基于DGCNN和概率图的轻量级信息抽取模型

作者丨苏剑林
单位丨追一科技
研究方向丨NLP,神经网络
个人主页丨kexue.fm
前几个月,百度举办了“2019语言与智能技术竞赛” [1],其中有三个赛道,而我对其中的“信息抽取”赛道颇感兴趣,于是报名参加。经过两个多月的煎熬,比赛终于结束,并且最终结果已经公布。笔者从最初的对信息抽取的一无所知,经过这次比赛的学习和研究,最终探索出在监督学习下做信息抽取的一些经验,遂在此与大家分享。

▲ 信息抽取赛道:“科学空间队”在最终测试结果上排名第七
笔者在最终的测试集上排名第七,指标 F1 为 0.8807(Precision 是 0.8939,Recall 是 0.8679),跟第一名相差 0.01 左右。从比赛角度这个成绩不算突出,但自认为模型有若干创新之处,比如自行设计的抽取结构、CNN+Attention(所以足够快速)、没有用 Bert 等预训练模型,私以为这对于信息抽取的学术研究和工程应用都有一定的参考价值。
基本分析
信息抽取(Information Extraction, IE)是从自然语言文本中抽取实体、属性、关系及事件等事实类信息的文本处理技术,是信息检索、智能问答、智能对话等人工智能应用的重要基础,一直受到业界的广泛关注。... 本次竞赛将提供业界规模最大的基于 schema 的中文信息抽取数据集(Schema based Knowledge Extraction, SKE),旨在为研究者提供学术交流平台,进一步提升中文信息抽取技术的研究水平,推动相关人工智能应用的发展。
——比赛官方网站介绍
任务介绍
本次的信息抽取任务,更精确地说是“三元组”抽取任务,示例数据如下:
{
"text": "九玄珠是在纵横中文网连载的一部小说,作者是龙马",
"spo_list": [
["九玄珠", "连载网站", "纵横中文网"],
["九玄珠", "作者", "龙马"]
]
}就是输入一个句子,然后输出该句子包含的所有三元组。其中三元组是 (s, p, o) 的形式,它的 s 是 subject,即主实体,为 query 中的一个片段;而 o 是 object,即客实体,也是 query 中的一个片段;而 p 是 predicate,即两个实体之间的关系,比赛事先给出了所有的候选 predicate 列表(schema,一共 50 个候选 predicate)。总的来说,(s, p, o) 可以理解的“s 的 p 是 o”。
比赛给出了将近 20 万的标注数据,标注质量也颇高,感谢百度(据说数据集迟点会在http://ai.baidu.com/broad/download公开发布,到时就可以下载了)。
样本特点
很显然,这是一个“一对多”的抽取+分类任务,通过对人工观察样本情况,发现其特点如下:
1. s 和 o 未必是分词工具分出来的词,因此要对 query 做标注才能抽取出正确的 s、o,而考虑到分词可能切错边界,因此应该使用基于字的输入来标注;
2. 样本中大多数的抽取结果是“一个 s、多个 (p, o)”的形式,比如“《战狼》的主演包括吴京和余男”,那么要抽出“(战狼, 主演, 吴京)”、“(战狼, 主演, 余男)”;
