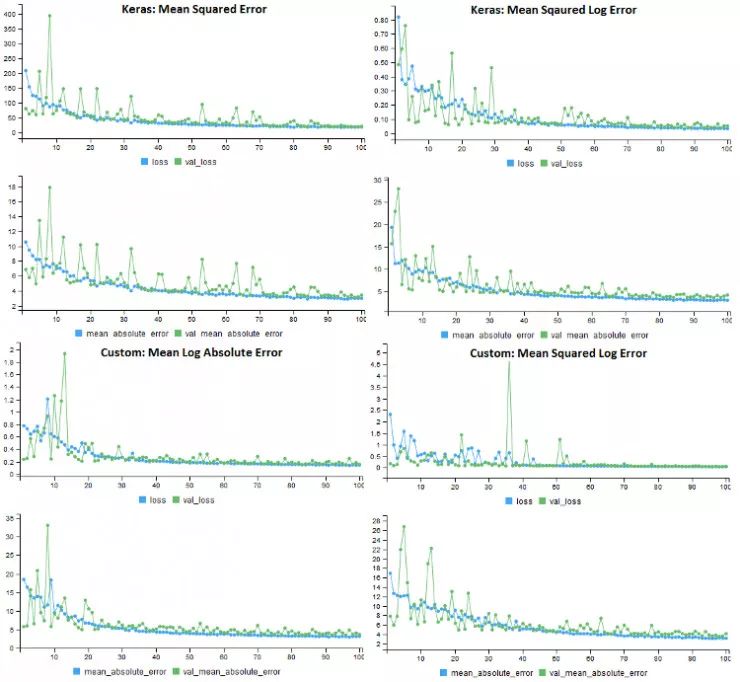
对原始房价数据集执行 4 项损失函数。所有模型均使用 MAE 作为性能指标。
用深度学习改进浅层问题
深度学习的一个重要特征是它可以应用于感知数据的深层问题,(如音频和视频)以及结构化数据的浅层问题。对于浅层学习(经典 ML)问题,你通常可以通过使用自定义损耗函数来查看浅层方法的改进,从而提供有用的信号。
然而,并非所有浅层问题都可以从深度学习中受益。我发现自定义损失函数在建立需要为不同数量级的数据创建预测的回归模型时非常有用。例如,在一个价值可以显著变化的地区预测房价。为了说明实践中是如何工作的,我们将使用由 Keras 提供的波士顿房屋数据集:
数据集-Keras 文件
数据集来自 IMDB 的 25000 条电影评论,用标签(正面或负面)对其进行标记。评论已经被处理过。
该数据集包括 20 世纪 70 年代波士顿郊区的房价。每个记录有 13 个属性对家庭进行描述,训练数据集中有 404 条记录,测试数据集中有 102 条记录。在 R 中,可以按如下方式加载数据集: dataset_boston_housing()。价格分布直方图显示在下面的左边,其中价格分布从 5 千美元到五万美元不等。原始数据集中不同的价格区间有相似的需求,因此自定义损失函数可能对拟合该数据太大用处。右侧的直方图显示有受益于使用自定义丢失的标签转换。右侧的直方图展示了经过标签转换之后的直方图,将损失函数运用到这些标签上将会获得更好地效果。
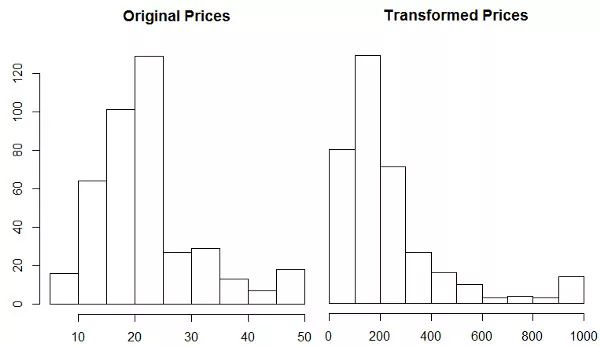
波士顿数据集包括原始价格和转换后的价格
对于如何将价格进行转换,我将标签转换成绝对价格,将结果平方,然后除以大的因子。这产生了一个数据集,其中最高价格和最低价格之间的差异不是 10 倍而是 100 倍。我们现在有一个可以从使用自定义损失函数中获益的预测问题。生成这些图的 R 代码如下所示。

