刚刚智源研究院发布了清源 CPM-中文GPT3-我魔改出了一个TF版本

如果你是一个程序员/技术人员,只想最快跑起来代码,请点击文末阅读原文直接打开REPO:
https://github.com/qhduan/CPM-LM-TF2
下面文章主要分为3个部分,(1)CPM/GPT3介绍;(2)结果例子举例;(3)一些技术向闲聊。
请酌情跳过部分自己没兴趣的章节。
CPM和GPT3的介绍
什么是CPM?
CPM是Chinese Pre-trained Model的简写,清源 CPM 计划将依托智源研究院新建的人工智能算力平台,建立以中文为核心的超大规模预训练模型,进行基于超大规模预训练语言模型的少次学习能力以及多任务迁移能力研究,探索更具通用能力的语言深度理解技术。
项目官网为 https://cpm.baai.ac.cn/ 感谢智源研究院的相关工作和开源贡献。
什么是GPT3?
GPT3是OpenAI设计的一个语言模型(Language Model,LM)的第三个版本。
语言模型可以认为是人类对于语言中词汇概率相关关系的一种研究结果,GPT这类语言模型最简单的理解可以认为是,给出半句话,预测下一个词的概率。
比如说半句话是:“今天的天空好”,后面可能跟着的词可能是“蓝”,句子是“今天的天气好蓝”
也可能是“晴朗”,句子是“今天的天气好晴朗”
但是我们知道这个词不太可能是“火箭”,因为句子“今天的天气好火箭”实在不太像话。
所以基于前面半句话,显然后面是“蓝”和“晴朗”的概率,比“火箭”要高得多。
GPT3能干嘛?
最直接的应用,显然是通过预测下一个词的概率,实现基于语言模型的文字生成,从而不断的生成,组成一个文章。