3. 抽取结果是“多个 s、一个 (p, o)”甚至是“多个 s、多个 (p, o)”的样本也占有一定比例,比如“《战狼》、《战狼 2》的主演都是吴京”,那么要抽出“(战狼, 主演, 吴京)”、“(战狼 2, 主演, 吴京)”;
4. 同一对 (s, o) 也可能对应多个 p,比如“《战狼》的主演和导演都是吴京”,那么要抽出“(战狼, 主演, 吴京)”、“(战狼, 导演, 吴京)”;
5. 极端情况下,s、o 之间是可能重叠的,比如“《鲁迅自传》由江苏文艺出版社出版”,严格上来讲,除了要抽出“(鲁迅自传, 出版社, 江苏文艺出版社)”外,还应该抽取出“(鲁迅自传, 作者, 鲁迅)”。
模型设计
在“样本特点”一节我们列举了 5 点基本的观察结果,其中除了第 5 点略显极端外,其余 4 点都是信息抽取任务的常见特点。在正式动手之前,我简单调研了目前主要的信息抽取模型,发现竟然没有一个模型能很好地覆盖这 5 个特点。所以我放弃了已有的抽取思路,自行设计了一个基于概率图思想的抽取方案,然后从效率出发,利用 CNN+Attention 完成了这个模型。
概率图思想
比如,一种比较基准的思路是先进行实体识别,然后对识别出的实体进行关系分类,但这种思路无法很好地处理同一组 (s, o) 对应多个 p 的情况,同时会存在采样效率地的问题。
另一种思路是作为一个整体的序列标注来搞,参考论文 Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme [2],但这种设计不能很好地处理同时有多个 s、多个 o 的情况,需要非常丑陋的“就近原则”;还有“杀鸡用牛刀”地动用强化学习的方法...而无一例外地,这些方法都不能解决 s、o 有重叠的情况。
信息抽取研究了这么多年,居然连上述几个基本问题都没有解决,在我看来是十分不可思议的。而我自己的原则是:不优雅的设计必须抛弃,所以我决定放弃我了解到的所有抽取思路,自行设计一个抽取方案。为此,我考虑到了类似 seq2seq 的概率图思路。
做过 seq2seq 的朋友都知道,解码器实际上在建模:
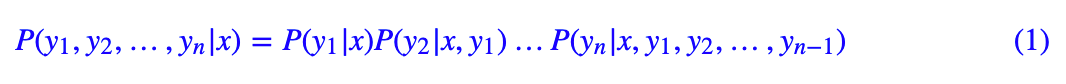
实际预测的时候,是先通过 x 来预测第一个单词,然后假设第一个单词已知来预测第二个单词,依此递推,直到出现结束标记。那抽取三元组为什么不参考这个思路呢?我们考虑:
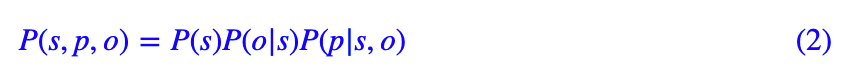
也就是说,我们可以先预测 s,然后传入 s 来预测该 s 对应的 o,然后传入 s、o 来预测所传入的 s、o 的关系 p,实际应用中,我们还可以把 o、p 的预测合并为一步,所以总的步骤只需要两步:先预测 s,然后传入 s 来预测该 s 所对应的 o 及 p。
理论上,上述模型只能抽取单一一个三元组,而为了处理可能由多个 s、多个 o 甚至多个 p 的情况,我们全部使用“半指针-半标注”结构(说白了,将 softmx 换成 sigmoid,在基于CNN的阅读理解式问答模型:DGCNN一文中也介绍过),并且在关系分类的时候也使用 sigmoid 而不是 softmax 激活。
经过这样的设计后,最终的模型可以非常简单高效地解码,并且完全覆盖了“样本特点”列举的 5 个特点。
注 1:为什么不先预测 o 然后再预测 s 及对应的 p?
