谷歌大脑提出并发RL算法,机器人也可以「边行动边思考」

新智元报道
新智元报道
来源:arXiv
编辑:雅新
【新智元导读】由谷歌大脑、UC伯克利、X实验室发表在 ICLR 2020 的一篇论文中提出了一种并发RL算法,使机器人能够像人一样「边行动边思考」。该项研究表明,机械手臂在并发模型中抓取速度比在阻塞模型中的速度提高49%。「新智元急聘主笔、高级主任编辑,添加HR微信(Dr-wly)或扫描文末二维码了解详情。」
近年来,尽管深度强化学习(DRL)已经在视频游戏、零和博弈、机器人抓取和操纵任务中取得了成功,但大多数AI算法都使用了阻塞性的「观察-思考-行动」范式。
这个范式是,智能体在「思考」时假定所处的环境保持静态,其行动将在计算的相同状态下执行。这种假设在静态仿真模拟环境中很是适用,而智能体在观察并决定下个动作时,现实环境已然发生了变化。
举个例子,让智能体去接球。我们不可能让球停在半空中,让智能体去观察,做出接球动作的决定后再接球。显然,这种「观察-思考-行动」范式并不能让智能体顺利实现接球这一动作。

最近谷歌大脑与加州大学伯克利分校、X 实验室共同提出一种并发 RL 算法,使机器人能够像人一样「边行动边思考」。
该团队的研究想法是,让智能体去模仿人和动物的行为模型,让其在将来处理问题时更强大,不易发生故障。「思考和行动并行」才能确保智能体在上一个动作完成之后与下一个动作无缝衔接。
为了开发此类并发控制问题的算法框架,研究者将先从连续时间公式开始探索。
通过将现有基于值的深度强化学习算法进行简单的结构扩展,研究团队提出一类新型近似动态规划,并对模拟基准任务和「边行动边思考」的机器人抓取任务进行了评估。
目前,该论文已被 ICLR 2020 接收。

思考与行动并行,机器人真的可以
这项研究将在以下环境中进行强化学习:在受控系统随着时间演变的过程中同时对动作进行采样。也就是说,当机器人在执行当下动作时必须思考下一个动作。
就如同人和动物一样,机器人需要一边行动一边思考。机器人需要在上个动作完成之后紧随下个动作。
下面分别是在仿真环境与真实环境中,机器人抓取任务视图:


该团队的研究目的是:在深度学习中开发可以处理并发环境的算法框架。
研究方式:利用标准强化学习公式(可以让智能体在完成任务后得到奖励),让智能体在多种可能的状态中接收一个状态,并根据策略在可能的动作中选择并决定该执行的动作。
除了前一个动作之外,还有两个额外的特性:动作选择时间和走动向量(VTG),有助于封装并发知识。研究人员将VTG定义为在测量环境状态的瞬间执行的最后一个动作。
并发动作环境获取智能体执行前一个动作时的状态,以及前个动作结束后的状态。在此期间,不管智能体前一个动作是否完成,即便是中断,根据策略也要选择并执行下一个动作。
在并发环境中基于值的深度学习
「并发环境」是什么?
智能体在观察并决定执行下个动作时,其环境发生变化,与智能体「思考」前所观察的环境不同,研究者将其称为「并发环境」。
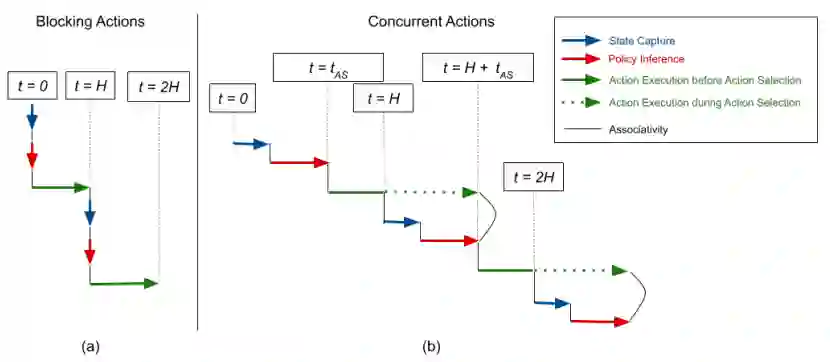
图(a)表示在阻塞环境(blocking environment)中,获取状态与推断策略是瞬间完成的。图(b)中表示的并发环境(concurrent environment)在获取状态与推断策略与动作的执行都是并行的。
接下来,研究人员从连续时间强化学习的角度开始探索,因为它可以容易地表示出系统的并发特征。
之后研究证明,基于连续时间强化学习得出的结论同样适用于随后在所有实验中更为常用的离散环境。
实验表明:并发模型比阻塞模型提高49%
研究人员分别在仿真与机械手臂上进行了实验,它们的任务是抓取并移动垃圾箱中的各种物体。

仿真手臂与机械手臂的实验
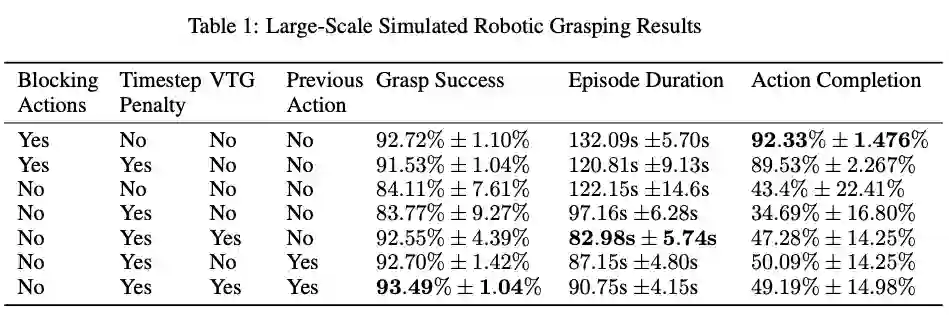
表 1 通过对无条件模型与并发知识模型进行比较总结了阻塞和并发模式的性能。并发知识模型能够学习更快的轨迹,其周期持续时间与阻塞模型相比减少了 31.3%。

研究人员表示,「这些模型在抓取成功方面性能相当,但就策略持续时间(用来衡量策略总执行时间)而言,并发模型比阻塞模型快49%。而且,并发模型能够执行更流利的动作。」
合著者认为,「他们研究的方法可以促进机器人的发展,让机器人在真实环境中完成任务,如在多层仓库和履行中心之间运输材料。」
参考链接:





