清华大学矣晓沅:「九歌」——基于深度学习的中国古典诗歌自动生成系统
AI 科技评论按:近年来人工智能与文学艺术的结合日趋紧密,AI 自动绘画、自动作曲等方向都成为研究热点。诗歌自动生成是一项有趣且具有挑战性的任务。在本次公开课中, 讲者将介绍清华自然语言处理与社会人文计算实验室的自动作诗系统,“九歌”,及其相关的技术方法和论文。
分享嘉宾:
矣晓沅,清华大学计算机系在读硕士, 导师为孙茂松教授。主要从事自然语言处理、文本生成方向的研究。研究工作在IJCAI、CoNLL、EMNLP等会议发表。
公开课回放地址:
http://www.mooc.ai/open/course/545?=Leiphone
分享主题:「九歌」——基于深度学习的中国古典诗歌自动生成系统
分享提纲:
任务背景及“九歌” 作诗系统简介
基于显著性上下文机制的诗歌生成
基于工作记忆模型的诗歌生成
基于互信息的无监督风格诗歌生成
雷锋网 AI 研习社将其分享内容整理如下:
人工智能的概念提出不久后,许多科学家试图将人工智能与日常生活相结合。在 NLP 领域,我们熟悉的有机器翻译、专家系统和对话系统,而诗歌属于人类语言中高度凝练,高度艺术化的体现,几十年以前便有科学家试图让 AI 具备创作诗歌的能力。
关于自动诗歌生成,我们的应用主要体现在:
一、娱乐场景——老百姓可以轻易通过诗意的方式去表达自己的情感;