那是因为引入在第二步预测的时候要采样传入第一步的结果(而且只采样一个),而前面已经分析了,多数样本的 o 的数目比 s 的数目要多,所以我们先预测 s,然后传入 s 再预测 o、p 的时候,对 s 的采样就很容易充分了(因为 s 少),反过来如果要对 o 进行采样就不那么容易充分(因为 o 可能很多)。
带着这个问题继续读下去,读者会更清楚地认识到这一点。
注 2:刷到最近的 arXiv 论文,发现在思想上,本文的这种抽取设计与文章 Entity-Relation Extraction as Multi-Turn Question Answering [3]类似。
整体结构
至此,我们已经用相当长的篇幅说明了模型的抽取思想,即先识别 s,然后传入 s 来同时识别 p 和 o。现在来介绍本文模型整体结构。
为了保证效率,模型使用了 CNN+Attention 的结构(外加了一个短序列的 LSTM,由于序列很短,所以即使是 LSTM 也不影响效率),没有用以慢著称的 Bert 之类的预训练模型。其中 CNN 沿用了之前介绍过的 DGCNN,Attention 是用了 Google 力推的 Self Attention,整体结构示意图如下图。

▲ 本文的信息抽取模型示意图。这里输入句子是“《战狼2》的主演吴京生于1974年”,而要抽出的三元组是“(战狼2, 主演, 吴京)”和“(吴京, 出生日期, 1974年)”
具体来说,模型的处理流程为:
1. 输入字 id 序列,然后通过字词混合 Embedding(具体的混合方式后面再介绍)得到对应的字向量序列,然后加上 Position Embedding;
2. 将得到“字-词-位置 Embedding”输入到 12 层 DGCNN 中进行编码,得到编码后的序列(记为 H);
3. 将 H 传入一层 Self Attention 后,将输出结果与先验特征进行拼接(先验特征可加可不加,构建方式后面再详细介绍);
4. 将拼接后的结果传入 CNN、Dense,用“半指针-半标注”结构预测 s 的首、尾位置;
5. 训练时随机采样一个标注的 s(预测时逐一遍历所有的 s),然后将 H 对应此 s 的子序列传入到一个双向 LSTM 中,得到 s 的编码向量,然后加上相对位置的 Position Embedding,得到一个与输入序列等长的向量序列;
6. 将 H 传入另一层 Self Attention 后,将输出结果与第 5 步输出的向量序列、先验特征进行拼接(先验特征可加可不加,构建方式后面再详细介绍);
7. 将拼接后的结果传入 CNN、Dense,对于每一种 p,都构建一个“半指针-半标注”结构来预测对应的 o 的首、尾位置,这样就同时把 o、p 都预测出来了。
该模型与我早期开源的一个 baseline 模型(https://github.com/bojone/kg-2019-baseline)已有较大区别,望读者知悉。
另外,关于读者的可能有的两个疑惑,在此先回答好了。第一是“为什么第 5 步只采样一个 s?”,这个问题的答案很简单,一是因为采样一个就够了(采样多个等效增大 batch size),二是因为采样一个比较好操作,我建议不明白的读者好好想明白这一步再来读下去。
第二是“为什么要不用Bert?”,这个问题其实很无聊,为什么要问这个问题呢,我不爱用不行吗?具体的原因是我一直以来就对 Bert 没什么好感,所以我也没怎么琢磨 Bert 的 fine tune,直到前不久我才上手了 Bert 的 fine tune,所以比赛中也就没用了。而且基于 Bert 的 fine tune 实在是没有什么意思,效率又低,又体现不了个人的价值,如无必要,实在是不想使用。关于 Bert 的做法,在比赛截止前几天也尝试了一下,后面另写文章分享吧。
模型细节
前面我们已经介绍了模型的设计思想与整体结构,现在我们来看模型的实现细节。
