观点 | 在工程领域中,机器学习的数学理论基础尤为重要
选自arXiv
作者:Paul J. Atzberger
机器之心编译
参与:路、思
数学在机器学习中非常重要,但我们通常只是借助它理解具体算法的理论与实际运算过程。近日加州大学圣巴巴拉分校的 Paul J. Atzberger 回顾了机器学习中的经验风险与泛化误差边界,他认为在科学和工程领域中,我们需要从基本理论与数学出发高效使用现有方法,或开发新方法来整合特定领域与任务所需要的先验知识。
近期研究人员越来越多地关注将机器学习方法应用到科学、工程应用中。这主要是受自然语言处理(NLP)和图像分类(IC)[3] 领域近期发展的影响。但是,科学和工程问题有其独特的特性和要求,对高效设计和部署机器学习方法带来了新挑战。这就对机器学习方法的数学基础,以及其进一步的发展产生了强大需求,以此来提高所使用方法的严密性,并保证更可靠、可解释的结果。正如近期当前最优结果和统计学习理论中「没有免费的午餐」定理所述,结合某种形式的归纳偏置和领域知识是成功的必要因素 [3 , 6]。因此,即使是现有广泛应用的方法,也对进一步的数学研究有强需求,以促进将科学知识和相关归纳偏置整合进学习框架和算法中。本论文简单讨论了这些话题,以及此方向的一些思路 [1 , 4 , 5]。
在构建机器学习方法的理论前,简要介绍开发和部署机器学习方法的多种模态是非常重要的。监督学习感兴趣的是在不完美条件下找出输入数据 x 的标注与输出数据之间的函数关系 f,即 y = f ( x) + ξ,不完美条件包括数据有限、噪声 ξ 不等于 0、维度空间过大或其他不确定因素。其他模态包括旨在发现数据内在结构、找到简洁表征的无监督学习,使用部分标注数据的半监督学习,以及强化学习。本文聚焦监督学习,不过类似的挑战对于其他模态也会存在。
应该强调近期很多机器学习算法的成功(如 NLP、IC),都取决于合理利用与数据信号特质相关的先验知识。例如,NLP 中的 Word2Vec 用于在预训练步骤中获取词标识符的词嵌入表示,这种表示编码了语义相似性 [3]。在 IC 中,卷积神经网络(CNN)的使用非常普遍,CNN 通过在不同位置共享卷积核权重而整合自然图像的先验知识,从而获得平移不变性这一重要的属性 [3]。先验知识的整合甚至包括对这些问题中数据信号的内在层级和构造本质的感知,这促进了深层架构这一浪潮的兴起,深层架构可以利用分布式表征高效捕捉相关信息。
在科学和工程领域中,需要类似的思考才能获取对该领域的洞察。同时我们需要对机器学习算法进行调整和利用社区近期进展,以便高效使用这些算法。为了准确起见,本文对监督学习进行了简要描述。与传统的逼近理论(approximation theory)相反,监督学习的目的不仅是根据已知数据逼近最优解 f,还要对抗不确定因素,使模型在未见过的数据上也能获得很好的泛化性能。这可以通过最小化损失函数 L 来获得,其中 L 的期望定义了真实风险 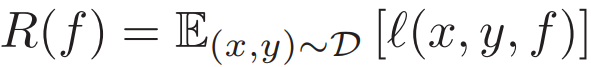
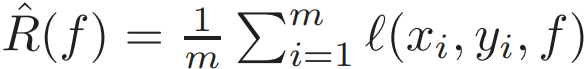
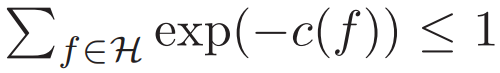
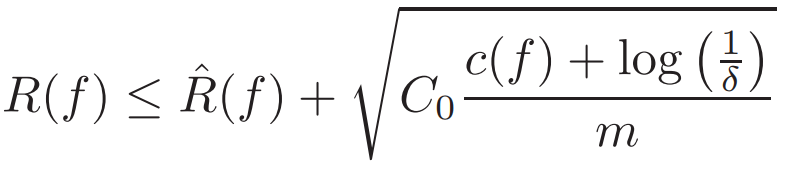
其中,概率 1 − δ 适用于随机数据集 [2]。类似的边界也可以从具备其他复杂度(如 VC 维或 Rademacher 复杂度)的连续假设空间中推导出。这在数学层面上捕捉了当前很多对应 RHS 优化的训练方法和学习算法。常见的选择是适用于有限空间的经验风险最小化,使用 c(f) = log(|H|),其中 c 不再在正则化中发挥作用。
我们可以了解到如何通过对假设空间 H 和 c(f) 的谨慎选择来实现更好的泛化与更优的性能。对于科学和工程应用而言,这可能包括通过设计 c(f) 或限制空间 H 来整合先验信息。例如限制 H 仅保持符合物理对称性的函数、满足不可压缩等限制、满足守恒定律,或者限制 H 满足更常见的线性或非线性 PDE 的类别 [1,4,5]。这可以更好地对齐优秀的 c(f) 和 R hat,并确保更小的真实风险 R(f)。尽管传统上这是机器学习的重点,但这不是唯一策略。
正如近期深度学习方法所展示的那样,你可以使用复杂的假设空间,但不再依赖于随机梯度下降等训练方法,而是支持更低复杂度的模型以仅保留与预测 Y 相关的输入信号 X。类似的机会也存在于科学和工程应用中,这些应用可获得关于输入信号相关部分的大量先验知识。例如,作为限制假设空间的替代方法,训练过程中你可以在输入数据上执行随机旋转,以确保选择的模型可以在对称情况下保持预测结果不变。还有很多利用对输入数据和最终目标的洞察来结合这些方法的可能性。
我们看到即使在本文提到的泛化边界类型方面也可以获取大量新观点。针对改进边界和训练方法做进一步的数学研究,可能对高效使用现有方法或开发新方法来整合先验知识方面大有裨益。我们希望本文可以作为在一般理论和当前训练算法中进行数学研究的开端,开发出更多框架和方法来更好地适应科学和工程应用。

原文地址:https://arxiv.org/pdf/1808.02213.pdf
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



