单目深度估计方法:现状与前瞻
点击中国图象图形学报→主页右上角菜单栏→设为星标


难忘的新年,特别的假期,有人在奋战,有人在坚守!在举国抗疫、同舟共济的今天,我们比任何时候都更深切地感受到科学的力量,知识的宝贵。让我们努力学习、潜心钻研,不仅是为了充实自己,更是为了让科研造福人民,服务国家。
少出门、多读书,也是支持,也有贡献!图图今天为大家推荐的是《中国图象图形学报》2019年第12期论文《单目深度估计技术进展综述》,该文由中国图象图形学学会成像探测与感知专委会组织,北京理工大学刘越教授等学者撰写,对国内外2009—2019年机器学习方法的单幅图像深度估计进行了集中论述。

题目:单目深度估计技术进展综述
作者:黄军,王聪,刘越,毕天腾
单位:中国图象图形学学会成像探测与感知专委会
关键词:机器学习;深度估计;3维重建;深度学习
来源:中国图象图形学报, 24(12): 2081-2097
全文链接:http://www.cjig.cn/html/jig/2019/12/weixin/20191202.htm

单目深度估计是从单幅RGB图像中估计深度的方法,是计算机视觉领域近年来热门的研究课题。从数学上讲,该问题是一个病态问题,其原因在于单幅RGB图像对应的真实场景可能有无数个,而图像中没有稳定的线索来约束这些可能性。
基于RGB图像与深度图之间存在着某种映射关系这一基本假设,研究者提出了诸多数据驱动的机器学习的单目深度估计方法。
回顾单幅图像深度估计技术的相关工作
介绍单幅图像深度估计常用的数据集及模型方法
阐述基于传统机器学习的单目深度估计方法的研究进展
分析基于深度学习的单目深度估计方法的国内外研究现状及优缺点
展望基于深度学习的单目深度估计方法未来的研究趋势与重点
Saxena等人[1]在最大化后验概率框架下以超像素为单元,利用马尔可夫随机场(MRF)拟合特征与深度、不同尺度的深度之间的关系,进而实现对深度的估计。
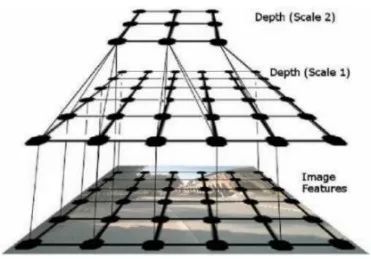
多尺度MRF的单目深度估计方法
Eigen等人[2]使用两个尺度的神经网络对单张图片的深度进行估计:粗尺度网络预测图片的全局深度,细尺度网络优化局部细节。