字词混合Embedding
开头部分我们已经说了,为了最大程度上避免边界切分出错,我们应当选择字标注的方式,即以字为基本单位进行输入。不过,单纯的字 Embedding 难以储存有效的语义信息,换句话说,单个字基本上是没有语义的,更为有效地融入语义信息的方案应该是“字词混合 Embedding”。
在本次比赛的模型中,笔者使用了一种自行设计的字词混合方式。
首先,我们输入以字为单位的文本序列,经过一个字 Embedding 层后得到字向量序列;然后将文本分词,通过一个预训练好的 Word2Vec 模型来提取对应的词向量,为了得到跟字向量对齐的词向量序列,我们可以将每个词的词向量重复“词的字数”那么多次;得到对齐的词向量序列后,我们将词向量序列经过一个矩阵变换到跟字向量一样的维度,并将两者。整个过程如下图:
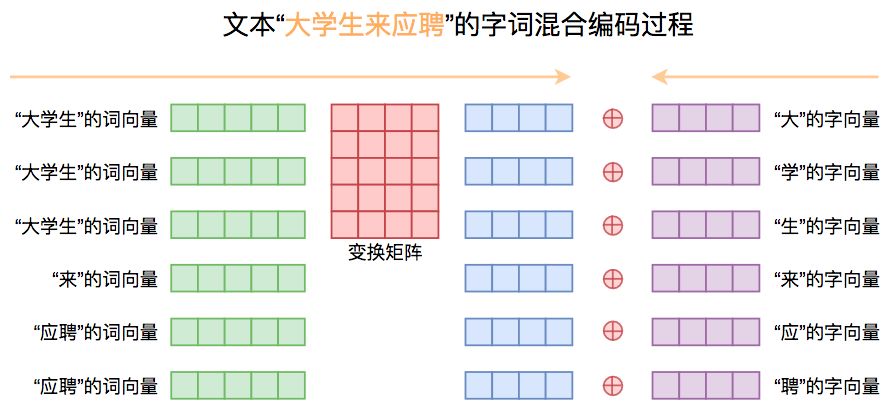
▲ 本模型所使用的字词混合Embedding方式图示
实现上,笔者使用 pyhanlp 作为分词工具,用 1000 万条百度百科词条训练了一个 Word2Vec 模型(Skip Gram + 负采样),而字向量则使用随机初始化的字 Embedding 层。
在模型训练过程中,固定 Word2Vec 词向量不变,只优化变换矩阵和字向量,从另一个角度看也可以认为是我们是通过字向量和变换矩阵对 Word2Vec 的词向量进行微调。这样一来,我们既融合了预训练词向量模型所带来的先验语义信息,又保留了字向量的灵活性。
根据笔者自己的目测,相比单纯使用字向量,这种字词混合的方式能提升最终的效果约 1%~2%,提升是可观的,并且我在其他任务上也实验过这个方案,均有差不多幅度的提升,证明了这种混合方式的有效性。不同的预训练词向量模型对效果会有一定的影响,但不会特别大(千分之五以下),我也试过直接使用腾讯 AI LAB 所提供的词向量 [4](但只用了前 100 万个词),结果差不多。
Position Embedding
由于主要使用 CNN+Attention 进行编码,所以编码出的向量序列“位置感”不够强,但就本次比赛的数据而言,位置信息是有一定的价值的,比如 s 通常出现在句子开头部分,又比如 o 通常出现在 s 附近。加入位置信息的一个有效信息是 Position Embedding,而不同于之前所介绍的由公式直接计算而来的 Position Embedding,本次模型使用了可优化的 Position Embedding。
具体做法是设定一个最大长度为 512(印象中所有样本的句子长度不超过 300),然后全零初始化一个新的 Embedding 层(维度跟字向量维度一样),传入位置 ID 后输出对应的 Position Embedding,并把这个 Position Embedding 加到前面的字词混合 Embedding 中,作为完整的 Embedding 结果,传入到下述 DGCNN 编码中。
模型另一处用到了 Position Embedding 是在编码 s 的时候,采样得到的 s 经过 BiLSTM 进行编码后,得到一个固定大小的向量,然后我们将它复制拼接到原来的编码序列中,作为预测 o、p 的条件之一。
不过考虑到 o 更可能是 s 附近的词,所以笔者并非直接统一复制,而是复制同时还加上了当前位置相对于 s 所谓位置的“相对位置向量”(如果对此描述还感觉模糊,请直接阅读源码),它跟开头的输入共用同一个 Embedding 层。
DGCNN
DGCNN 在之前的基于CNN的阅读理解式问答模型:DGCNN一文已经介绍过,是笔者之前做阅读理解模型时所提出的设计,它其实就是“膨胀门卷积”,其中门卷积的概念来自 Convolutional Sequence to Sequence Learning [5],在那论文中被称为 GLU (Gated Linear Units),然后笔者通过把普通卷积换成了膨胀卷积来增加感受野。类似的做法出现在论文 Fast Reading Comprehension with ConvNets [6]。
