今日 Paper | 小样本图像分类;对抗自动增强;语音情感识别;多模态机器翻译等
新年新气象!
为了帮助各位学术青年更好地学习前沿研究成果和技术,AI科技评论联合Paper 研习社(paper.yanxishe.com),重磅推出【今日 Paper】栏目, 每天都为你精选关于人工智能的前沿学术论文供你学习参考。以下是今日的精选内容——
目录
A Baseline for Few-Shot Image Classification
Adversarial AutoAugment
Learning Transferable Features for Speech Emotion Recognition
Job Prediction: From Deep Neural Network Models to Applications
Visual Agreement Regularized Training for Multi-Modal Machine Translation
Effective Data Augmentation with Multi-Domain Learning GANs
WORD REPRESENTATIONS VIA GAUSSIAN EMBEDDING
Evaluation methods for unsupervised word embeddings
Poincaré Embeddings for Learning Hierarchical Representations
Exploring Object Relation in Mean Teacher for Cross-Domain Detection
小样本图像分类的基准
A Baseline for Few-Shot Image Classification
作者:Dhillon Guneet S. /Chaudhari Pratik /Ravichandran Avinash /Soatto Stefano
发表时间:2019/9/6
论文链接:https://paper.yanxishe.com/review/7912
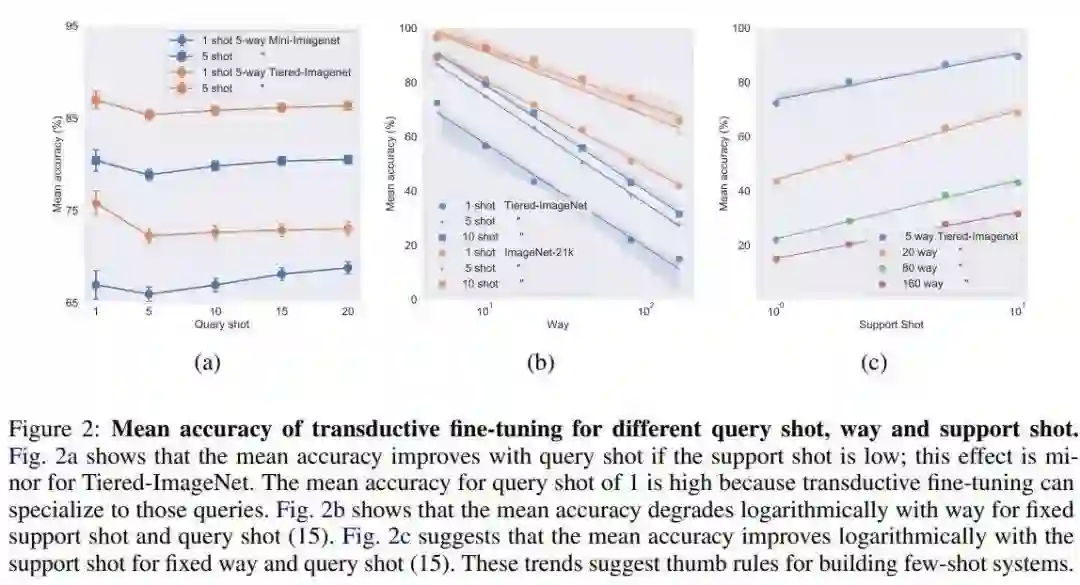
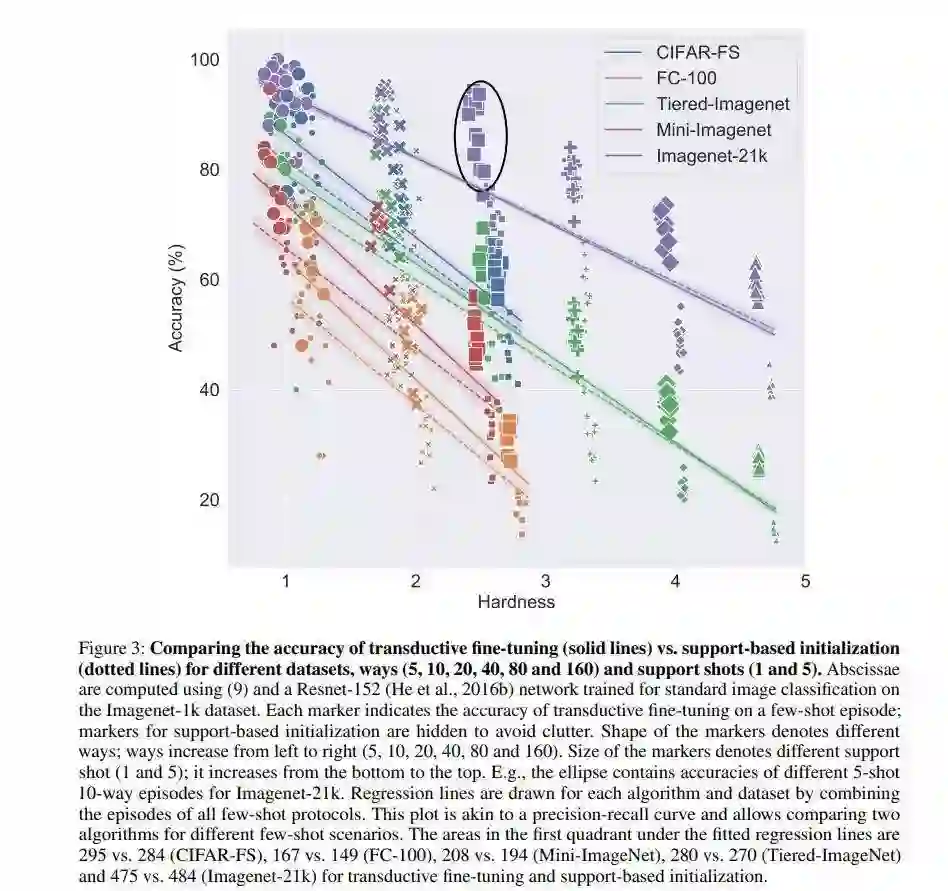
推荐理由:对经过标准交叉熵损失训练的深度网络进行微调是进行小样本学习的一个强基准。如果对它们进行传导性微调,它的性能将优于标准数据集(如Mini-Imagenet,Tiered-Imagenet,CIFAR-FS和FC-100)中具有相同超参数的最新技术。
这种方法的简单性使作者能够在Imagenet-21k数据集上演示最初的几次学习结果。
作者发现使用大量的元训练类,即使对于大量的测试类,也能获得极高的准确率。作者不提倡他们的方法作为小样本学习的解决方案,而只是使用结果突出显示当前基准和小样本学习的局限性。作者对基准数据集进行了广泛的研究,以提出量化测试集“硬度”的指标。此度量标准可用于以更系统的方式说明小样本学习算法的性能。

对抗自动增强
Adversarial AutoAugment
作者:Zhang Xinyu /Wang Qiang /Zhang Jian /Zhong Zhao
发表时间:2019/12/24
论文链接:https://paper.yanxishe.com/review/7897
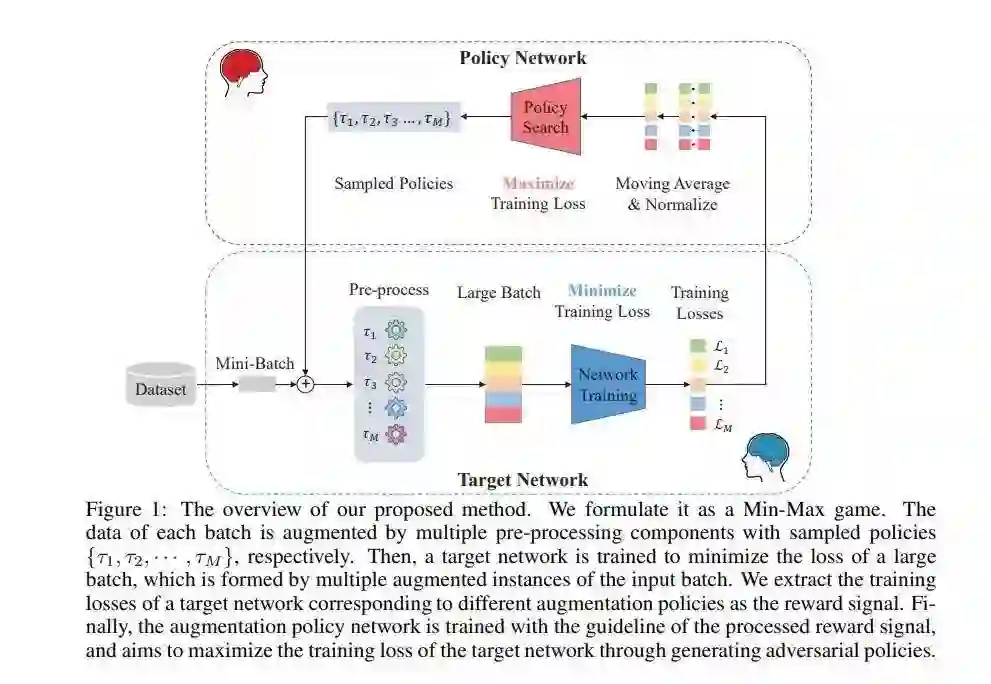
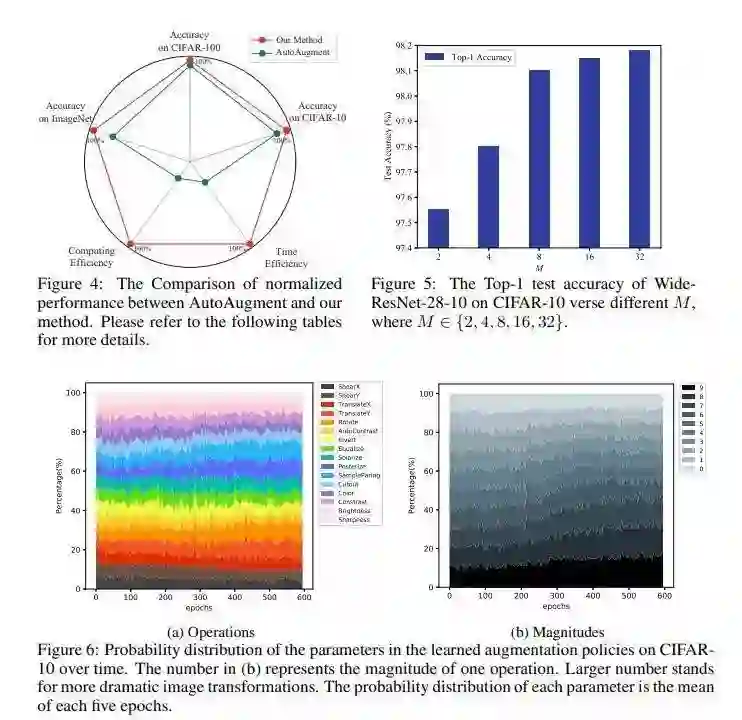
推荐理由:这篇论文要解决的是数据增强的问题。
