QA派|GNN工业应用-PinSAGE

QA派|GNN工业应用-PinSAGE

基本概念
pins是什么意思?
PinSAGE论文中的数据集有多大?
PinSAGE使用的是什么图?
PinSAGE的任务是什么?
PinSAGE有特别区分pin节点和board节点吗?
和GraphSAGE相比,PinSAGE改进了什么?
PinSAGE使用多大的计算资源?
PinSAGE和node2vec、DeepWalk这些有啥区别?
聚合函数
PinSAGE的单层聚合过程是怎样的?
为什么要将邻居节点的聚合embedding和当前节点的拼接?
采样
PinSAGE是如何采样的?
PinSAGE的邻居节点的重要性是如何计算的?
重要性采样的好处是什么?
采样的大小是多少比较好?
MiniBatch
PinSAGE的minibatch和GraphSAGE有啥不一样?
batch应该选多大?
训练
PinSAGE使用什么损失函数?
PinSAGE如何定义标签(正例/负例)?
PinSAGE用什么方法提高模型训练的鲁棒性和收敛性?
负采样
PinSAGE如何进行负采样?
训练时简单地负采样,会有什么问题?
如何解决简单负采样带来的问题?
如果只使用“hard”负样本,会有什么问题?
如何解决只使用“hard”负采样带来的问题?
如何区分采样、负采样、”hard“负采样?
推理
直接为使用训练好的模型产生embedding有啥问题?
如何解决推理时重复计算的问题?
下游任务如何应用PinSAGE产生的embedding?
如何为用户进行个性化推荐?
工程性技巧
pin样本的特征如何构建?
board样本的特征如何构建?
如何使用多GPU并行训练PinSAGE?
PinSAGE为什么要使用生产者-消费者模式?
PinSAGE是如何使用生产者-消费者模式?
基本概念
pins是什么意思?
Pinterest是一个图片素材网站,pins是指图片,而boards则是图片收藏夹的意思。
Pinterest会根据用户的浏览历史来向用户推荐图片。
PinSAGE论文中的数据集有多大?
论文中涉及到的数据为20亿图片(pins),10亿画板(boards),180亿边(pins与boards连接关系)。
用于训练、评估的完整数据集大概有18TB,而完整的输出embedding有4TB。
PinSAGE使用的是什么图?
在论文中,pins集合(用I表示)和boards集合(用C表示)构成了 二分图 ,即pins仅与boards相连接,pins或boards内部无连接。
同时,这二分图可以更加通用:
-
I 可以表示为 样本集 (a set of items), -
C 可以表示为 用户定义的上下文或集合 (a set of user-defined contexts or collections)。
PinSAGE的任务是什么?
利用pin-board 二分图的结构与节点特征 ,为pin生成高质量的embedding用于下游任务,比如pins推荐。
PinSAGE有特别区分pin节点和board节点吗?
没有。PinSAGE并没有明确区分pin节点和board节点。
只使用节点来作为一般指代。
和GraphSAGE相比,PinSAGE改进了什么?
-
采样 :使用重要性采样替代GraphSAGE的均匀采样; -
聚合函数 :聚合函数考虑了边的权重; -
生产者-消费者模式的minibatch构建 :在CPU端采样节点和构建特征,构建计算图;在GPU端在这些子图上进行卷积运算;从而可以低延迟地随机游走构建子图,而不需要把整个图存在显存中。 -
高效的MapReduce推理 :可以分布式地为百万以上的节点生成embedding,最大化地减少重复计算。
这里的计算图,指的是用于卷积运算的局部图(或者叫子图),通过采样来形成;与TensorFlow等框架的计算图不是一个概念。
PinSAGE使用多大的计算资源?
训练时,PinSAGE使用32核CPU、16张Tesla K80显卡、500GB内存;
推理时,MapReduce运行在378个d2.8xlarge Amazon AWS节点的Hadoop2集群。
PinSAGE和node2vec、DeepWalk这些有啥区别?
-
node2vec,DeepWalk是无监督训练;PinSAGE是有监督训练; -
node2vec,DeepWalk不能利用节点特征;PinSAGE可以; -
node2vec,DeepWalk这些模型的参数和节点数呈线性关系,很难应用在超大型的图上。
聚合函数
PinSAGE的单层聚合过程是怎样的?