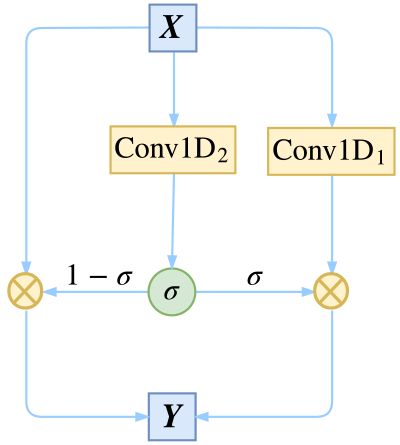
▲ 残差与门卷积的结合,达到多通道传输的效果
当输入输出维度一样时,DGCNN 可以加上残差,而之前笔者就证明了加上残差之后的 DGCNN 在数学上等价于 Highway 形式的膨胀卷积:
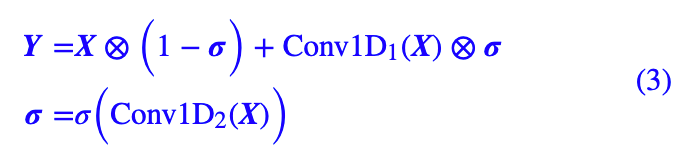
本次模型都是使用这种形式的 DGCNN,它体现了信息的选择性多通道传输。
最后的模型共使用了 12 层 DGCNN,膨胀率依次为 [1,2,5,1,2,5,1,2,5,1,1,1],即 [1,2,5] 重复三次(颗粒度从细到粗反复学习),然后 [1,1,1](细颗粒度精调)。
远程监督的先验特征
本次比赛不允许使用额外的三元组知识库,但是我们可以将训练集里边所有的三元组整合成一个知识库,然后面对一个新句子时,直接从这个知识库中进行远程监督式的搜索,得到这个句子的一些候选三元组。
所谓远程监督,就是指如果一个句子的某两个实体刚好是知识库的某个三元组的 s 和 o,那么就把这个三元组抽取出来作为候选三元组。这样一来,只要有一个知识库,那么我们可以用纯粹检索的方法来抽出任意一个句子的候选三元组。不过要注意的是,这仅仅是候选的三元组,而且有可能抽取出来的三元组全是错的。
对于远程监督的结果,笔者的使用方法是:将远程监督的结果作为特征传入到模型中。首先,将所有远程监督得到的 s 构成一个跟标注结构类似的 0/1 向量,然后拼接到编码向量序列,然后再进行 s 的预测;然后将所有远程监督得到的 o 及对应的 p 也构成一个跟标注结构类似的 0/1 向量,拼接到编码向量序列后再进行 o、p 的预测。具体实现方法请参考开源代码。
要提醒的是,在训练的时候,构建远程监督特征时要先排除当前训练样本自身的三元组,即只能借助其他样本的三元组来生成当前样本的远程监督结果,这样才能模拟测试集的使用情况。
效果上,加入远程监督的先验特征后,模型在线下验证集的提升非常可观,达到了 2% 以上!并且已经反复确认,代码中不存在“使用未来信息”的漏洞,也就是说,这个线下结果是合理的。但是非常遗憾,线上测试集的结果却跟没有加先验特征差不多,也就是几乎没有提升。但是通过观测发现加不加先验特征给出来的结果差异是比较大的,所以最后将两者的结果进行融合了。
其他补充内容
在我的代码实现中,还包括了一些额外的辅助模块,包括代码中的变量 pn1、pn2、pc、po,这些模块从理论上提供了一些“全局信息”,pn1、pn2 可以认为是全局的实体识别模块,而 pc 可以认为是全局的关系检测模块,po 可以认为是全局的关系存在性判断,这些模块都不单独训练,而是直接乘到 s、o 的预测结果上。
这些模型基本上不会影响最终的效果,但能起到加速训练的作用,而且个人直觉上感觉加上这些模块可能会更合理一些。
此外,还有前面提到随机采样 s 后,将 s 对应的向量序列传入到 BiLSTM 中编码,实现的时候有所差别,是通过 s 的首尾 id 均匀插值后取出 s 的固定数目个(模型选了 6 个)向量来构成一个定长向量序列传入到 BiLSTM 中编码,这样做主要是为了避免处理 s 不定长的问题。
实验炼丹
最后,介绍一些模型训练过程中的细节问题。
模型代码:https://github.com/bojone/kg-2019
代码测试环境是 Python 2.7 + Keras 2.2.4 + Tensorflow 1.8。
如果本文的模型对你的后续工作有帮助,烦请注明一下(其实也不是太奢望):
@misc{
jianlin2019bdkgf,
title={A Hierachical Relation Extraction Model with Pointer-Tagging Hybrid Structure},