Keras 中的损失函数
Keras中包含许多用于训练深度学习模型的有用损失函数。例如: mean_absolute_error() 就适用于数值在某种程度上相等的数据集。还有一些函数可能更适合转换后的住房数据,例如:mean_squared_logarithmic_error() 。 下面是由R为Keras提供的损失函数接口:

损失函数。R 是指 Python 当中的函数,为了真正理解这些函数是如何工作的,我们需要先了解到 Python 的损失函数代码。我们要研究的第一个损失函数是下面定义的均方误差。该函数计算预测值与实际值之间的差值,然后将结果平方 (使所有的值均为正),最后计算平均值。注意,该函数使用张量进行计算,而不是 Python 原语。当在 R 中定义自定义损失函数时将使用相同的方法。

我们将探讨的下一个内置损失函数是根据预测值与目标值的之间自然对数的差来计算误差。它在此处定义并在下面写出。该函数使用 clip 操作来确保负值不会传递到日志函数,并且向 clip 后的结果+1,这可确保所有对数转换的输入都具有非负数结果。这个函数与我们在 R 中定义的函数类似。

我们将探讨的两个自定义损失函数在下面的 R 代码段中定义。第一个函数,mean log absolute error(MLAE),计算预测值和实际值的对数变换之间的差值,然后对计算结果进行平均。与上面的内置函数不同,这种方法不能纠正错误。与上述对数函数的另一个区别是,该函数将显式比例的因子应用到数据当中,将房屋价格转换回原始值(5,000 至 50,0000)而不是(5,50)。这是有用的,因为它减少了+1 对预测值和实际值的影响。
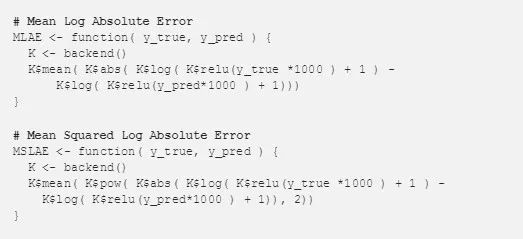
像 Python 函数一样,R 的自定义损失函数需要对张量(而不是 R 原语)进行操作。为了执行这些操作,需要使用 backend() 获取对后端的引用。在我的系统配置中,这返回了对 Tensorflow 的引用。
第二个函数计算日志错误的平方,与内置函数类似。主要区别在于我使用的是激活函数 relu 而不是 clip,并且对于特定的住房数据集,我进行价格缩放操作。
评估损失函数
我们现在有四种不同的损失函数,我们要用原始数据集和经过改造的住房数据集来对四种不同的损失函数的性能进行评估。本节将介绍如何设置 Keras,加载数据,编译模型,拟合模型和评估性能。本节的完整代码可在 Github 上找到。
首先,我们需要建立我们的深度学习环境。这可以通过 Keras 包和 install_keras 函数完成。

安装完成后,我们将加载数据集并应用我们的转换来改变住房价格。最后两项操作可以注释掉,使用原来的房价。
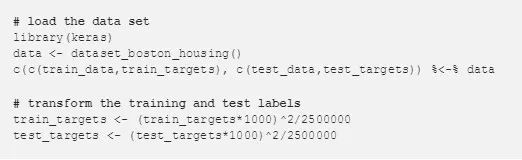
接下来,我们将创建一个 Keras 模型来预测房价。我使用了「Deep Learning with R」中示例的网络结构。该网络包括两层全连接层及其激励函数 relu,以及一个没有变换的输出层。