二、诗词教育——了解诗词中的关键词、意象、押韵等元素是如何在诗词中起作用的。
三、文学研究——实验中关于词频、意象之间的关系的发现,能给文学研究一定的启发作用。
四、启发其他类型文本的生成(歌词、小说……)。
诗歌的特点是形式上高度凝练、简洁、节奏感强、语义丰富,因此我们认为它是自动分析、理解和生成文本的理想切入点。
关于自动诗歌的生成,业界的研究主要经历了三个阶段:

我们实验室是在 2016 年初开始做这件事情的,我们的九歌系统采用了最新的深度学习技术,结合多个为诗歌生成专门设计的不同模型,基于超过 30 万首的诗歌进行训练学习,能够产生集句诗、绝句、藏头诗、宋词等不同体裁的诗歌。
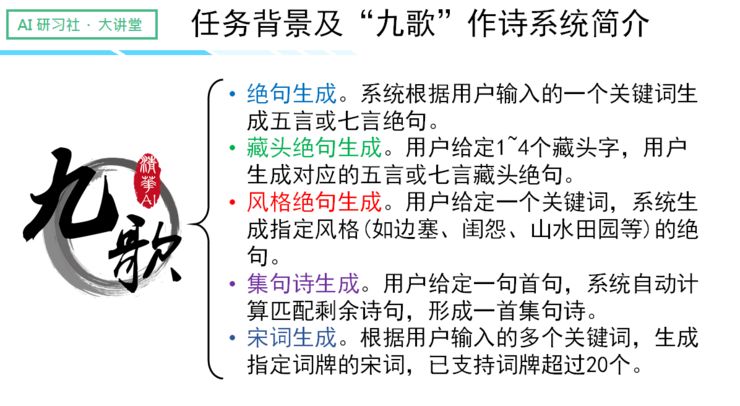
下面我会给大家介绍九歌系统背后的几个重要模型:
基于显著性上下文机制的诗歌生成
第一个模型被称作「基于显著性上下文机制的诗歌生成」,在这之前,针对中国古典诗歌自动生成的一些工作在新颖性、韵律和关键词插入有了显著提升,然而在上下文关联性方面还有所欠缺。前期的试验中,我们发现这也是自动诗歌生成系统的硬伤部分。

以这首诗为例子,诗歌主要以「春风」为关键词,通过 2016 的某个模型进行生成后,我们发现上下文的连贯性非常差。明明前两句描述的是比较和煦的景色,后两句却突然转变成比较悲怆的边塞风格。也就是说,前半部分与后半部分的主题、风格和内容完全不一致,而且中间也缺乏必要的过渡,关联性较差。