author={Jianlin Su},
year={2019},
publisher={GitHub},
howpublished={\url{https://github.com/bojone/kg-2019}},
}基本的训练过程
首先是损失函数的选择,由于“半指针-半标注”实际上就是两个二分类,所以损失函数依然用二分类交叉熵。注意 s 的预测只有两个 2 分类,而预测 o 的同时还预测了 p,所以 o 的预测实际上有 100=50×2 个 2 分类,但它们的损失函数依然按照 1:1 相加。
换句话说,按照 loss 的绝对值来看,o 的 loss 是 s 的 loss 的 50 倍。乍看之下有点反直觉,因为先预测 s 然后再预测 o,似乎 s 的权重应该更大(因为如果 s 错了那么预测结果肯定错),但实验结果表明 s、o 同样重要。此外,诸如 focal loss 之类的交叉熵变种对最终结果的提升并没有帮助。
模型使用 Adam 优化器进行训练,先用的学习率训练不超过 50 个 epoch,然后加载训练的最优结果,再用
的学习率继续训练到最优。第一个 epoch 用来 WarmUp,如果不进行 WarmUp 可能不收敛。
为了保证训练结果稳定提升,模型用到了 EMA(Exponential Moving Average),衰减率为 0.9999。
解码过程调优
模型的解码过程有比较大的调优空间。“半指针-半编码结构”用两个 sigmoid 激活的标注方式来分别标注实体的首和尾,而为了解码就需要一个阈值,即超过多少阈值就认为此处出现了实体。一般来说二分类的阈值为 0.5,但在本次模型中,发现将“首”的阈值设为 0.5,将“尾”的阈值设为 0.4,解码结果的 F1 最佳。
此外,这次比较的测试集有一个特点,就是测试集的质量非常高,即抽取结果错漏很少而且很规范。相比之下,训练集的错漏相对多一些,而且规范性可能也没那么严格。所以,我们需要通过后期规则调整预测结果来满足官方给出的一些规范性。
在比赛截止日期的前几天,各个队伍的提升都非常明显,我估计大家都是在不断地找规则来修正预测结果,从而提升的效果,笔者个人也是通过一些规则获得了将近 1% 的提升!不过这些纯粹是比赛的 trick,不在学术范围内,不做过多讨论。
模型平均与融合
模型的 ensemble 是提升最终效果的有力方法,针对本次任务,笔者使用了分层 ensemble 的方案。
前面已经说过,加不加先验特征的线上效果都差不多,但是结果文件差异性比较大,为此,可以将两个模型的结果取并集,而在取并集之前,则通过模型平均的方法提高单一模型的准确性。
具体来说,先不加先验特征,然后将所有数据随机打乱并且分成 8 份,做 8 折的交叉验证,从而得到 8 个不加先验特征的模型;然后加上先验特征重做一次,得到另外 8 个加上先验特征的模型。
得到这 16 个模型后,将不加先验特征的 8 个模型进行平均融合(如下图,即将输出的概率进行平均,然后再解码出三元组),再将加了先验特征的 8 个模型进行平均融合,这样一共得到两份结果文件,由于进行了平均融合,可以认为这两份结果文件的精度都有了保证,最后,将这两份结果文件取并集。
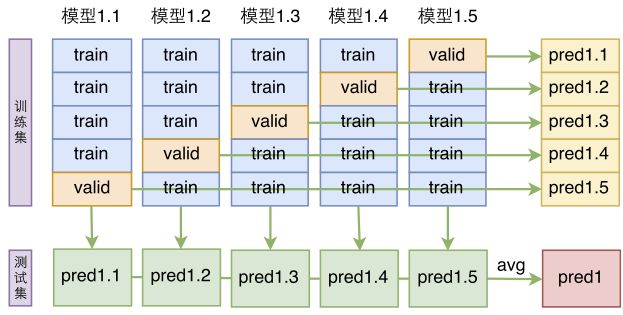
▲ 基于交叉验证的单模型融合
知识蒸馏
前面已经说过,测试集可以认为是非常完美的,而训练集却是有一定缺漏和不规范的(当然大部分是好的),因此,我们使用了一种类似知识蒸馏的方式来重新整理训练集,改善训练集质量。
首先,我们使用原始训练集加交叉验证的方式,得到了 8 个模型(不加远程监督特征),然后用这 8 个模型对训练集进行预测,得到关于训练集的 8 份预测结果。
如果某个样本的某个三元组同时出现在 8 份预测结果中但没有出现在训练集的标注中,那么就将这个三元组补充到该样本的标注结果中;如果某个样本的某个三元组在 8 份预测结果中都没有出现但却被训练集标注了,那么将这个三元组从该样本的标注结果中去掉。