和GraphSAGE一样,PinSAGE的核心就是一个 局部卷积算子 ,用来学习如何聚合邻居节点信息。
如下图算法1所示,PinSAGE的聚合函数叫做CONVOLVE。
主要分为3部分:
-
聚合 (第1行):k-1层邻居节点的表征经过一层DNN,然后聚合(可以考虑边的权重), 是聚合函数符号,聚合函数可以是max/mean-pooling、加权求和、求平均; -
更新 (第2行): 拼接 第k-1层目标节点的embedding,然后再经过另一层DNN,形成目标节点新的embedding; -
归一化 (第3行): 归一化 目标节点新的embedding,使得训练更加稳定;而且归一化后,使用近似最近邻居搜索的效率更高。

为什么要将邻居节点的聚合embedding和当前节点的拼接?
因为根据T.N Kipf的GCN论文,concat的效果要比直接取平均更好。
采样
PinSAGE是如何采样的?
如何采样这个问题从另一个角度来看就是:如何为目标节点构建邻居节点。
和GraphSAGE的均匀采样不一样的是,PinSAGE使用的是重要性采样。
PinSAGE对邻居节点的定义是:对目标节点 影响力最大 的T个节点。
PinSAGE的邻居节点的重要性是如何计算的?
其影响力的计算方法有以下步骤:
-
从目标节点开始随机游走; -
使用 正则 来计算节点的“访问次数”,得到重要性分数;
目标节点的邻居节点,则是重要性分数最高的前T个节点。
这个重要性分数,其实可以近似看成Personalized PageRank分数。
关于随机游走,可以阅读《Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time》
重要性采样的好处是什么?
-
和GraphSAGE一样,可以使得 邻居节点的数量固定 ,便于控制内存/显存的使用。 -
在聚合邻居节点时,可以考虑节点的重要性;在PinSAGE实践中,使用的就是 加权平均 (weighted-mean),原文把它称作 importance pooling 。
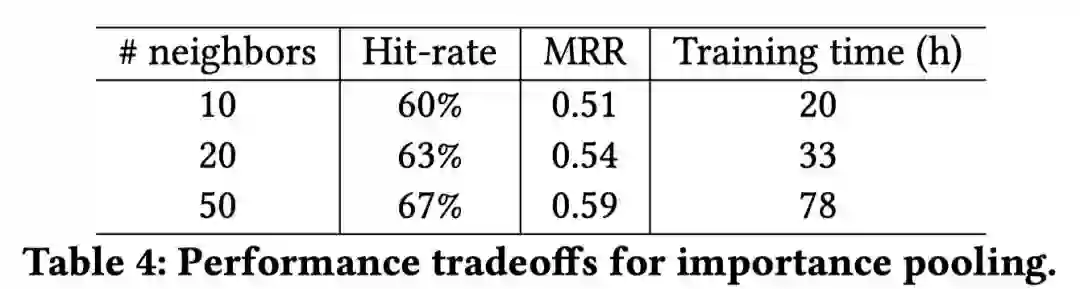
采样的大小是多少比较好?
从PinSAGE的实验可以看出,随着邻居节点的增加,而收益会递减;
并且两层GCN在 邻居数为50 时能够更好的抓取节点的邻居信息,同时保持运算效率。
MiniBatch
PinSAGE的minibatch和GraphSAGE有啥不一样?
基本一致,但细节上有所区别。比如说:
-
GraphSAGE聚合时就更新了embedding; -
PinSAGE则在聚合后需要再经过一层DNN才更新目标embedding(算法2中的15~17行)。

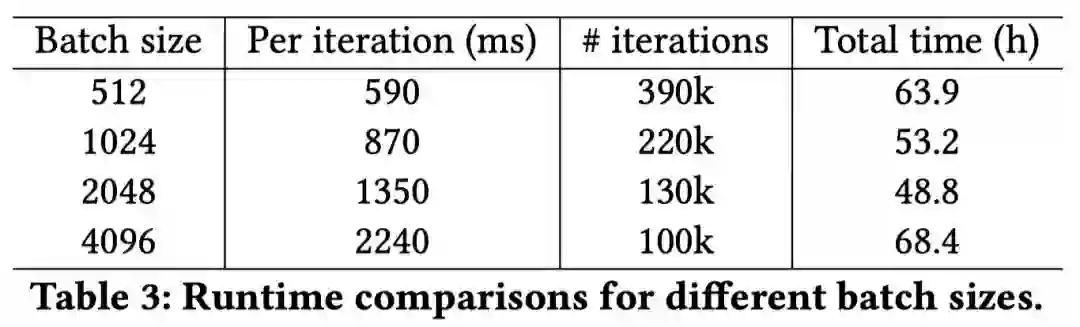
batch应该选多大?