但是GPT3不局限于此,因为语言的概率本质上也是一种推理。
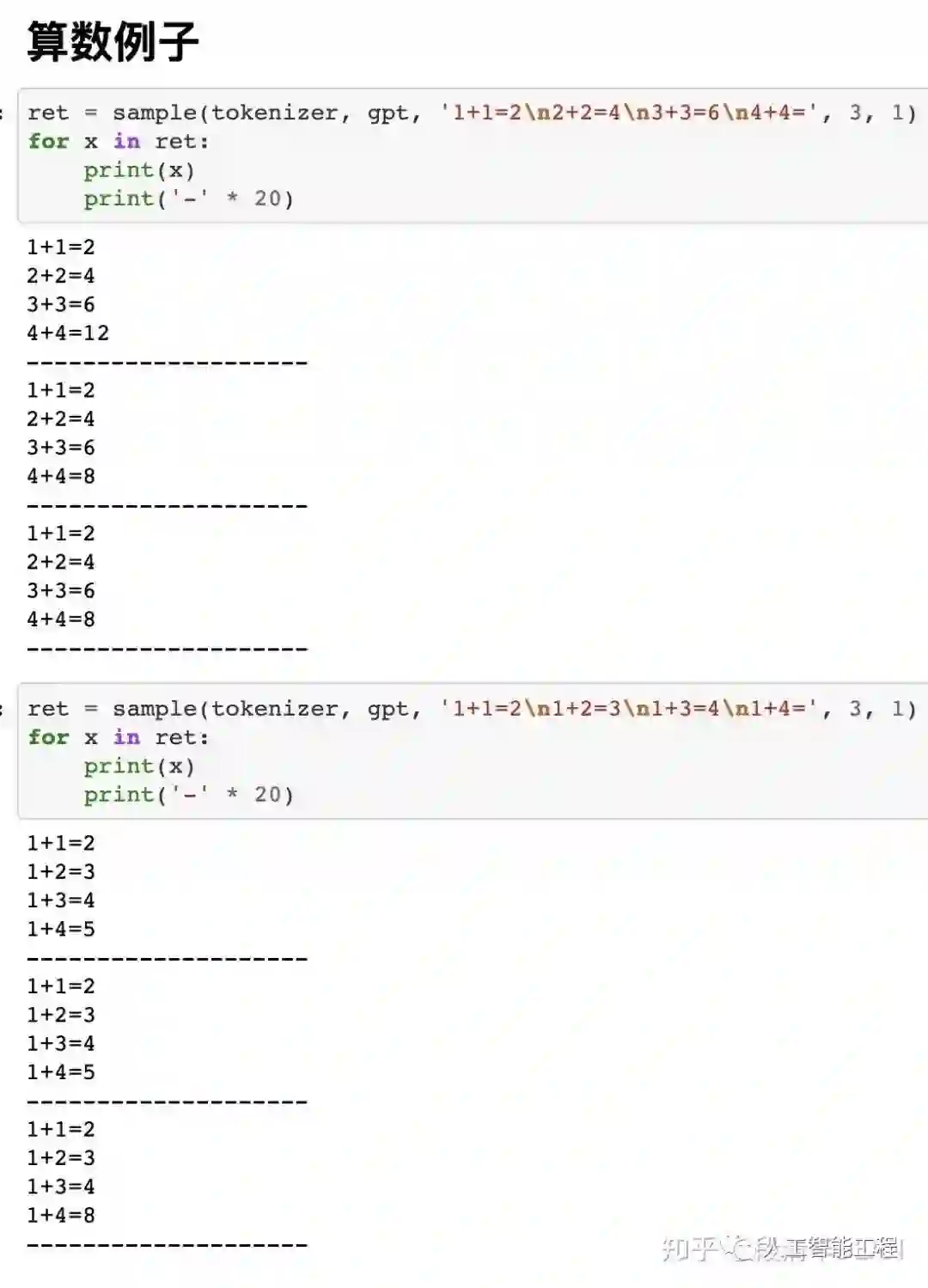
例如前半句话是有一定的逻辑的,例如“一个老师在讲台上说,1+1=2,1+2=3,1+3=4,1+4=”,如果是人继续写下去,或者说继续“生成”下去这句话,那显然下一个词是“5”的概率最大。
其实也同样可以这样,也就是说我们同样喂给GPT3这句话,我们希望它生成的下一个词是“5”的概率最大,理论上来说它能做到的话,就能实现这样的推理。
是的,十以内加减法也是一种推理。
也就是说,假设我们能构造出一些足够信息量的问题,我们就可以让这样的语言模型帮我们回答问题。
当然现在这些模型的效果还不够,它可能会让你觉得AI依然很傻。