为什么模型会出现这样的问题呢?我们认为是因为之前的模型存在两种不合理的假设。
第一种是认为一首诗的生成过程中,历史信息可以被一个单独的历史向量存储和利用。

简单来说,就是每生成一句诗,便将这句诗的句向量压缩到历史向量中,以此类推,不停更新历史向量然后生成诗句。
这个假设会带来很多问题:
首先,单独的向量的 capasity 并不高,无法将大量的句子和语义给保存下来。
第二,语义较好的词和无明确语义的词(如停用词等)被混到了一起。
第二种不合理的假设认为 seq2seq 机制可以从一个无限长的历史序列里探索和利用历史信息。
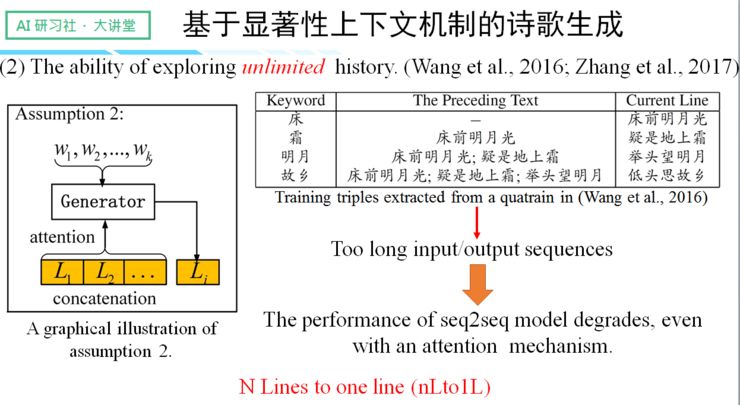
这种假设的好处是可以有区分性地选择历史信息,忽略虚词。然而随之而来的问题是,当诗词的句子数过多时,比如以某宋词的第十五句作为例子,那么就需要将前面的十四句先拼成很长的序列作为输入,这将导致性能的大幅下降。
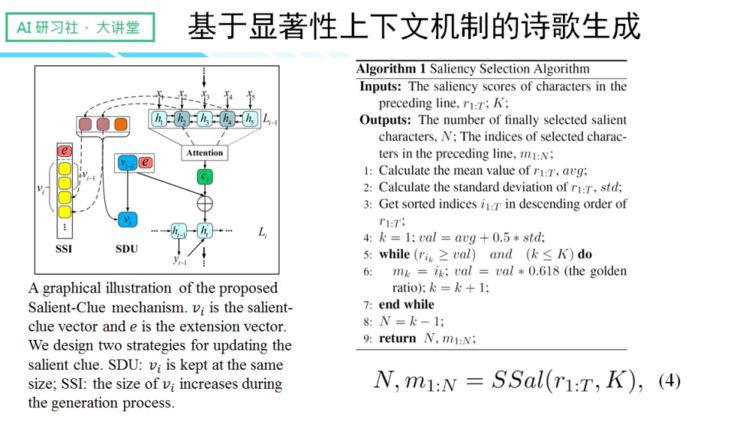
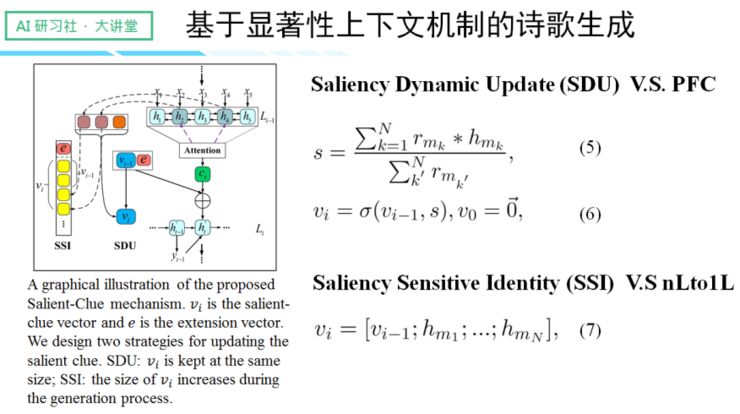
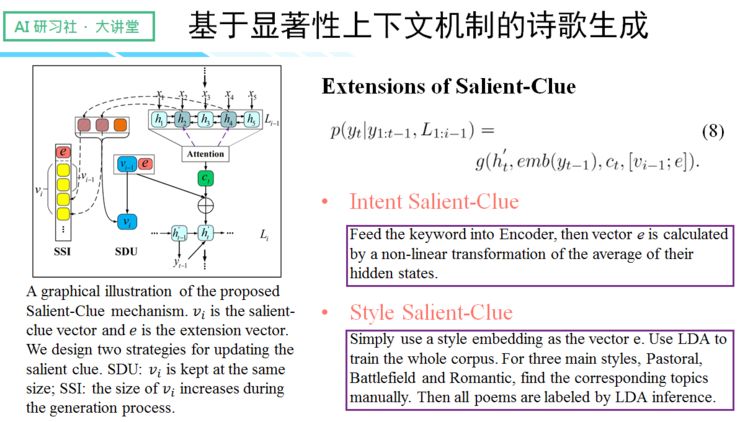