数据增强被广泛用于深度神经网络训练阶段,用以提高模型的泛化性。近年来,人工设置的数据增强策略逐渐被自动数据增强策略替代。通过在设计好的数据增强搜索空间中发现最佳策略,AutoAugment可以显著提升模型在图像分类任务验证集上的准确率。但是,增强方法由于算力限制并不适合大规模问题。这篇论文提出了一种对抗自动增强方法来满足算力有限的数据增强任务,该方法能同时优化目标相关方程与增强策略搜索损失。增强策略网络尝试通过生成对抗增强策略来增加目标网络的训练损失,而目标网络则能从更难分类的样例中学到更鲁棒的特征来提升泛化性。与先前的工作相反,研究者在目标网络训练过程中重新使用算力以进行策略评估,而无需对目标网络进行再训练。和AutoAugment相比,所提方法在算力消耗上大幅削减。在CIFAR-10/CIFAR-100和ImageNet上的实验结果表明所提方法显著提升了当前的最佳基准。


用于语音情感识别的学习可迁移特征
Learning Transferable Features for Speech Emotion Recognition
作者:Marczewski Alison /Veloso Adriano /Ziviani Nívio
发表时间:2019/12/23
论文链接:https://paper.yanxishe.com/review/7938
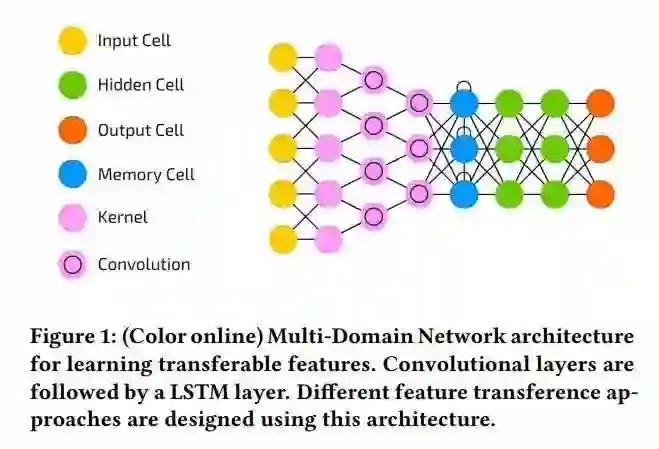
推荐理由:语音情感识别是高级人机交互中获取情感智能的关键步骤之一,识别人类语音中的情感需要建模具有鲁棒性和区分性的特征。这篇论文提出了一种深度模型,该模型利用卷积网络来提取领域共享特征,并使用一个LSTM模型以及领域特定特征来对情感进行分类。考虑到现有语音情感数据十分稀缺,文章使用来源于多个源领域的可迁移特征来进行模型迁移。在针对不同语音情感领域的综合跨语料库实验表明,可迁移特征能够将语音情感识别任务的性能提升4.3%至18.4%。