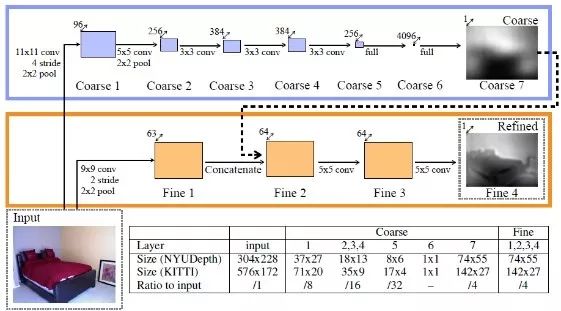
多尺度网络结构
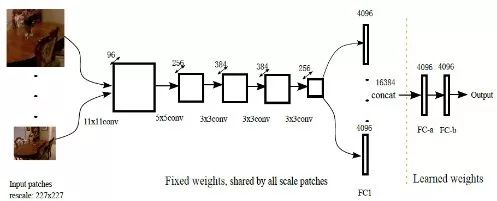
Eigen等人[3]网络模型使用了基础网络VGG (visual geometry group) Net;利用第3个细尺度的网络进一步增添细节信息,提高分辨率;将scale1网络的多通道特征图输入scale2网络,联合训练前面两个尺度的网络,简化训练过程,提高网络性能。
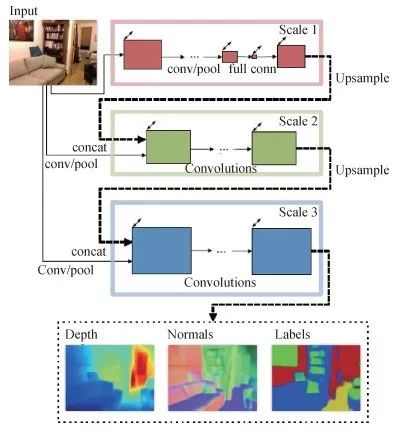
三尺度网络结构
Liu等人[4]将深度卷积神经网络与连续条件随机场结合,提出深度卷积神经场,用以从单幅图像中估计深度。对于深度卷积神经场,使用深度结构化的学习策略,在统一的神经网络框架中学习连续CRF的一元势能项和成对势能项。
深度卷积场网络
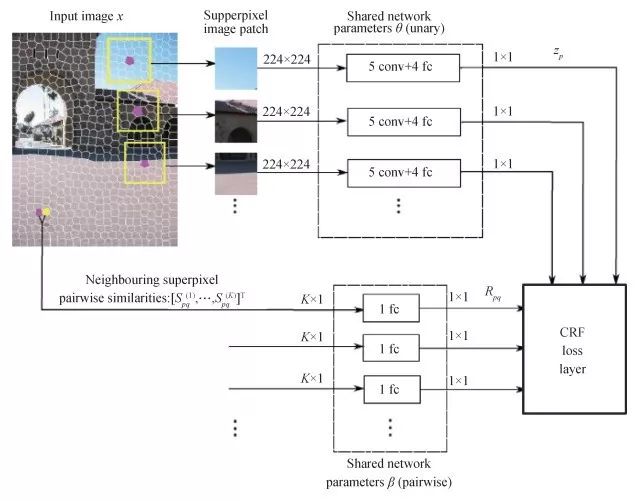
Liu等人[5]将超像素信息编码进神经网络中以提高计算效率。对于原条件随机场(CRF)中的一元部分,改进后以原图作为输入,输出包含对应超像素个数的n维特征向量。
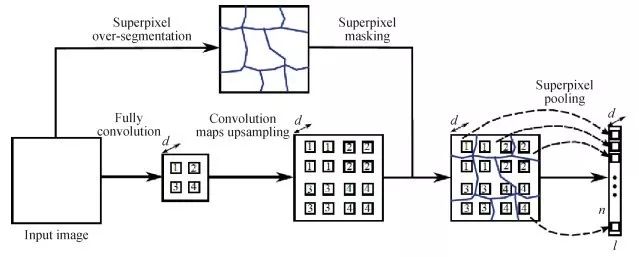
超像素池化层
Li等人[6]的多尺度深度估计方法,首先用深度神经网络对超像素尺度的深度进行回归,然后用多层条件随机场后处理,结合超像素尺度与像素尺度的深度进行优化。
多层条件随机场处理框架
Laina等人[7]提出了一种基于残差学习的全卷积网络架构用于单目深度估计,网络结构更深,并且不需要后处理。为了提高输出分辨率同时优化效率,采用一种新的上采样方法;考虑到深度的数值分布特性,引入了逆Huber Loss作为优化函数。
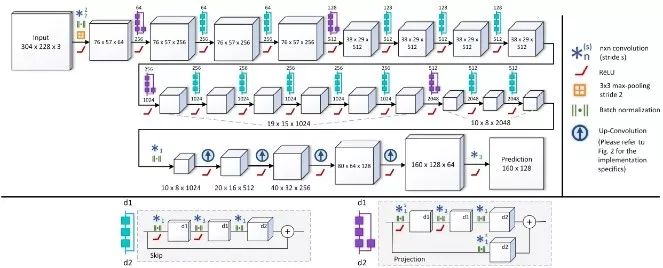
深度残差网络结构
Cao等人[8]将深度估计问题当作像素级的分类问题处理。首先将深度值离散化,然后训练一个深度残差网络预测每个像素对应的类别。分类之于离散不同之处在于能够得出一个概率分布,便于后面使用条件随机场作为后处理进行细节优化。