针对以上提到的两项问题,我们提出了 salient clue 机制,通过机制实现更优质的上下文捕捉。我们的内部设计逻辑是忽略句子里语义表现较差的部分,如虚词、停用词等,从而选择语义明确的部分来形成历史向量,来指导下文的生成。
【更多关于 salient clue 机制的运作原理,请回看视频 00:13:25 处,http://www.mooc.ai/open/course/545?=Leiphone】
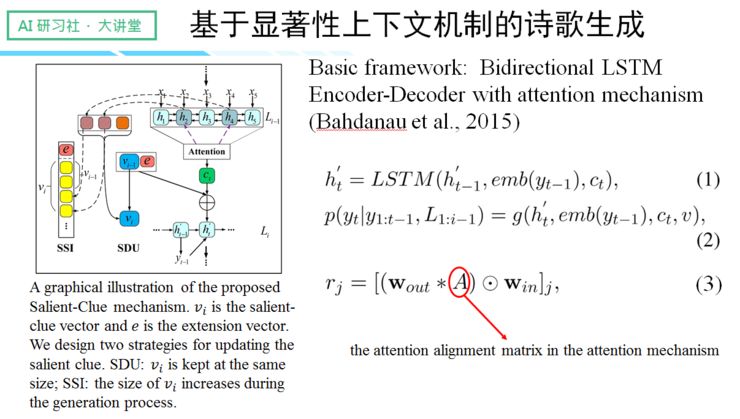
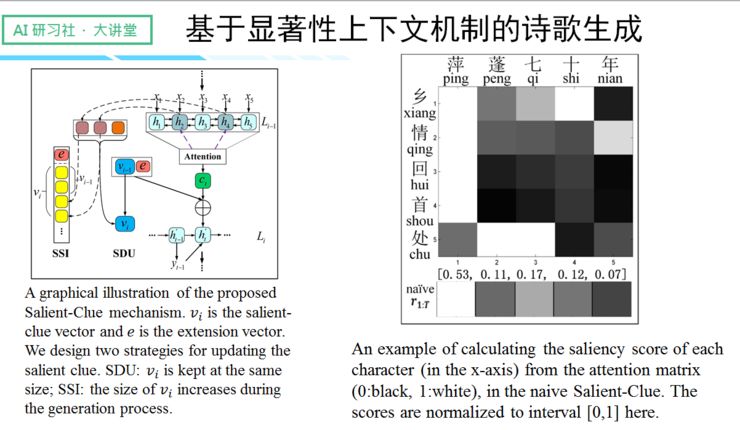
无论是在自动评测还是人工评测上,我们的结果与之前的模型相比,效果有了显著的提升。
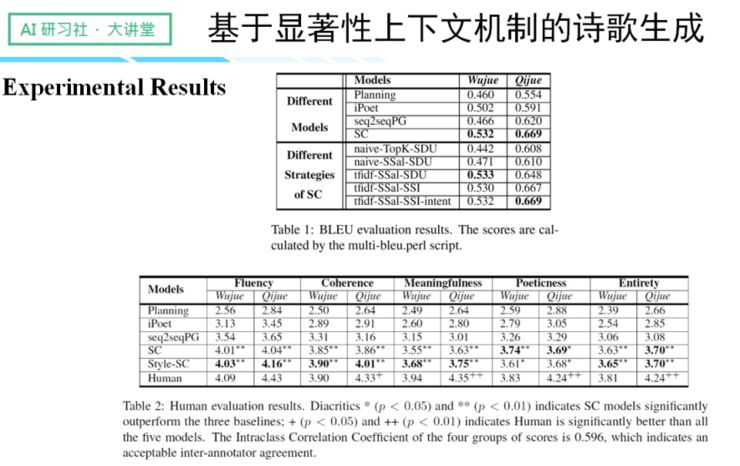
在人工评测的部分,加了 style 的诗歌在「诗意」环节的表现较差,这是因为被强制控制风格以后,最终生成的用词多样性也会变差。

左边是风格的人工评测识别矩阵,对角线上的数字越大,说明我们的风格控制准确率越高,可以看到,我们的结果在 70%—90% 之间。右边是另一项人工评测结果,目的是要检测模型选择的字是否靠谱,我们请了一些专家进行人工挑字,与模型进行对比,结果显示重合率在 50% 左右,有了明显的提升。
由于模型较基础,所以存在的问题不少:
一、 字词的选择较生硬;
二、 诗歌流畅性与诗意性受到影响。