这样一增一减之后,训练集就会完善很多,用这个修正后的训练集重新训练和融合模型,能在线上的测试集上获得将近 1% 的提升。当然不排除删减这一步会错误地去掉一些困难样本的标注结果,但是也无妨了,知识蒸馏的意思就是集中火力攻克主要矛盾。
提升效率的策略
“高效”是本模型的一个显著特点,哪怕是前述的共 16 个模型进行 ensemble,完成最后测试集(共约 10 万个样本)的预测只花了 4 个小时(如果服务器的 CPU 更好些,可以缩短到 2 小时左右),而在比赛群里讨论知道,最后的测试集预测很多队伍都花了十几个小时以上,有些队伍甚至花了几天几夜。
当然,效率的追求是无止境的,除了硬件上的升级,在工程上很多时候我们还可以牺牲一点效果来换取更高的速度。对于本模型,可以化简某些模块,来换取速度的大幅度提升。
比如,可以将 12 层 DGCNN 改为膨胀率依次为 [1,2,5,1,2,5] 的六层。还有,前面介绍编码 s 用了 BiLSTM,其实也可以直接将 s 的首位和末位对应的编码向量拼接起来作为最终的编码结果,省去了 BiLSTM 的计算量。
此外,还可以考虑减少 Word2Vec 模型的词汇量,这也能提高生成词向量序列的速度,如果愿意放弃更多的精度,那么也可以考虑去掉字词混合 Embedding,直接单纯使用字 Embedding。
经过这样处理,模型的速度可以提升 5 倍以上,而性能下降大概是 2%~4% 左右,具体幅度取决于你怎么取舍了。
文章总结
文章用比较长的篇幅记录了笔者参加这次比赛的模型和炼丹经历。
在参加比赛之前,笔者对信息抽取乃至知识图谱领域基本上是处于一无所知状态,所以参加这个比赛的时候,完全是凭着自己的直觉来设计模型且调参的(当然也有一部分原因是经过调研后发现主流的信息抽取模型都不能让我满意)。所以,最终交出的这份答卷和获得的成绩,是我比较满意的结果了。
当然,本文的模型有不少“闭门造车”之处,如果读者觉得有什么不妥的地方,欢迎大力吐槽。即便是在这个比赛之后,在信息抽取、知识图谱这一块,笔者依然还算是一个新手,望相关前辈们多多指教。
相关链接
[1] http://lic2019.ccf.org.cn/
[2] Suncong Zheng, Feng Wang, Hongyun Bao, Yuexing Hao, Peng Zhou, Bo Xu. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. ACL 2017.
[3] Xiaoya Li, Fan Yin, Zijun Sun, Xiayu Li, Arianna Yuan, Duo Chai, Mingxin Zhou, Jiwei Li. Entity-Relation Extraction as Multi-Turn Question Answering. ACL 2019.
[4] https://ai.tencent.com/ailab/nlp/embedding.html
[5] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, Yann N. Dauphin. Convolutional Sequence to Sequence Learning. arXiv: 1705.03122.
[6] Felix Wu, Ni Lao, John Blitzer, Guandao Yang, Kilian Weinberger. Fast Reading Comprehension with ConvNets. ICLR 2018.

点击以下标题查看作者其他文章:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客