工作预测:从深度神经网络模型到应用
Job Prediction: From Deep Neural Network Models to Applications
作者:Van Huynh Tin /Van Nguyen Kiet /Nguyen Ngan Luu-Thuy /Nguyen Anh Gia-Tuan
发表时间:2019/12/27
论文链接:https://paper.yanxishe.com/review/7937
推荐理由:这篇论文考虑的是基于简历信息判断工作胜任程度的问题。
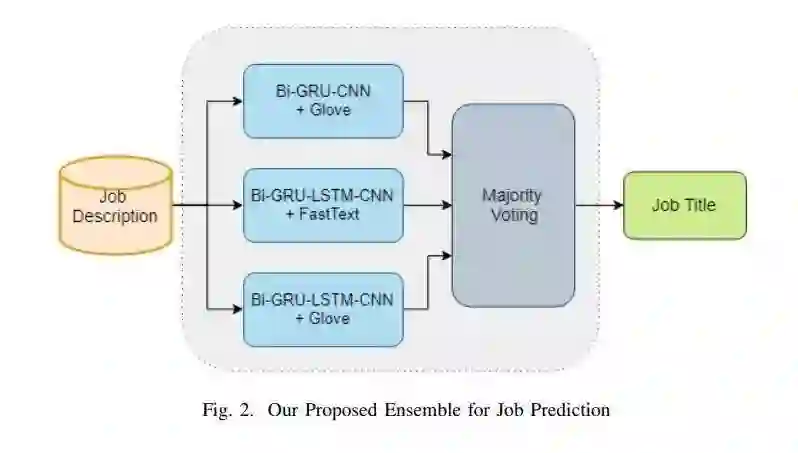
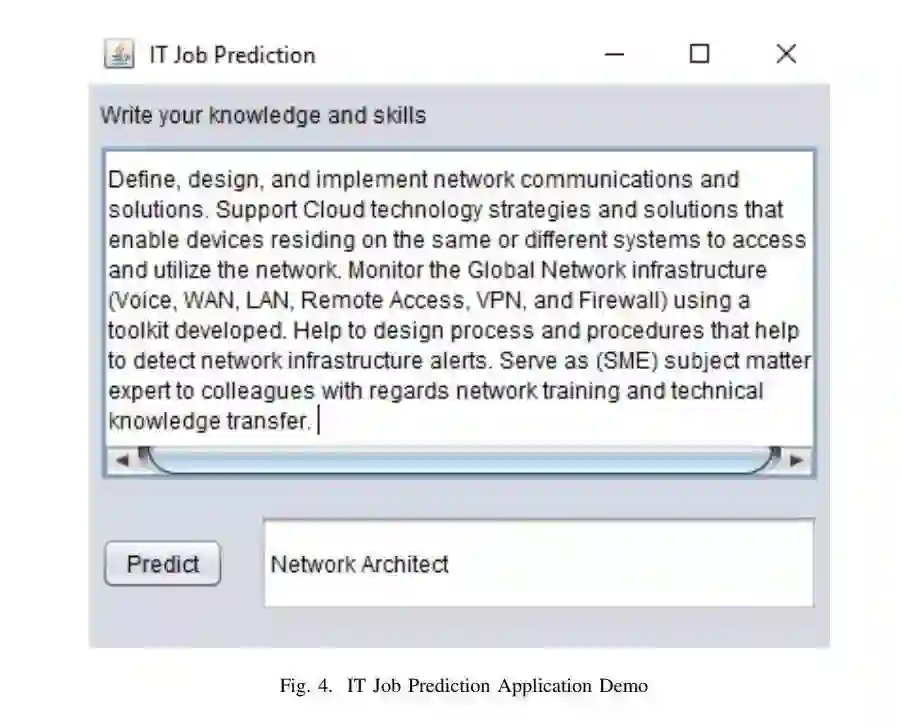
如何根据简历上的信息,例如学历、技能描述等,来判断一份工作是否适合求职者是一个困难的自然语言处理问题。反过来,公司挑选最适合这份工作的人才也是困难的。这篇论文尝试利用不同的深度神经网络模型来学习预测职业,这些模型包括TextCNN,Bi-GRU-LSTM-CNN,以及Bi-GRU-CNN,并用到了基于互联网职业数据集训练的多种预训练词嵌入。这篇论文还提出一种简单但高效的集成模型以包含不同的深度神经网络模型。实验结果表明,所提方法获得了最高为72.71%的F1值。
这篇论文试图利用自然语言处理的技术来帮助互联网上的求职者找到更适合自己的职业发展方向。

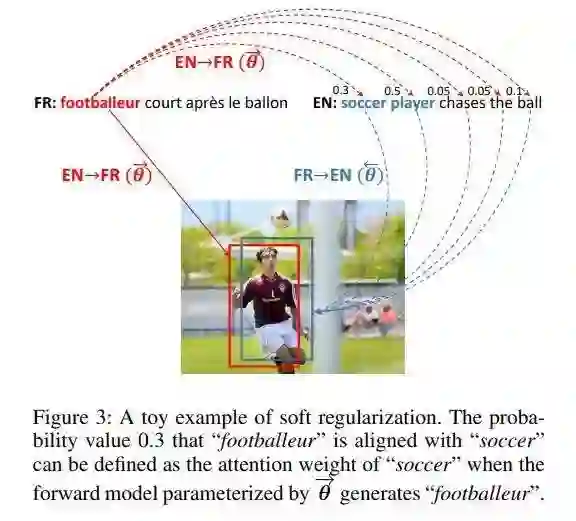
多模态机器翻译的视觉协议正则化训练
Visual Agreement Regularized Training for Multi-Modal Machine Translation
作者:Yang Pengcheng /Chen Boxing /Zhang Pei /Sun Xu
