【SIGIR2021】使用难样本优化向量检索模型
博士生詹靖涛(导师:马少平)为第一作者的长文“Optimizing Dense Retrieval Model Training with Hard Negatives”(作者:詹靖涛,毛佳昕,刘奕群,郭嘉丰,张敏,马少平)。
内容简介:
排序一直是信息检索研究的热点之一。几十年来,关键词匹配(lexical matching)一直主导着检索技术,但它不能考虑语义信号。近年来,随着表示学习的发展,许多研究者转向向量检索(Dense Retrieval)模型以获得更好的排序性能。尽管已有的一些向量检索模型已经取得了很好的结果,其性能的提高很大程度上依赖负采样技术。然而,一些负采样技术效率较低,难以应用到实际中。同时对于为什么一些负采样技术可以提升性能,目前仍然缺乏理论分析。
我们从理论上分析了不同的负采样技术,即随机负采样(random negative sampling)和静态难例负采样(static hard negative sampling)。我们发现这两种负采样技术都存在着不足或风险:前者会导致一些较为困难的查询主导了训练过程,使得模型不能有效地对TopK结果进行排序;后者的优化目标有偏,训练过程不够稳定。我们设计实验验证了理论的分析。
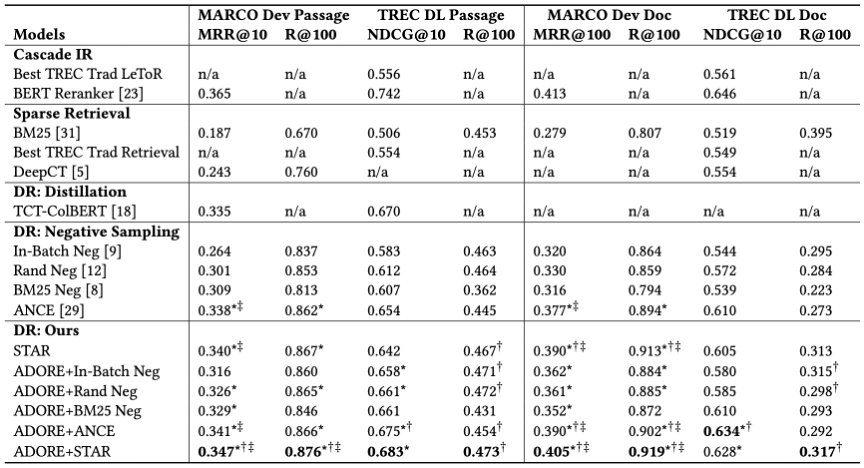
针对这些局限性,本文提出了STAR和ADORE两种新的DR模型训练技术。STAR把静态难负例与随机负例相结合,在优化TopK排序的同时稳定训练。ADORE用动态难负例(dynamic hard negatives)来训练查询编码器,在训练中直接优化排序性能。我们在Benchmark数据集上进行实验。实验结果表明这两种训练策略都十分有效,他们的结合能够得到最佳的排序结果,显著优于强基线。同时这两种训练技术的训练效率也显著优于之前性能较强的基线。
表:TREC DL Track上各模型排序性能的对比
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ODRM” 就可以获取《【SIGIR2021】使用难样本优化向量检索模型》专知下载链接






