用 TensorFlow Extended 实现可扩展、快速且高效的 BERT 部署(二)
特邀作者 / SAP Concur Labs 高级数据科学家 Hannes Hapke,
由 Robert Crowe 代表 TFX 团队编辑

自然语言处理中的 Transformer 模型和迁移学习概念为情感分析、实体提取和问题解答等任务带来了新的机遇。
BERT 模型让数据科学家得以站在巨人的肩膀上。在大型语料库上对 Transformer 模型进行预训练后,数据科学家便可利用这些经过训练的多用途模型来执行迁移学习,并在特定领域问题中找到最佳解决方案。
在稍早的一篇文章中,我们讨论了为何当前 BERT 模型的部署会令人感到过于复杂和麻烦,以及如何通过 TensorFlow 生态系统的库和扩展程序来简化部署。如果您还未查阅此文,我们建议您将其作为本文中所讨论的部署实现的背景知识进行了解。
在 SAP Concur Labs,我们研究了如何简化 BERT 部署,并发现 TensorFlow 生态系统提供了可以简单的对 Transformer 进行部署的完美工具。在本文中,我们希望带您深入了解我们的部署实现方案,以及我们如何使用 TensorFlow 生态系统组件来实现可扩展、高效和快速的 BERT 部署。
想要直接查看代码?
如果您想跳转至完整示例,请查看 Colab notebook,其中有我们用于生成可部署 BERT 模型的完整 TensorFlow Extended (TFX) 流水线的相关展示,且模型图中还包含预处理步骤。如果您想尝试进行演示部署,请查看 SAP Concur Labs 的演示页面,其中有我们情感分类项目的相关展示。
为何使用 TensorFlow Transform 执行预处理?
在回答这个问题之前,让我们先快速了解一下 BERT Transformer 的工作原理及 BERT 的当前部署方式。
BERT 需要哪些预处理?
input_type_ids
来区分不同的语句。
第二个张量
input_mask
则用于记录
input_word_ids 张
量内的相关标记。
这是必要操作,因为我们需要使用填充标记扩展我们的