基于工作记忆模型的诗歌生成
这个模型借鉴了认知心理学的原理——「工作记忆」。
人们认为怎样的文章才具备连贯性呢?当读者读到一个新的句子时,如果这个句子能和存储在读者大脑工作记忆中的内容,或者文章的主题与大意建立关联,那么读者就认为新读到的这个句子和上文是连贯的。
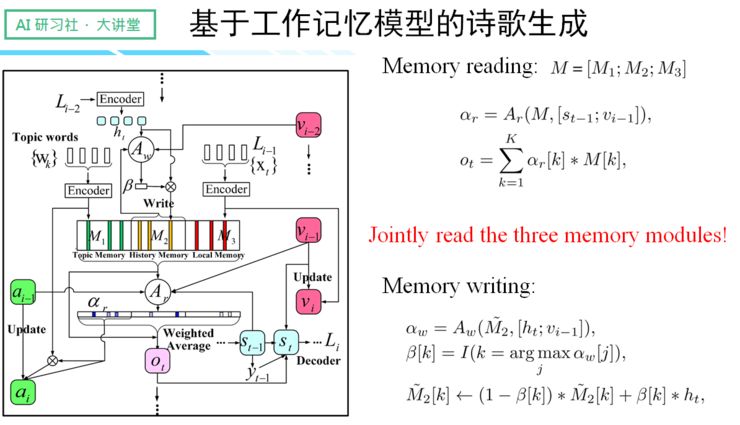
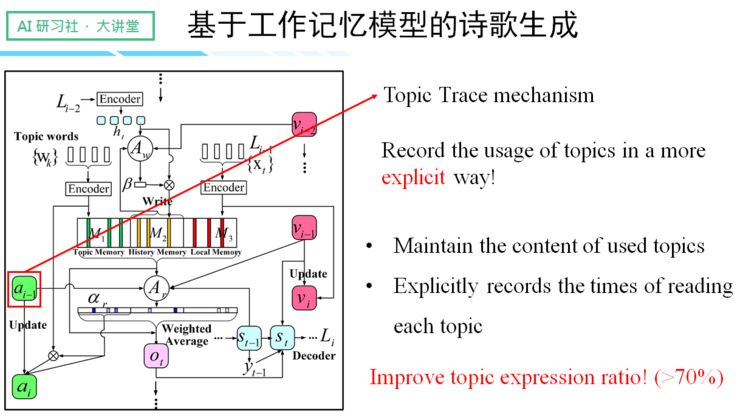
有鉴于此,我们便提出了「工作记忆模型」,该模型整体由三种不同的 Memory 组成:
一、 Topic Memory
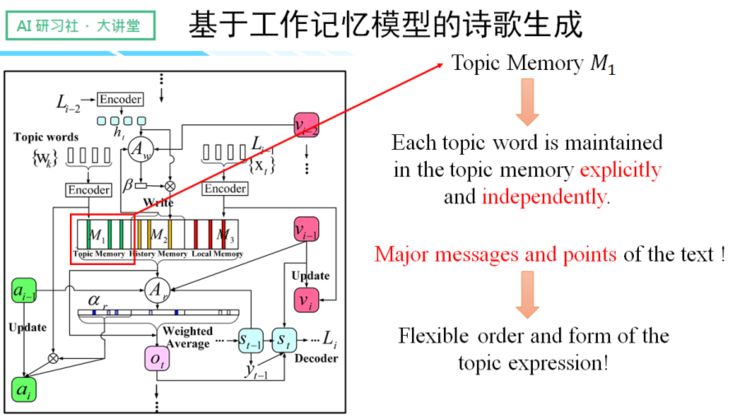
支持输入多个关键词,可以将用户输入的词单独保存在模型里,这里主要起的是约束诗歌整体主旨的角色。由于是独立保存,所以对关键词的输入顺序不做要求,是一项对用户非常友好的行为。
二、 History Memory
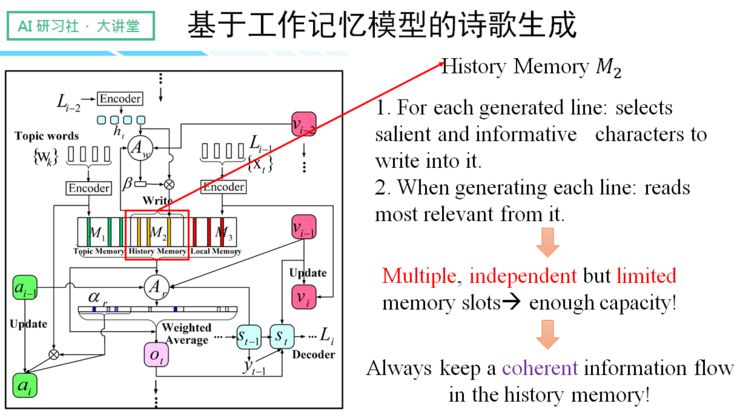
与之前提到的 salient clue 机制相类似。
三、 Local Memory
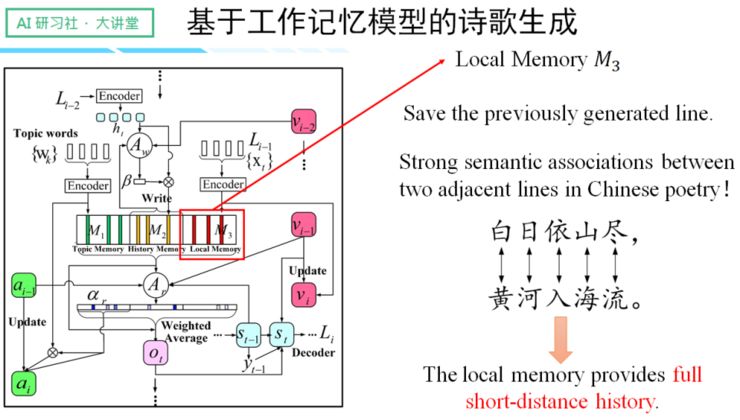
主要保存诗歌的前一个句子,因为中国古典诗歌的相邻句子往往有非常强的关联性。