毕竟要在大量的样本上进行训练(有上亿个节点),所以原文里使用的batch比较大,大小为512~4096。
从下面表格可以看到, batch的大小为2048 时,能够在每次迭代时间、迭代次数和总训练时间上取得一个不错的综合性能。
训练
PinSAGE使用什么损失函数?
训练损失使用的是max-margin ranking loss,即 最大化 正例之间的相似性,同时保证与负例之间相似性 小于 正例间的相似性。
其损失函数是:
可以看到:
-
相似度由内积来计算; -
表示样本q的负样本分布 -
:表示超参数-幅度(the margin hyper-parameter)
PinSAGE如何定义标签(正例/负例)?
PinSage中采用的是有监督训练,使用已标注的样本对 (labeled pairs of item),这是假设样本i和样本q有关联性;样本i被认为是点击了样本q后的理想推荐候选项。
正样本来自于用户的历史记录。用户点击了图片q后,立即点击了图片i,这就形成了样本对 。而其他样本则被认为是负样本。
PinSAGE用什么方法提高模型训练的鲁棒性和收敛性?
PinSAGE使用“harder-and-harder”的训练样本来渐进训练,即逐渐提高样本的“区分难度”,使得模型更加鲁棒。
而这个“越来越难”的样本,请看下面的“hard”负样本。
负采样
PinSAGE如何进行负采样?
在每个minibatch包含节点的范围之外随机采样500个样本作为minibatch所有目标项 共享 的负样本集合。
与每个节点单独负采样相比,这样的做法做大大减少了训练时embedding的数量。
实践中,这两种做法在性能上并没有什么显著差异。
训练时简单地负采样,会有什么问题?
在最简单的情况,我们可以从所有的样本中均匀地抽取负样本。
然而这么做,就会使得目标节点与正样本的内积能够 轻松地大于 与这负采样500个样本的内积,这样就没法训练模型了。
在实践中,模型应该在从20亿张图片中能够给出1000张最相关的候选项;也就是说,要从200万张图片中找到1张。
而只是随机负采样500项,该模型的分辨率只有五百分之一(模型分辨的粒度过粗),也就说很大概率无法分辨出最相关项;
如何解决简单负采样带来的问题?
为了解决简单负采样带来的问题,对于每个目标项,PinSAGE为其增加了一种“hard”负样本;
"hard"负采样的项,与目标项相似(比随机负采样相似,因此对模型进行排序更有挑战性,能够使得模型能够以更细颗粒度地区分样本),但与正样本不相关;
"hard"负采样是这样获取的:
-
采样时的随机游走,能够获得每个节点相对 目标节点 的重要性分值,对这些分数进行 排序 ; -
随机选取 一定数量 且 排序位置在2000~5000 的样本作为“hard”负样本;

如果只使用“hard”负样本,会有什么问题?
如果训练全程都使用“hard”负样本,会导致模型收敛速度减半,训练迭代次数加倍。
如何解决只使用“hard”负采样带来的问题?
PinSage采用了一种 Curriculum训练 的方式,这里我理解是一种渐进式训练方法,即:
-
第一轮训练只使用 简单负采样 ,帮助模型参数快速收敛到一个loss比较低的范围; -
后续训练中逐步加入**“hard”负样本**,让模型学会将很相似的样本与略相似的样本区分开;方式是:第n轮训练时给每张图片的负样本集合中增加 n-1 个“hard”负样本。
更多可以阅读ICML 2009的《Curriculum learning》
如何区分采样、负采样、”hard“负采样?
也许会弄混了这三个采样:
-
采样 :通过重要性分数为目标节点选取固定数量的邻居节点; -
负采样 :随机采集正样本之外的样本用作训练的负例; -
“hard”负采样 :为了解决简单负采样导致的模型训练分辨率过低的问题,选取和目标项较为相似但和正样本不相关的样本作为明确的负例;
在PinSAGE中,有12亿个样本对作为训练正例,每个batch有500个全局随机抽取的负例,而每一张图片又有6个“hard”负例。
推理
直接为使用训练好的模型产生embedding有啥问题?
邻居节点的重合,这就导致了计算embedding时必然会有重复的计算。
而且随着邻居的阶数越高,这种重复的概率就越大,则会浪费更多的算力在重复计算上。
如何解决推理时重复计算的问题?