input_word_ids
张量以达到最大序列长度。
扩展之后,所有
input_word_ids
张量都将具有相同的长度,但 Transformer 可以区分相关标记(来自我们输入语句的标记)与不相关的填充(填充标记)。

图 1:BERT 标记化
目前,在大多数 Transformer 模型部署中,根据实际模型预测以外的预处理步骤要求,如输入文本的标记化和转换会在客户端或服务器端进行处理。
这样的处理造成了一定的复杂性:如果预处理在客户端完成,那么如果标记和 ID 之间的映射发生改变(例如,我们想要添加新标记),则需要更新所有客户端。在服务器端完成预处理的大多数部署均使用基于 Flask 的网页应用来接受客户端的模型预测请求、标记化和转换输入语句,然后将数据结构提交给深度学习模型。但维护两个“系统”(一个用于预处理,一个用于实际模型推断)不仅麻烦且容易出错,同时还难以扩展。
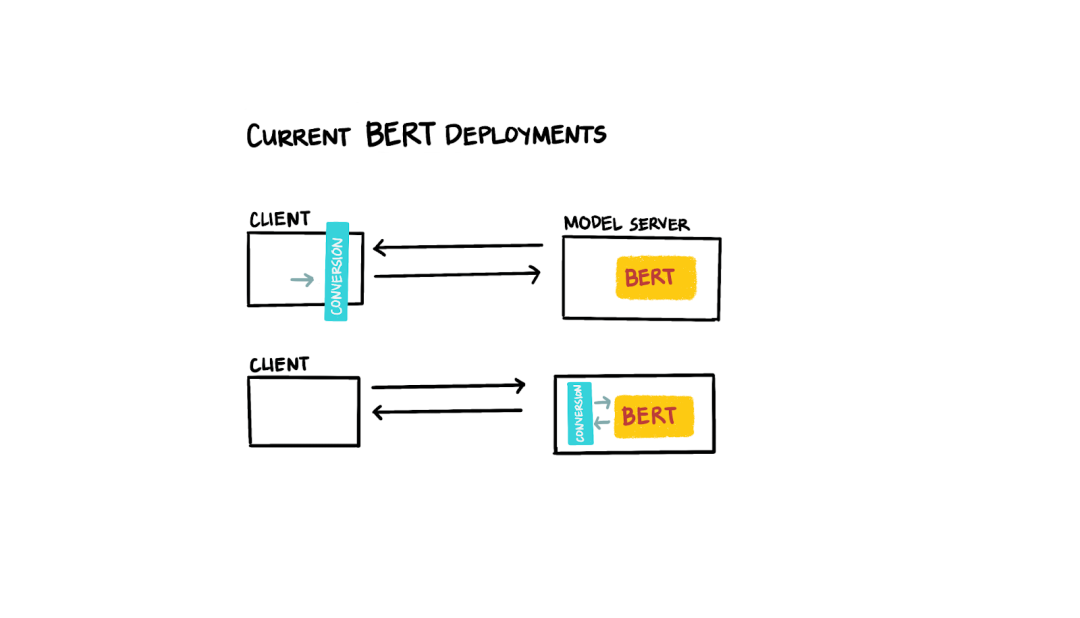
图 2:当前 BERT 部署
理想状态是将两个解决方案的优势相结合:即扩展轻松和升级简单。借助 TensorFlow Transform (TFT),我们可以通过将预处理步骤构建为图,将其与深度学习模型一起导出,最后仅需部署一个“系统”(深度学习模型与集成的预处理功能相结合)便可同时满足扩展和升级方面的要求。需指出的是,当我们希望针对特定领域的任务对 BERT 的 tf.hub 模块进行微调时,无法将所有 BERT 迁入预处理。
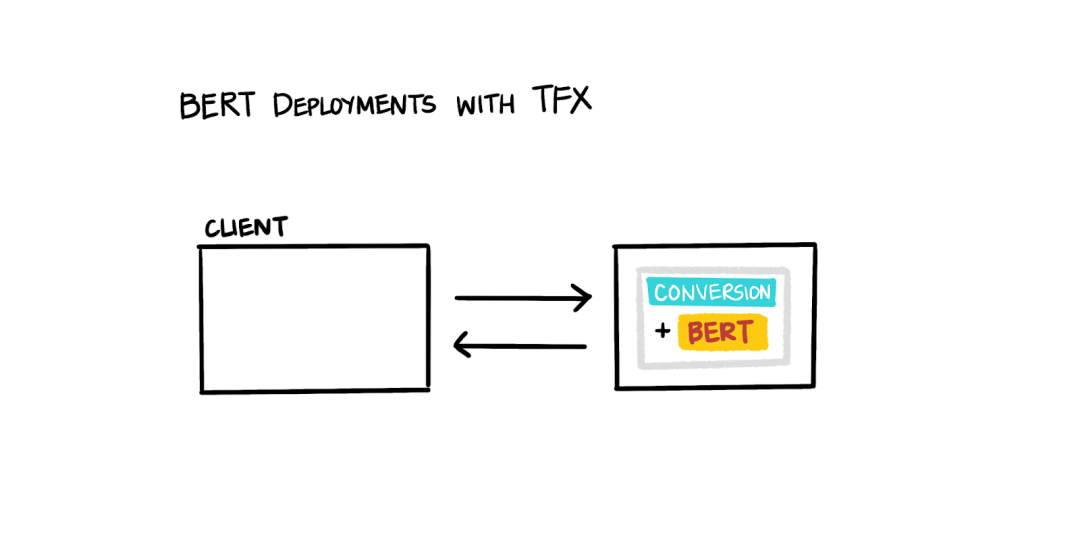
图 3:使用 TFX 的 BERT
使用 tf.text 处理自然语言
2019 年,TensorFlow 团队发布了新张量类型:RaggedTensors,支持在张量中存储不同长度的数组。RaggedTensors 的实现在 NLP 应用中尤为实用。例如,在将语句的一维数组标记化为具有不同数组长度的二维 RaggedTensor 时,该张量类型便能发挥用处。
标记化之前:
[
“Clara is playing the piano.”