【更多关于工作记忆模型的运作机制,请回看视频 00:27:25 处,http://www.mooc.ai/open/course/545?=Leiphone】
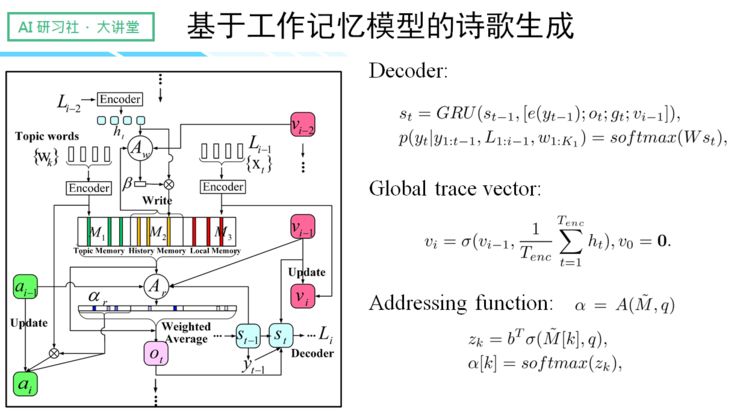
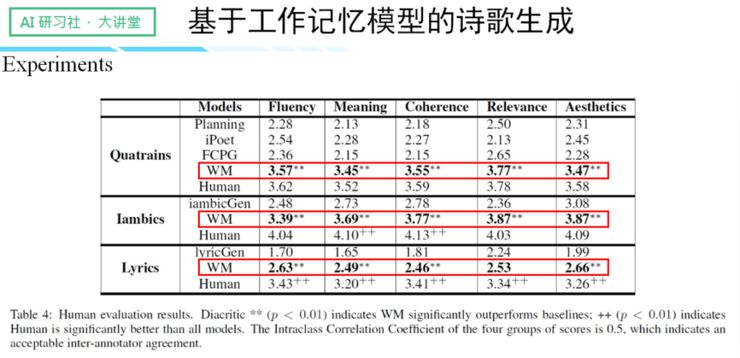
我们的实验分别生成了律诗、宋词和歌词,实验结果与不同模型相比,都有了很大的提升。
这是一张 perplexity 图,纵轴是 perplexity,横轴是诗歌的句子数目,不同颜色的线则表示 History Memory 的槽数。
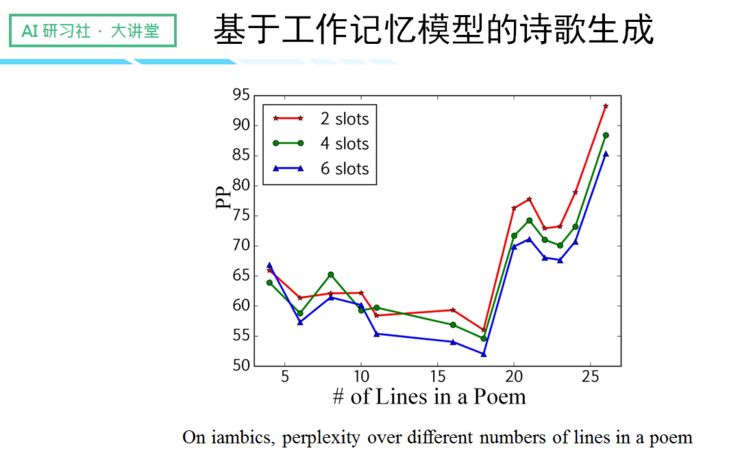
一首诗歌的句子数目越多,整体的 perplexity 就越大,因为句子数目越多,上下文的关联性越难被确认,导致不确定性越大。同时我们还发现,History Memory 的槽数越多,perplexity 就越小,不确定性也随着变小。
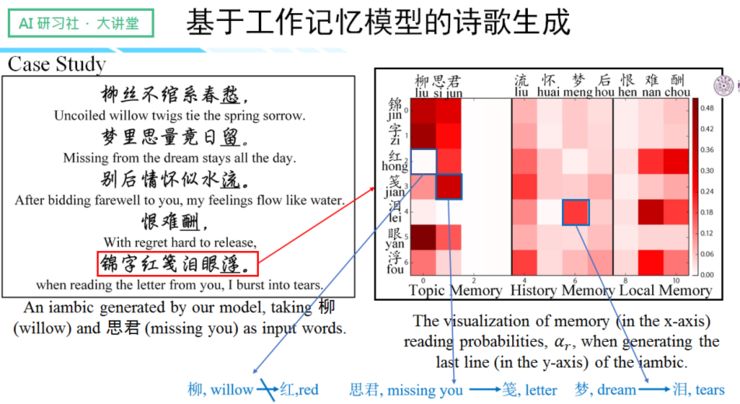

模型的成功之处,在于提升了读取词的可解释性和表达的灵活性。
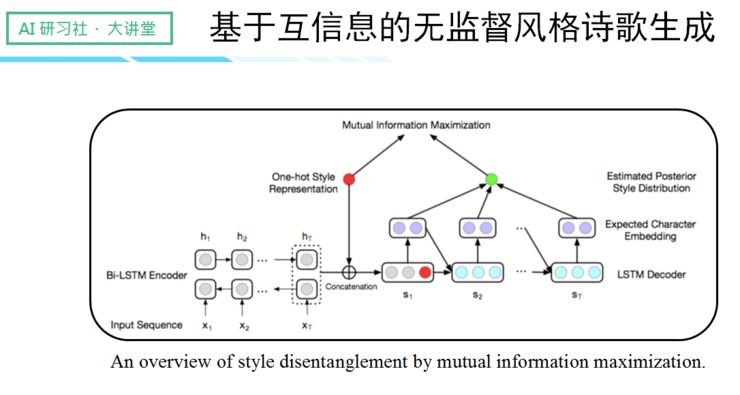
基于互信息的无监督风格诗歌生成
针对第一篇文章工作中存在的风格控制问题,我们又做了一项「基于互信息的无监督风格」的工作。众所周知,中国古诗具有不同的风格表达,其中三个最有代表性的分别是:边塞、闺怨和山水田园。