为了编译模型,我们需要指定优化器,损失函数和度量。我们将对所有不同的损失函数使用相同的度量和优化器。下面的代码定义了损失函数列表,对于第一次迭代,模型使用均方误差。

最后一步是拟合模型,然后评估性能。我使用了 100 个批次并且每个批次大小为 5,按照 20%的比例将分割出来的数据作为验证集。在模型训练完训练集之后,模型的性能通过测试数据集上的平均绝对误差来评估。

我用不同的损失函数训练了四种不同的模型,并将这种方法应用于原始房价和转换后的房价当中。以下显示了所有这些不同组合的结果。
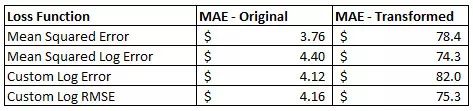
房价数据集损失函数的表现
在原始数据集上,在损失函数中应用对数变换实际上增加了模型的误差。由于数据在一个数量级内存在一定的正态分布,这并不令人惊讶。对于变换的数据集,平方对数误差方法优于均方误差损失函数。这表明如果您的数据集不适合内置的损失函数,自定义损失函数可能值得探索。
下面显示了转换数据集上四种不同损失函数的模型训练历史。每个模型使用相同的错误度量(MAE),但是具有不同的损失函数。一个令人惊讶的结果是,对于所有的损失函数来说,应用日志转换的方法验证错误率要高得多。
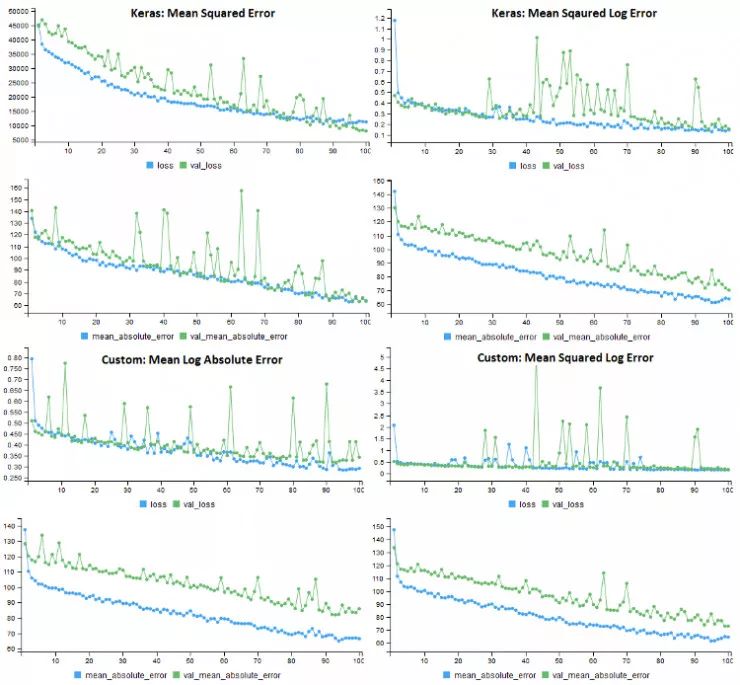
在转换后的房价数据集上对 4 种损失函数测试各自的性能。所有模型都使用 MAE 作为性能指标。
深度学习可以成为浅层学习问题的有用工具,因为您可以定义自定义的损失函数,这些函数可能会显著提高模型的性能。这不适用于所有问题,但如果预测问题不能很好地映射到标准损失函数,则可能会有用。
原文链接:
https://towardsdatascience.com/custom-loss-functions-for-deep-learning-predicting-home-values-with-keras-for-r-532c9e098d1f

从Python入门-如何成为AI工程师
BAT资深算法工程师独家研发课程
最贴近生活与工作的好玩实操项目
班级管理助学搭配专业的助教答疑
学以致用拿offer,学完即推荐就业

如何利用机器学习预测房价?
▼▼▼