“Maria likes to play soccer.’”
“Hi Tom!”
]
标记化之后:
[
[[b'clara'], [b'is'], [b'playing'], [b'the'], [b'piano'], [b'.']],
[[b'maria'], [b'likes'], [b'to'], [b'play'], [b'soccer'], [b'.']],
[[b'hi'], [b'tom'], [b'!']]
]
大家稍后将会看到,我们在流水线预处理中使用了 RaggedTensors。TensorFlow 团队于 2019 年 10 月下旬发布了 tf.text 模块的更新,该模块可执行 BERT 模型输入预处理所必需的词块标记化。
import tensorflow_text as text
vocab_file_path = bert_layer.resolved_object.vocab_file.asset_path.numpy()
do_lower_case = bert_layer.resolved_object.do_lower_case.numpy()
bert_tokenizer = text.BertTokenizer(
vocab_lookup_table=vocab_file_path,
token_out_type=tf.int64,
lower_case=do_lower_case)
TFText 为 BERT 模型所必需的词块标记化处理 (BertTokenizer) 专门提供了一个综合分词器。分词器会提供字符串 (tf.string) 标记化结果,或者已转换为 word_ids (tf.int32) 的标记化结果。
注意:tf.text 版本需要与导入的 TensorFlow 版本匹配。如果您使用的是 TensorFlow 2.2.x,则需要安装 TensorFlow Text 2.2.x 版,而不是 2.1.x 或 2.0.x。
我们如何使用 TensorFlow Transform 预处理文本?
input_word_ids, input_mask, and input_type_ids
数据结构。
我们可以使用 TensorFlow Transform 执行此转换。
下面我们具体介绍一下这一流程。
在我们的示例模型中,我们希望使用 BERT 模型对 IMDB 评论进行情感分类。
‘This is the best movie I have ever seen ...’ -> 1
‘Probably the worst movie produced in 2019 ...’ -> 0
‘Tom Hank\’s performance turns this movie into ...’ -> ?
这意味着我们在每次预测时将仅输入一个句子。在实践过程中,这也意味着所有已提交的标记都与预测相关(用 1 的向量表示),而所有标记都是句子 A 的一部分(用 0 的向量表示)。在分类操作中,我们不会提交任何句子 B。
如果您想将 BERT 模型用于其他任务,例如预测两个句子的相似度、实体提取或问答任务,则必须调整预处理步骤。
由于我们希望将预处理步骤导出为图,因此需要专门针对所有预处理步骤使用 TensorFlow 算子。根据这一要求,我们无法重用 CPython 中实现的 Python 标准库的函数。
TFText 提供的 BertTokenizer 将负责完成对原始传入文本数据的预处理。在此过程中不需要将字符串转换为小写格式(如果使用不区分大小写的 BERT 模型),也无需删除不受支持的字符。TFText 库中的分词器需要将受支持标记的表格作为输入。标记能以 TensorFlow LookupTable 形式提供,也可直接以词汇表文件的文件路径提供。TFHub 的 BERT 模型将提供这样的文件,我们可以据此确定文件路径:
import tensorflow_hub as hub
BERT_TFHUB_URL = "https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/2"
bert_layer = hub.KerasLayer(handle=BERT_TFHUB_URL, trainable=True)
vocab_file_path =
bert_layer.resolved_object.vocab_file.asset_path.numpy()
同样,我们也可以确定加载的 BERT 模型是否区分大小写。
do_lower_case = bert_layer.resolved_object.do_lower_case.numpy()
现在,我们可以将两个参数传递给 TFText BertTokenizer 并指定标记的数据类型。由于我们传递给 BERT 模型的是已标记化的字符串,因此需要以标记索引的形式提供标记(以 int64 整数提供)
bert_tokenizer = text.BertTokenizer(
vocab_lookup_table=vocab_file_path,
token_out_type=tf.int64,
lower_case=do_lower_case
)
在实例化 BertTokenizer 之后,我们可使用此标记化方法来执行标记化处理。
tokens = bert_tokenizer.tokenize(text)
将句子标记化处理为标记 ID 后,我们需要加上开头,并附加一个单独标记。
CLS_ID = tf.constant(101, dtype=tf.int64)