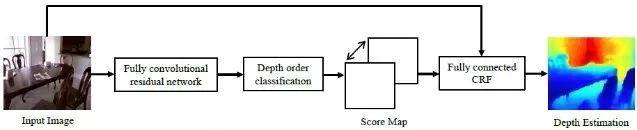
分类网络架构
Garg等人[9]利用立体图像对实现无监督单目深度估计,不需要深度标签,其工作原理类似于自动编码机。训练时利用原图和目标图片构成的立体图像对,首先利用编码器预测原图的深度图,然后用解码器结合目标图片和预测的深度图重构原图,将重构的图片与原图对比计算损失。
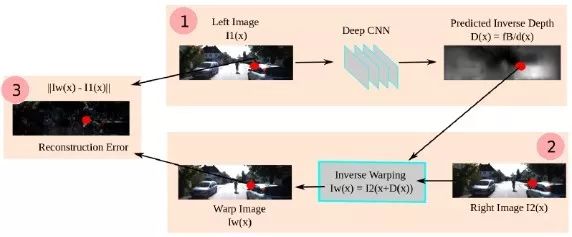
无监督深度估计基本框架
Godard等人[10]对上述方法进行了进一步改进,利用左右视图的一致性实现无监督的深度预测。利用对极几何约束生成视差图,采用左右视差一致性优化性能,提升鲁棒性。
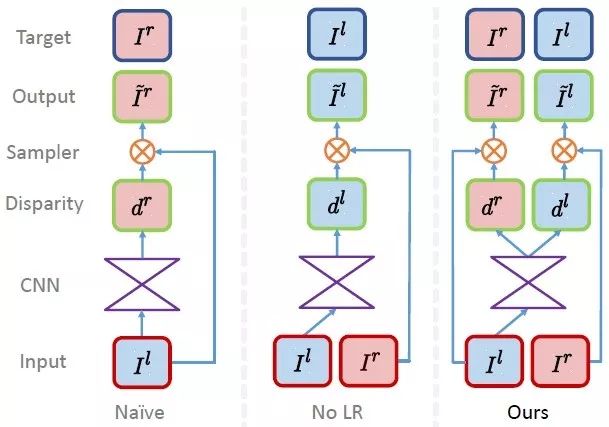
三种无监督学习框架
Kuznietsov等人[11]将以稀疏深度图为标签的监督学习方法和无监督的学习方法相结合进一步提高性能。监督学习的损失函数鼓励网络预测的深度图与传感器获得的深度图一致;无监督学习的损失函数鼓励重建图片与原图的一致性;梯度正则项用以平滑优化。
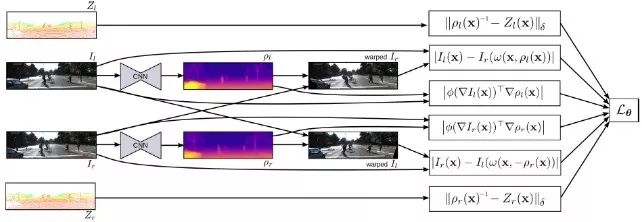
半监督学习深度估计框架
Zoran等人[12]关注相对深度关系,不同于使用深度值作为标签训练网络的方法,提出利用图像中点对之间的相对关系推断深度信息。该方法先通过网络输出点对之间的相对关系,然后利用数值优化方法将稀疏的输出进行稠密化,得到最终结果。
序列关系估计网络结构
Chen等人[13]创建了一个新的数据集“Depth In the Wild”,包含任意图片以及图片中随机点对之间的相对深度关系,利用相对深度关系构造损失函数,通过多尺度的神经网络直接预测像素级的深度。
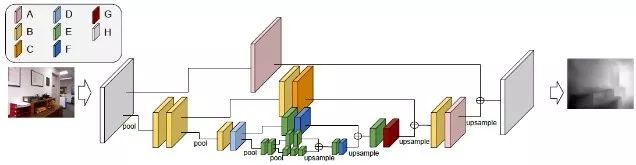
相对深度估计网络结构
由深度信息和语义信息之间的互补性,Wang等人[14]提出了一个统一的框架联合深度估计和语义分割任务。将原图分割成各个区域,然后在全局预测的指导下得到区域级的深度和语义标签。最后利用两层的条件随机场,由像素级的全局预测和区域级的局部预测得到最后的优化结果。