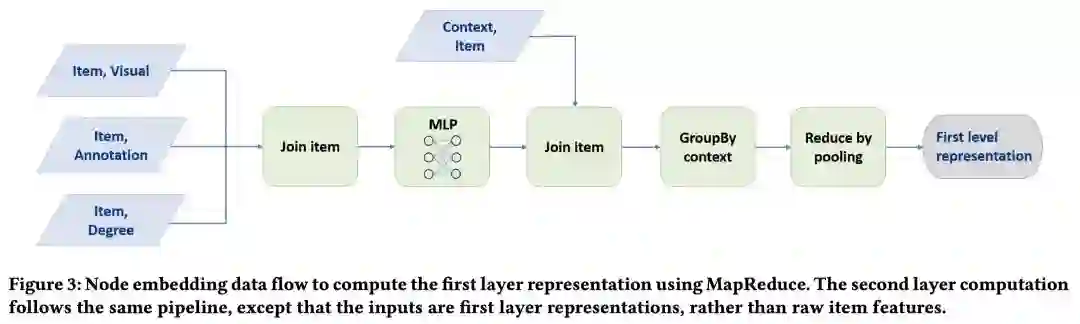
PinSAGE使用一种 MapReduce 的方法来进行模型推理而不需要重复计算。
MapReduce流程有两个关键部分:
-
先把所有的pins映射到一个低维度空间; -
board的embedding是通过pooling其邻居节点(已采样的pins)的特征来获得。
为了避免重复计算,每个节点的向量只计算一次;
board的embedding获得之后,则使用更多的MapReduce任务器来计算第二层pins的embedding,以此类推到更多的层。
因为原文里假设只有Pin有特征,所以聚合层数必须为偶数。
向量最终都会存在数据库中,供下游任务使用。
实验证明,MapReduce方法能够在 不到24小时 的时间内为所有30亿个样本生成embedding。
下游任务如何应用PinSAGE产生的embedding?
在很多情况,可以直接通过 近邻查找 的方法来利用embedding做推荐,也就是给定一个查询目标,我们可以用KNN中前K个项来推荐。
近似KNN可以通过 局部敏感哈希 (locality sensitive hashing)来更有效地进行查询:
-
计算哈希; -
基于Weak AND算子的两层检索过程来检索出候选项。
这样的设置,使得PinSAGE能够实现在线推荐。
如何为用户进行个性化推荐?
PinSAGE把这一任务成为 home/news feed recommendation。
同样是使用近邻查找的方法,但目标查询项是来自 用户最近收藏的图片 。
工程性技巧
pin样本的特征如何构建?
Pinterest的业务场景中,每个pin通常有一张图片和一系列的文字标注(标题,描述等),因此图中每个节点的原始特征表示由下面三种特征拼接而成:
-
图片Embedding (4096维),由VGG-16的第六层全连接层生成; -
文字Embedding (256维),由Word2Vec训练得到; -
pin节点在图中的 度的log值 。
board样本的特征如何构建?
MapReduce部分提到过,board的embedding是通过 pooling其邻居节点 (已采样的pins)的特征来获得。
如何使用多GPU并行训练PinSAGE?
每一个minibatch分成 等大 的部分,每个GPU计算一个minibatch,计算时所有GPU都 共享 相同的参数;
反向传播后,把所有GPU各自的参数的梯度 聚合 起来,然后执行 同步SGD (synchronous SGD)。
为了能够能够在大batch上快速收敛并保证训练和泛化的进度,论文里使用 渐进warmup 的策略:
-
在第一个epoch中从 较小的学习率 开始,一直以 线性方式提高 学习率到峰值; -
然后又以 指数方式减少 学习率。
关于这个策略可以阅读《Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour》。
PinSAGE为什么要使用生产者-消费者模式?
训练过程中,上亿节点的邻接表和特征矩阵都是存在内存里的,然而CONVOLVE的聚合操作却在GPU上执行,从GPU访问内存并不是一个高效的过程。
在PinSAGE中,生成者是指CPU,产生minibatch;消费者是GPU,计算minibatch。
PinSAGE是如何使用生产者-消费者模式?
为了解决GPU访问内存低效的问题,PinSAGE使用一种叫做re-indexing的技术:
-
构建一个子图,这个子图包含当前minibatch的目标节点集和它们的邻居节点; -
这个子图包含的节点的特征会被抽出来,这样就形成了一个比较小的特征矩阵; -
每一次开始一个minibatch迭代时,把子图的邻接表和特征矩阵送进GPU;而CPU则开始处理下一次迭代的计算。
这样的步骤,使得PinSAGE在聚合时没有GPU和CPU之间的数据交换,极大地提高了GPU的使用效率。原文指出这样的做法几乎减少一半的训练时间。
使用多塔训练(multi-tower training)使得GPU计算并行化,而CPU的计算使用OpenMP,它们各自的任务分别是:
-
CPU :负责提取样本特征,re-index,负采样等计算; -
GPU :只负责minibatch的计算。