SEP_ID = tf.constant(102, dtype=tf.int64)
start_tokens = tf.fill([tf.shape(text)[0], 1], CLS_ID)
end_tokens = tf.fill([tf.shape(text)[0], 1], SEP_ID)
tokens = tokens[:, :sequence_length - 2]
tokens = tf.concat([start_tokens, tokens, end_tokens], axis=1)
MAX_SEQ_LEN
),并使用已定义的填充标记填充较短的张量。
PAD_ID = tf.constant(0, dtype=tf.int64)
tokens = tokens.to_tensor(default_value=PAD_ID)
padding = sequence_length - tf.shape(tokens)[1]
tokens = tf.pad(tokens,
[[0, 0], [0, padding]],
constant_values=PAD_ID)
执行最后一步后,我们将得到恒定长度的标记向量。这是主要预处理步骤的最后一步。根据标记向量,我们可以创建两个必需的附加数据结构 input_mask 和 input_type_ids。
如果创建的是 input_mask,我们则需要记录所有相关标记,基本上是除填充标记之外的所有标记。由于填充标记的值为零,并且所有 ID 均大于或等于零,因此我们可以使用以下算子来定义 input_mask。
input_word_ids = tokenize_text(text)
input_mask = tf.cast(input_word_ids > 0, tf.int64)
input_mask = tf.reshape(input_mask, [-1, MAX_SEQ_LEN])
在我们的示例中,确定 input_type_ids 更加简单。由于我们仅提交一个句子,因此在我们的分类示例中,类型 ID 的值均为零。
input_type_ids = tf.zeros_like(input_mask)
preprocessing_fn
函数中。
def preprocessing_fn(inputs):
def tokenize_text(text, sequence_length=MAX_SEQ_LEN):
...
return tf.reshape(tokens, [-1, sequence_length])
def preprocess_bert_input(text, segment_id=0):
input_word_ids = tokenize_text(text)
...
return (
input_word_ids,
input_mask,
input_type_ids
)
...
input_word_ids, input_mask, input_type_ids = \
preprocess_bert_input(_fill_in_missing(inputs['text']))
return {
'input_word_ids': input_word_ids,
'input_mask': input_mask,
'input_type_ids': input_type_ids,
'label': inputs['label']
}
训练分类模型
KerasLayer
。
为避免在转换步骤和模型训练之间出现任何的不一致,我们将根据转换步骤提供的特征规范创建输入层。
feature_spec = tf_transform_output.transformed_feature_spec()
feature_spec.pop(_LABEL_KEY)
inputs = {
key: tf.keras.layers.Input(
shape=(max_seq_length),
name=key,
dtype=tf.int32)
for key in feature_spec.keys()}
我们需要转换变量,因为 TensorFlow Transform 仅可将变量输出为以下类型之一:tf.string、tf.int64 或tf.float32(在我们的示例中为 tf.int64)。但是,上文 Keras 模型中使用的 BERT 模型来自 TensorFlow Hub,需要使用 tf.int32 输入类型。因此,为了使这两个 TensorFlow 组件的类型匹配,我们需要在将输入传递到已实例化的 BERT 层之前,转换输入函数或模型图中的输入。
input_word_ids = tf.cast(inputs["input_word_ids"], dtype=tf.int32)
input_mask = tf.cast(inputs["input_mask"], dtype=tf.int32)
input_type_ids = tf.cast(inputs["input_type_ids"], dtype=tf.int32)
将输入转换为 tf.int32 数据类型后,我们即可将其传递至 BERT 层。此层将返回两个数据结构:合并输出(代表整个文本的上下文向量),以及向量列表(为每个已提交的标记提供特定于上下文的向量表示)。由于我们仅关注整个文本的分类,因此可以忽略第二个数据结构。
bert_layer = load_bert_layer()