我们希望我们的模型可以做到以下几个要求:
一、 给出一个关键词,就能生成不同风格的诗歌。
二、 通过无监督的方式实现这个功能。
三、 生成的诗在其他指标上尽量减少损失或者没有损失(流畅性、通顺性……)
【更多关于无监督风格生成模型的运作机制,请回看视频 00:36:17 处,http://www.mooc.ai/open/course/545?=Leiphone】



实验中我们设置了 10 种不同的风格,每种风格分别生成一组诗,最后我们统计诗歌的词频。

右边是人类评测的结果,对角线越明显,说明风格的识别率越高。一下生成十种风格的诗歌,还能取得这么高的识别率,说明实验的结果非常好。

以上是生成的一些诗歌例子。
最后,欢迎大家前往试用我们的系统,多多给我们提宝贵的意见,后续我们会根据大家的反馈持续改进我们的系统。
系统地址:https://jiuge.thunlp.cn//

左下角是我的个人邮箱,欢迎大家随时跟我取得联系,今天我的分享就到此结束,谢谢大家!
以上就是本期嘉宾的全部分享内容。更多公开课视频请到雷锋网 AI 研习社社区(https://club.leiphone.com/)观看。关注微信公众号:AI 研习社(okweiwu),可获取最新公开课直播时间预告。