但是我们还是应该抱有对于未来的期待,下面我们看一下一些例子。
CPM-LM的结果例子
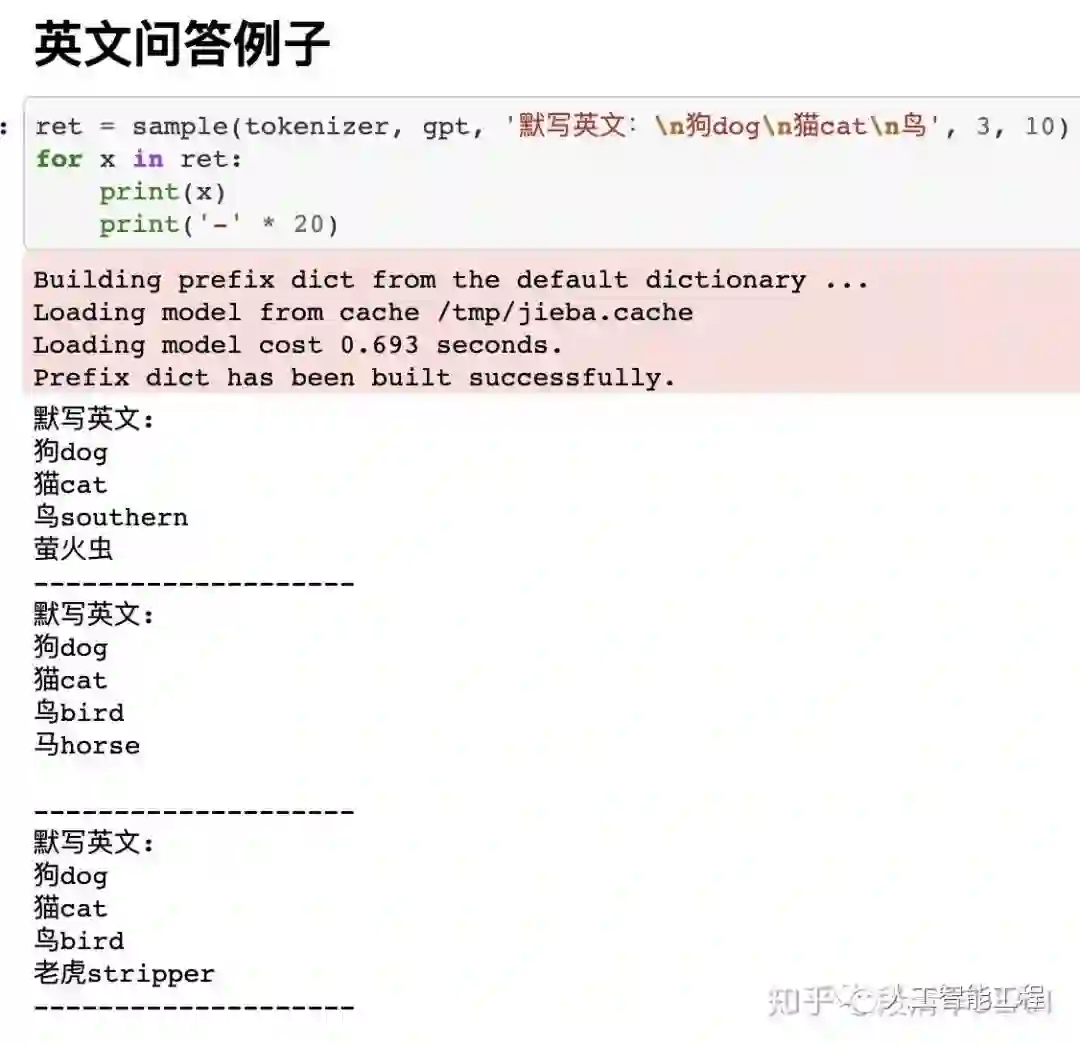
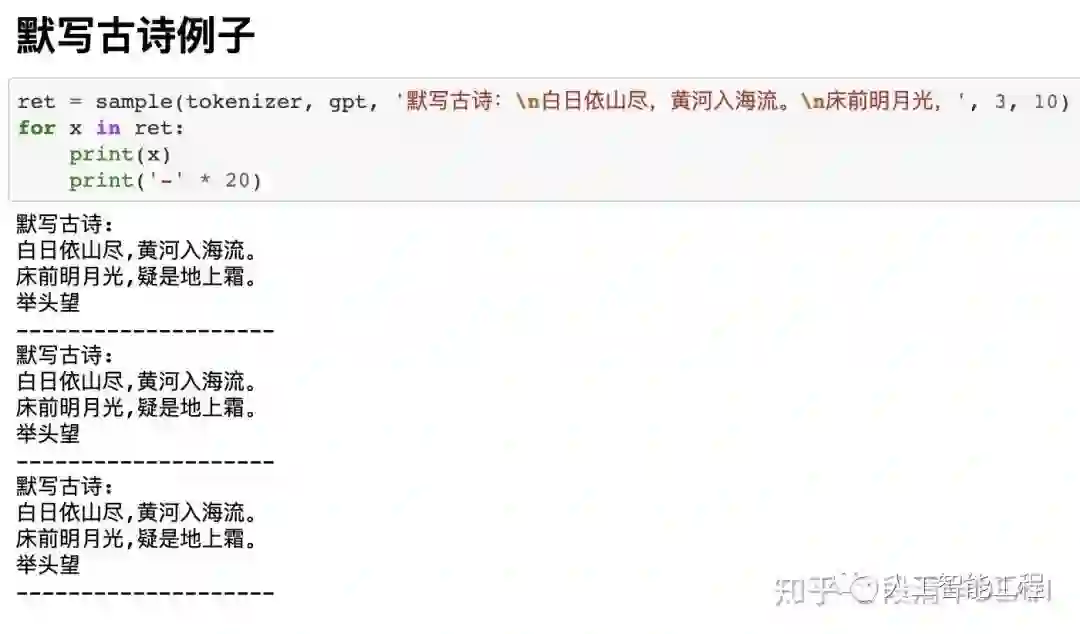
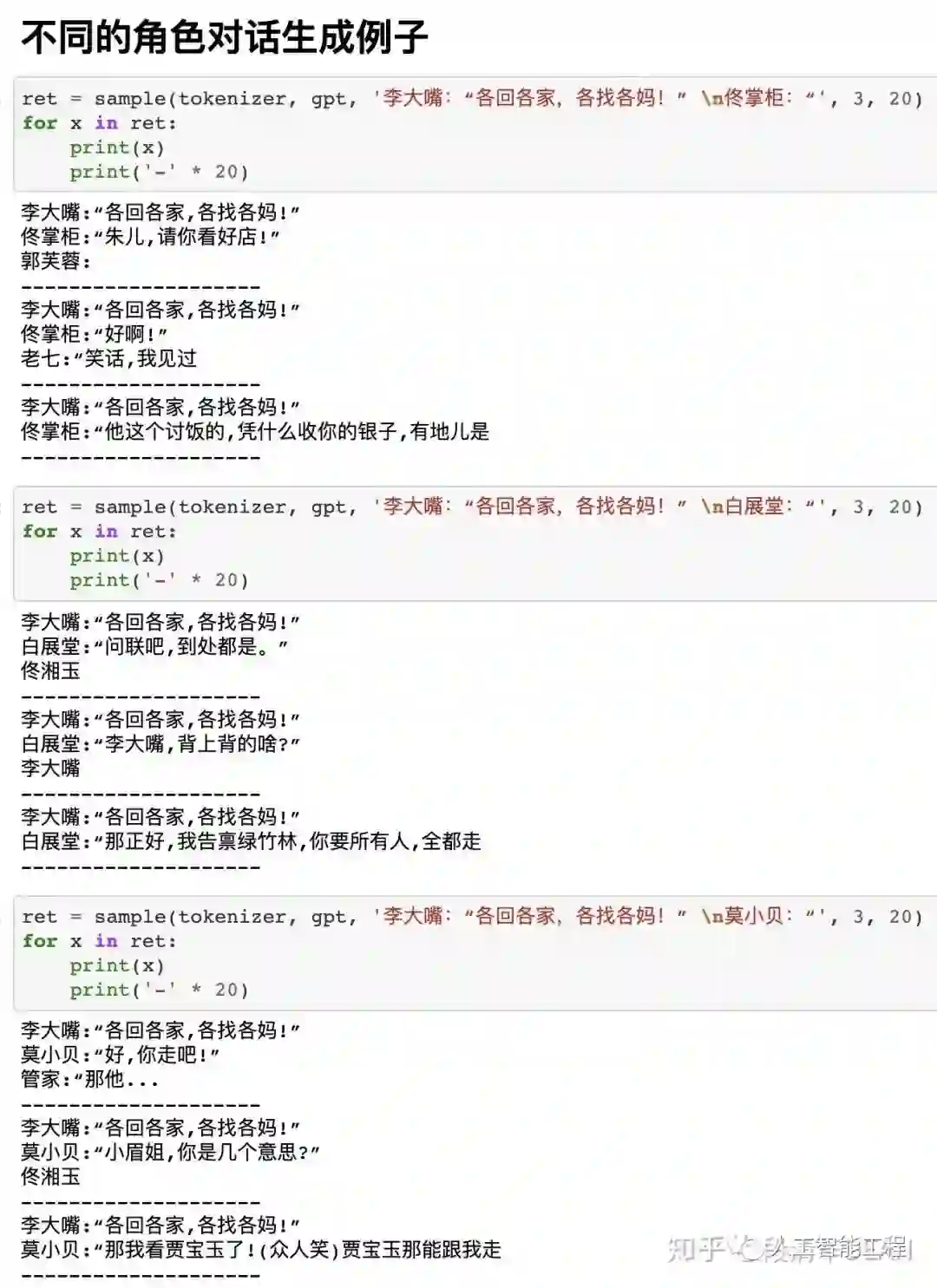
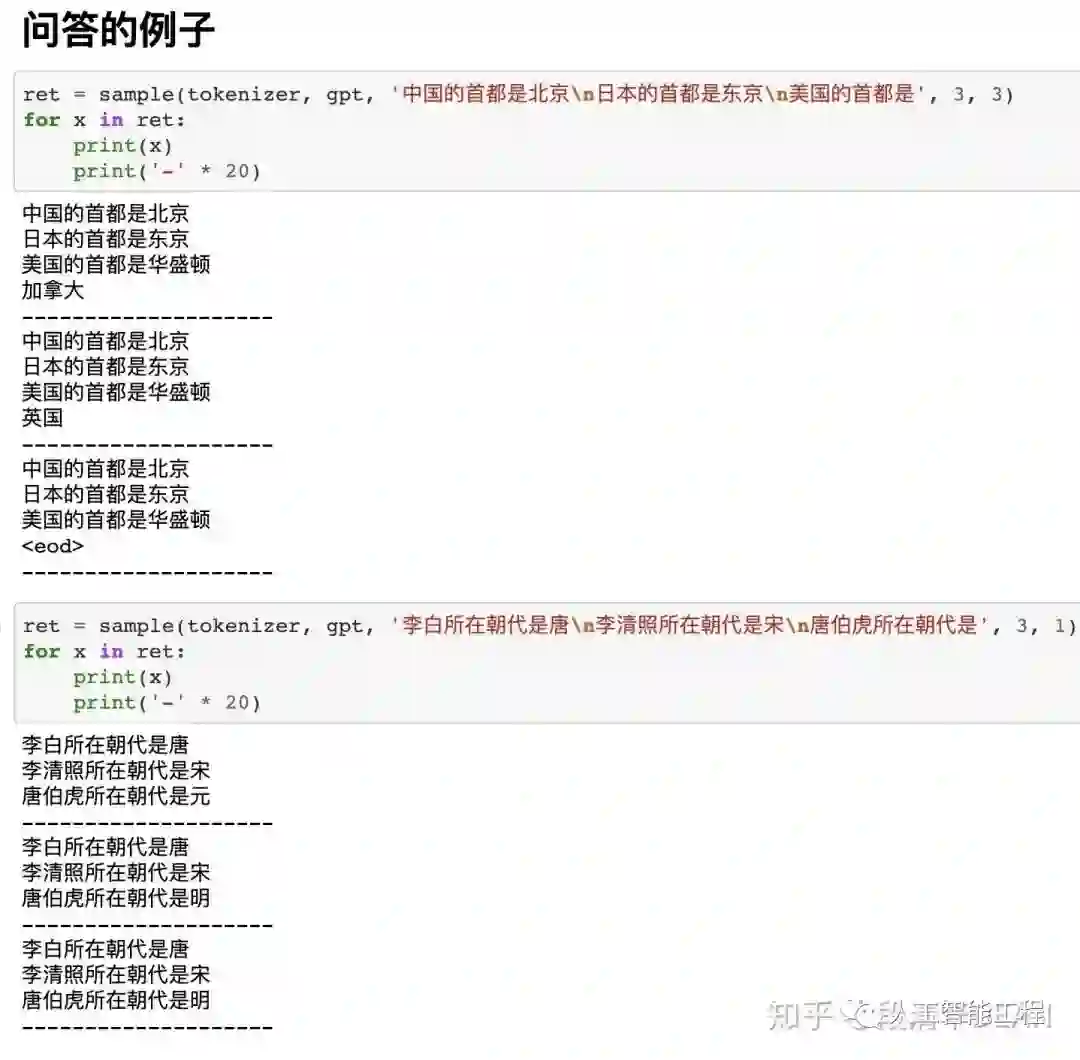
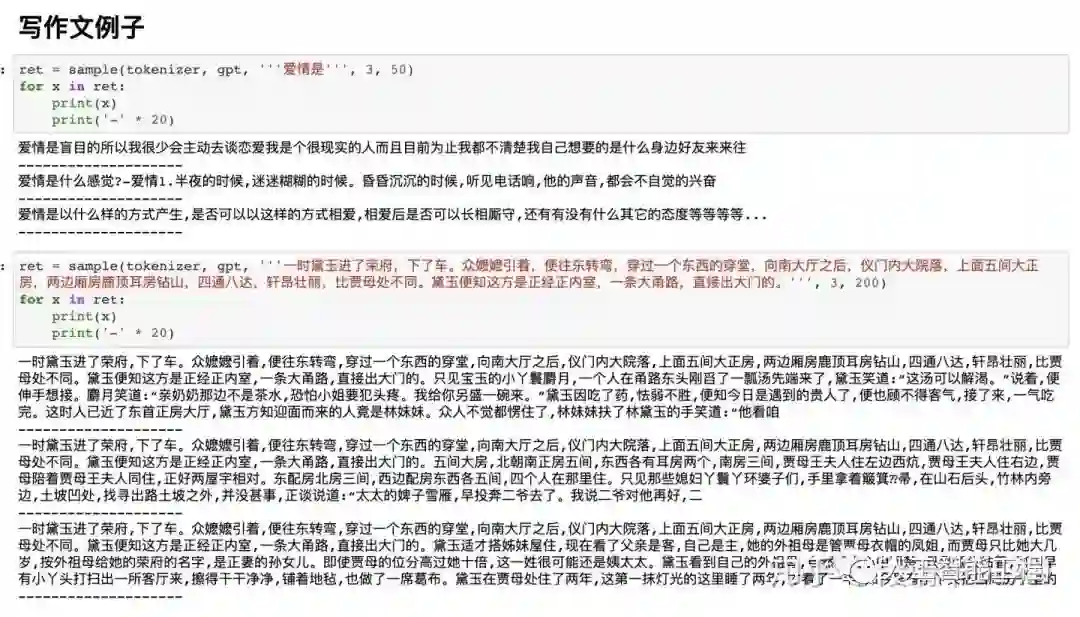
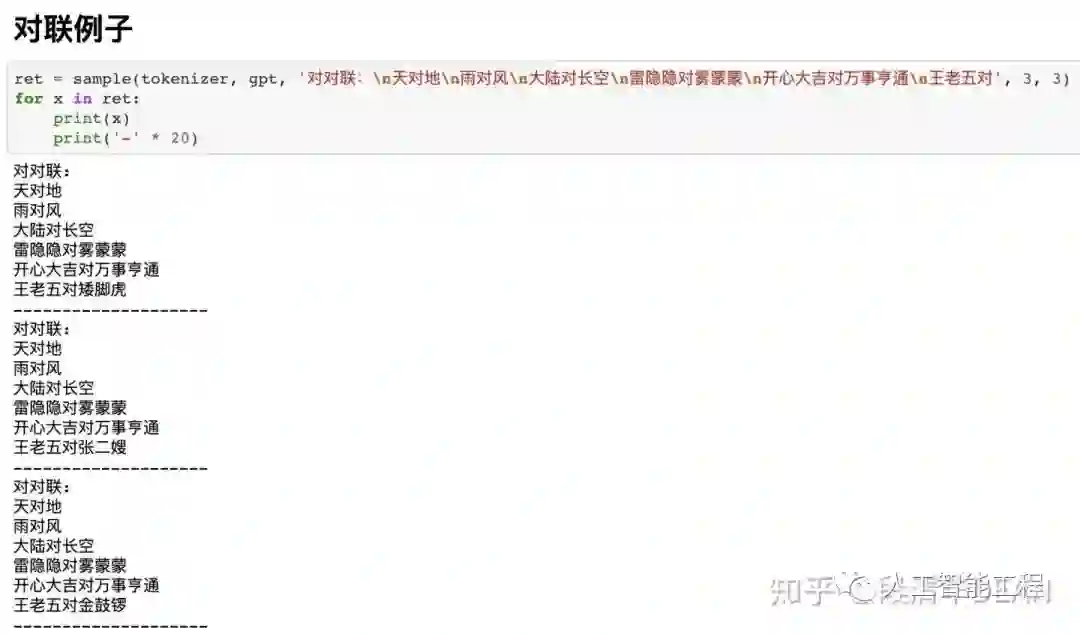
下面图片中,sample(tokenizer, gpt, 'xxxxxxxxxx', 3, 10),这里的'xxxxxxxxx'可以认为是我们构造的“半句话”,每个例子会生成3个结果。