pooled_output, _ = bert_layer(
[input_word_ids,
input_mask,
input_type_ids
]
)
之后,我们可以使用 tf.keras 组装分类模型。在示例中,我们使用了 Keras 函数式 API。
x = tf.keras.layers.Dense(256, activation='relu')(pooled_output)
dense = tf.keras.layers.Dense(64, activation='relu')(x)
pred = tf.keras.layers.Dense(1, activation='sigmoid')(dense)
model = tf.keras.Model(
inputs=[inputs['input_word_ids'],
inputs['input_mask'],
inputs['input_type_ids']],
outputs=pred
)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
run_fn
函数来使用 Keras 模型。
利用 TFX 的最新更新,Keras 模型的集成也得以简化,在操作时无需再“绕道”使用
TensorFlow
model_to_estimator
函数。
现在,我们可以定义通用的
run_fn
函数,以使用此函数执行模型训练,并在训练完成后导出模型。
run_fn
函数设置:
def run_fn(fn_args: TrainerFnArgs):
tf_transform_output = tft.TFTransformOutput(fn_args.transform_output)
train_dataset = _input_fn(
fn_args.train_files, tf_transform_output, 32)
eval_dataset = _input_fn(
fn_args.eval_files, tf_transform_output, 32)
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model = get_model(tf_transform_output=tf_transform_output)
model.fit(
train_dataset,
steps_per_epoch=fn_args.train_steps,
validation_data=eval_dataset,
validation_steps=fn_args.eval_steps)
signatures = {
'serving_default':
_get_serve_tf_examples_fn(model, tf_transform_output
).get_concrete_function(
tf.TensorSpec(
shape=[None],
dtype=tf.string,
name='examples')),
}
model.save(
fn_args.serving_model_dir,
save_format='tf',
signatures=signatures)
请特别注意示例 Trainer 函数中的几行内容。借助最新版本的 TFX,我们现在可以利用 Keras 去年在 TFX 训练器组件中引入的分配策略。
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model = get_model(tf_transform_output=tf_transform_output)
在训练模型之前对数据集进行预处理最为高效,这样能够加快训练速度,尤其是训练器多次训练同一数据集时效果更为显著。
因此,TensorFlow Transform 将在训练和评估模型之前执行预处理,并将预处理后的数据存储为 TFRecords。
{'input_mask': array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]),
'input_type_ids': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]),
'input_word_ids': array([ 101, 2023, 3319, 3397, 27594, 2545, 2005, 2216, 2040, ..., 2014, 102]),
'label': array([0], dtype=float32)}
完成这些操作后,我们就可以生成预处理图,然后在执行训练后的预测模式期间应用。由于我们会重复使用预处理图,因此可避免在预处理时模型训练和模型预测之间出现偏差。
run_fn
函数中“连接”已预处理的训练和评估数据集,而不是训练期间使用的原始数据集:
tf_transform_output = tft.TFTransformOutput(fn_args.transform_output)
train_dataset = _input_fn(fn_args.train_files, tf_transform_output, 32)
eval_dataset = _input_fn(fn_args.eval_files, tf_transform_output, 32)
...
model.fit(
train_dataset,
validation_data=eval_dataset,
...)