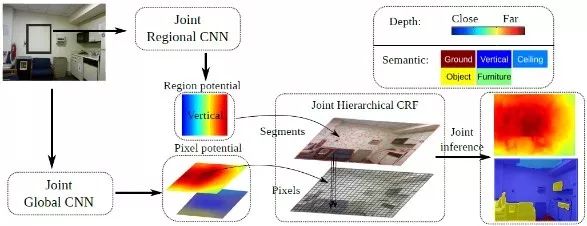
HCRF多尺度联合深度语义网络架构
Mousavian等人[15]提出一个同时预测深度和语义标签的模型,对每个任务先训练网络的一部分,再使用单个损失函数对两个任务同时优化微调整个网络,最后结合CNN与CRF,利用语义和深度线索对细节进行优化。
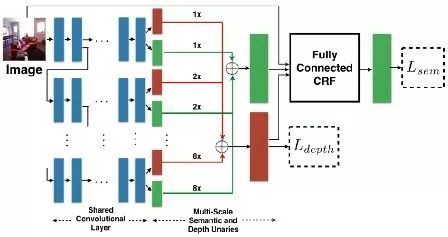
CRF联合深度语义网络架构
Wang等人[16]提出将深度与多种信息结合的框架,将CRF与CNN结合,推导了能量函数的梯度,使得整体框架能够通过反向传播算法加以优化。
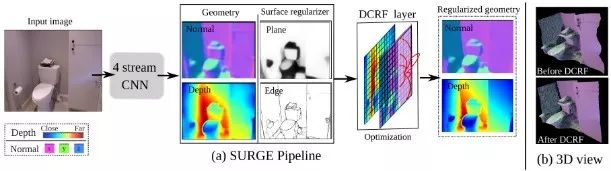
联合训练架构
深度学习的单目深度估计是本领域的发展方向,主要集中在数据集和深度学习模型两方面。
数据集的质量在很大程度上决定了模型的鲁棒性与泛化能力,深度学习要求训练数据必须有更多的数量、更多的场景类型,如何构建满足深度学习的数据集成为一个重要的研究方向。
基于虚拟场景生成深度数据具有不需要昂贵的深度采集设备、场景类型多样、节省人力成本等优势,结合真实场景和虚拟场景的数据共同训练也是未来深度学习方法的趋势。
深度学习发展迅速,新的模型层出不穷,如何将这些模型应用于单幅图像深度估计问题中需要更加深入地研究。
探索神经网络在单目深度估计问题中学到的是何种特征也是一个重要的研究方向。
参考文献

[1]Saxena A, Schulte J and Ng A Y. 2007. Depth estimation using monocular and stereo cues//Proceedings of the 20th International Joint Conference on Artifical Intelligence. Hyderabad: Morgan Kaufmann Publishers Inc., 2197-2203.