发表时间:2019/12/27
论文链接:https://paper.yanxishe.com/review/7936
推荐理由:多模态机器翻译目标是在配对图像存在时,将源句翻译为另一种不同的语言。之前的研究认为额外的视觉信息仅能为翻译过程提供有限的帮助,只在几种特殊情况下才被用到,例如翻译意思模糊的词。
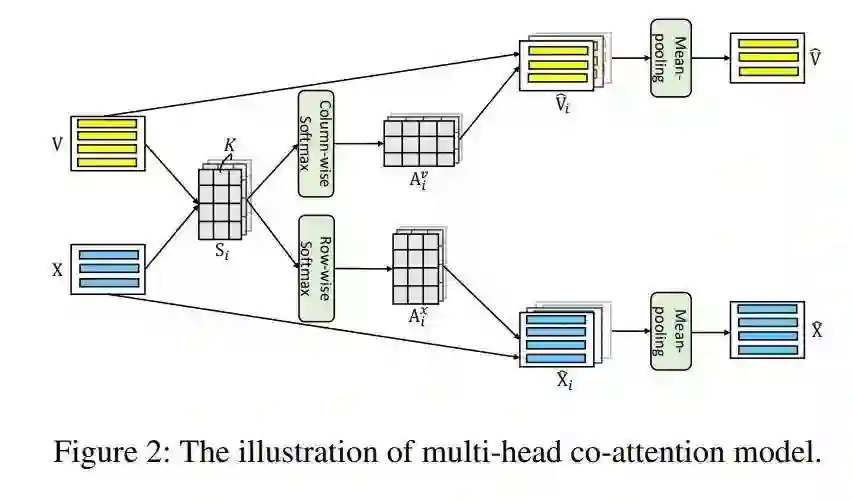
为更好利用视觉信息,这篇论文提出一种视觉一致正则化训练方法。所提方法联合训练源-目标与目标-源的翻译模型,让这些模型在生成语义上等价的视觉词汇时,能共享视觉信息方面同样的焦点,例如英文中的Ball与法文中的Ballon。除此之外,所提方法还使用一个简单但有效的多头交互注意力模型来捕捉视觉与文本特征的交互信息。在Multi30k的实验结果表明所提方法优于基准模型。

拓展阅读
由于篇幅有限,剩余五篇的论文推荐精选请扫描下方二维码继续阅读——
利用多域学习GANs实现有效的数据增强
Effective Data Augmentation with Multi-Domain Learning GANs
基于高斯嵌入的词表示
WORD REPRESENTATIONS VIA GAUSSIAN EMBEDDING
无监督词嵌入的评估方法
Evaluation methods for unsupervised word embeddings
用于学习层次表示的Poincaré嵌入
Poincaré Embeddings for Learning Hierarchical Representations
探索平均教师中的对象关系进行跨域检测
Exploring Object Relation in Mean Teacher for Cross-Domain Detection

(扫码直达,可直接跳转下载论文)