训练完成后,我们可将训练后的模型连同处理步骤一同导出。
导出模型及其预处理图
model.fit()
完成模型训练后,我们将调用
model.save()
,以按 SavedModel 格式导出模型。
在模型签名定义中,我们调用了函数
_get_serve_tf_examples_fn()
解析序列化的 tf.Example 记录(已提交至 TensorFlow Serving 端点,在本示例中为待分类的原始文本字符串),然后应用 TensorFlow Transform 图中保存的转换。
随后,使用转换后的特征(即
model.tft_layer(parsed_features)
调用的输出)执行模型预测。
在本示例中,该特征可以是 BERT 标记 ID、掩码 ID 和类型 ID。
def _get_serve_tf_examples_fn(model, tf_transform_output):
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serve_tf_examples_fn(serialized_tf_examples):
feature_spec = tf_transform_output.raw_feature_spec()
feature_spec.pop(_LABEL_KEY)
parsed_features = tf.io.parse_example(serialized_tf_examples, feature_spec)
transformed_features = model.tft_layer(parsed_features)
return model(transformed_features)
return serve_tf_examples_fn
_get_serve_tf_examples_fn()
函数是 TensorFlow Transform 生成的转换图与已训练的 tf.Keras 模型之间的重要连接。
由于预测输入通过
model.tft_layer()
传递,因此可保证导出的 SavedModel 包含与训练期间相同的预处理操作。
SavedModel 是一张图,由预处理图和模型图组成。
tf.Example
记录的形式提交)并接收预测结果,而无需在客户端进行任何预处理,或使用预处理步骤执行复杂的模型部署。
研究展望
上文介绍的内容可简化 BERT 模型的部署。我们的演示项目中所示的预处理步骤可轻松进行扩展,以处理更复杂的预处理任务,例如实体提取或问答任务等等。此外,我们也正在研究重新使用预训练 BERT 模型的量化版本或精简版本(如 Albert)是否可以进一步减少预测延迟。
感谢您阅读这篇分为两个部分的文章。如您有任何疑问,建议您通过电子邮件随时与我们联系。
深入阅读
如果您对本项目中使用的 TensorFlow 库概述感兴趣,我们建议您阅读系列文章的第一部分。
如果您想尝试进行演示部署,请查看 SAP Concur Labs 的演示页面,其中有我们情感分类项目的相关展示。
如果您对 TensorFlow Extended (TFX) 和 TensorFlow Transform 的内部工作原理感兴趣,请查看即将出版的 O’Reilly 刊发文章《使用 TensorFlow 构建机器学习流水线》(Building Machine Learning Pipelines with TensorFlow)(已在网上预先发布)。
更多信息
要了解有关 TFX 的更多信息,请查看 TFX 网站,加入 TFX 讨论组,关注我们发布的 TFX 相关文章。
致谢
此项目的成功离不开 Catherine Nelson、Richard Puckett、Jessica Park、Robert Reed 与 SAP Concur Labs 团队的大力支持。同时,我们还要感谢 Robert Crowe、Irene Giannoumis、Robby Neale、Konstantinos Katsiapis、Arno Eigenwillig 和 TensorFlow 团队的其他成员,他们就实现细节展开讨论并认真审查了本文。特别感谢 Google TensorFlow 团队的 Varshaa Naganathan、Zohar Yahav 和 Terry Huang 为 TensorFlow 库提供了更新,让这一流水线的实现成为可能。还要特别感谢来自 Talenpair 的 Cole Howard,他总是能在自然语言处理相关的讨论中提出启发性的观点。
如果您想详细了解 本文提及 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
SAP Concur Labs 的演示页面
https://www.concurlabs.comColab notebook
http://bert-demo-code.concurlabs.com/RaggedTensors
https://tensorflow.google.cn/guide/ragged_tensortf.text 模块
https://tensorflow.google.cn/tutorials/tensorflow_text/intro#tokenization词块标记化
https://arxiv.org/pdf/1609.08144.pdfBertTokenizer
https://github.com/tensorflow/text/blob/master/tensorflow_text/python/ops/bert_tokenizer.pyIMDB 评论
https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviewsAlbert
http://bert-demo-code.concurlabs.com/O’Reilly 刊发文章《使用 TensorFlow 构建机器学习流水线》
http://www.buildingmlpipelines.comTFX 网站
https://tensorflow.google.cn/tfxTFX 讨论组
https://groups.google.com/a/tensorflow.org/forum/#!forum/tfx