[2]Eigen D, Puhrsch C and Fergus R. 2014. Depth map prediction from a single image using a multi-scale deep network//Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal: MIT Press, 2366-2374
[3]Eigen D and Fergus R. 2015. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture//Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2650-2658[DOI: 10.1109/ICCV.2015.304]
[4]Liu F Y, Shen C H and Lin G S. 2015. Deep convolutional neural fields for depth estimation from a single image//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 5162-5170[DOI: 10.1109/CVPR.2015.7299152]
[5]Liu F Y, Shen C H, Lin G S, Lin G S, Reid I. 2016. Learning depth from single monocular images using deep convolutional neural fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(10): 2024-2039 [DOI:10.1109/TPAMI.2015.2505283]
[6]Li B, Shen C H, Dai Y C, Van den H A and He M Y. 2015. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 1119-1127[DOI: 10.1109/CVPR.2015.7298715]
[7]Laina I, Rupprecht C, Belagiannis V, Tombari F and Navab N. 2016. Deeper depth prediction with fully convolutional residual networks//Proceedings of the 4th International Conference on 3D Vision. Stanford: IEEE, 239-248[DOI: 10.1109/3DV.2016.32]
[8]Cao Y Z, Wu Z F, Shen C H. 2018. Estimating depth from monocular images as classification using deep fully convolutional residual networks. IEEE Transactions on Circuits and Systems for Video Technology, 28(11): 3174-3182 [DOI:10.1109/TCSVT.2017.2740321]
[9]Garg R, Vijay Kumar B G, Carneiro G and Ian R. 2016. Unsupervised CNN for single view depth estimation: geometry to the rescue//Proceedings of the 14th European Conference on Computer Vision. Amsterdam: Springer, 740-756[DOI: 10.1007/978-3-319-46484-8_45]
[10]Godard C, Aodha O M and Brostow G J. 2017. Unsupervised monocular depth estimation with left-right consistency//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 270-279[DOI: 10.1109/CVPR.2017.699]
[11]Kuznietsov Y, Stuckler J and Leibe B. 2017. Semi-supervised deep learning for monocular depth map prediction//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2215-2223[DOI: 10.1109/CVPR.2017.238]
[12]Zoran D, Isola P, Krishnan D and Freeman W T. 2015. Learning ordinal relationships for mid-level vision//Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 388-396[DOI: 10.1109/ICCV.2015.52]
[13]Chen W F, Zhao F, Yang D W and Jia D. 2016. Single-image depth perception in the wild//Proceedings of the 30th Conference on Neural Information Processing Systems. Barcelona. Curran Associates Inc: 730-738.
[14]Wang P, Shen X H, Lin Z, Scott C, Brian P and Alan L Y. 2015. Towards unified depth and semantic prediction from a single image//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2800-2809[DOI: 10.1109/CVPR.2015.7298897]
[15]Mousavian A, Pirsiavash H and Košecká J. 2016. Joint semantic segmentation and depth estimation with deep convolutional networks//Proceedings of the 4th International Conference on 3D Vision. Stanford: IEEE, 611-619[DOI: 10.1109/3DV.2016.69]
[16]Wang P, Shen X H, Russell B, Scott C, Brian P and Alan L Y. 2016. Surge: surface regularized geometry estimation from a single image//Proceedings of the 30th Conference on Neural Information Processing Systems. Barcelona. Curran Associates Inc: 172-180
作者简介

第一作者:黄军,硕士研究生,研究方向为深度学习与计算机视觉。
E-mail:huangjun@bit.edu.cn

通信作者:刘越,教授,主要研究领域包括虚拟现实与增强现实、自然人机交互、以及计算机视觉等。
E-mail:liuyue@bit.edu.cn
推荐阅读
李青松, 张旭东, 张骏, 高欣健, 高隽. RGB-D结构相似性度量下的多边自适应深度图像超分辨率重建[J]. 中国图象图形学报, 2019, 24(7): 1160-1175.
冯帆, 马杰, 岳子涵, 沈亮. 图像亮度线索下的单目深度信息提取[J]. 中国图象图形学报, 2017, 22(12): 1701-1708
熊伟, 张骏, 高欣健, 张旭东, 高隽. 自适应成本量的抗遮挡光场深度估计算法[J]. 中国图象图形学报, 2017, 22(12): 1709-1722.
杨媛, 陈福. 图像深度估计硬件实现算法[J]. 中国图象图形学报, 2018, 23(3): 362-371.

编辑推荐



本文系《中国图象图形学报》独家稿件
内容仅供学习交流
版权属于原作者
欢迎大家关注转发!
编辑:韩小荷
指导:梧桐君
审校:夏薇薇
总编辑:肖亮
声 明
欢迎转发本号原创内容,任何形式的媒体或机构未经授权,不得转载和摘编。授权请在后台留言“机构名称+文章标题+转载/转发”联系本号。转载需标注原作者和信息来源为《中国图象图形学报》。本号转载信息旨在传播交流,内容为作者观点,不代表本号立场。未经允许,请勿二次转载。如涉及文字、图片等内容、版权和其他问题,请于文章发出20日内联系本号,我们将第一时间处理。《中国图象图形学报》拥有最终解释权。