这3个结果没有先后顺序,也就是并不是第一个结果最好。
我们可以做一种概率统计,例如生成300个,而不是3个结果,最后选这300结果中,出现次数最多的那个词或句子作为答案,这样可能更准确一点的接近实际答案。

一些额外的技术闲聊
模型的转换参考
模型的具体转换代码在load_pytorch.ipynb文件中,希望有类似torch to tensorflow的同学可以参考
原模型的一些细节
模型的训练基础是英伟达的github.com/NVIDIA/Megat,这大概算是一个英伟达魔改的PyTorch上的高级API,论文在arxiv.org/pdf/1909.0805。
这个应该主要是为了能把一个很大的模型在很多张显卡上更好的并行训练而设计的,原模型分了两个文件,也提到了需要两张显卡,应该是在每张显卡上分别载入这两个文件。
这两个文件中大概各有一半的模型参数,有些层,例如全连接层(Dense)的参数会平均到两个模型中。
比如一个256到256的Dense层,按道理来说有一个256x256的kernel和一个256的bias,平分之后会在每个文件分别有一个128x256的kernel和一个128的bias。
因为有些层无法平分,例如LayerNormalization层,所以是在两个文件中有重复的。
fp32和fp16
fp16在笔者的CPU上几乎和龟速一样(Macbook Pro 2020),比fp32的慢了好多倍。
猜测这应该是由于现代cpu上实际上不具备物理的fp16运算器导致的,也就是每次进行fp16的前后其实是把fp16转换为了32再运行的,所以非常浪费CPU。
fp16的模型相比fp32的其实是有一些区别的,主要是原来的attention mask的问题,因为1e10这个数字在fp32上是合法的,但是在fp16上是inf,所以笔者把这部分mask的1e10的超参改为了1e4,才跑起来fp16的模型。
TensorFlow版本和原版本的区别
道理来讲应该没有什么太大区别,而且也载入了原来的参数,不过毕竟还是有GPU -> CPU,PyTorch -> TensorFlow这样的转换,所以可能和原模型结果有一定出入,不过笔者估计这个出入不会很大,顶多1%左右。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
阅读至此了,分享、点赞、在看三选一吧🙏


