应聘机器学习工程师?这是你需要知道的12个基础面试问题
选自Medium
作者:JP Tech等
机器之心编译
参与:熊猫
毕业季找工作了?如果想应聘机器学习工程师岗位,你可能会遇到技术面试,这是面试官掂量你对技术的真正理解的时候,所以还是相当重要的。近日,JP Tech 发表了一篇文章,介绍了他们面试新人时可能会提出的 12 个面试问题。问题很基础,但却值得一看。




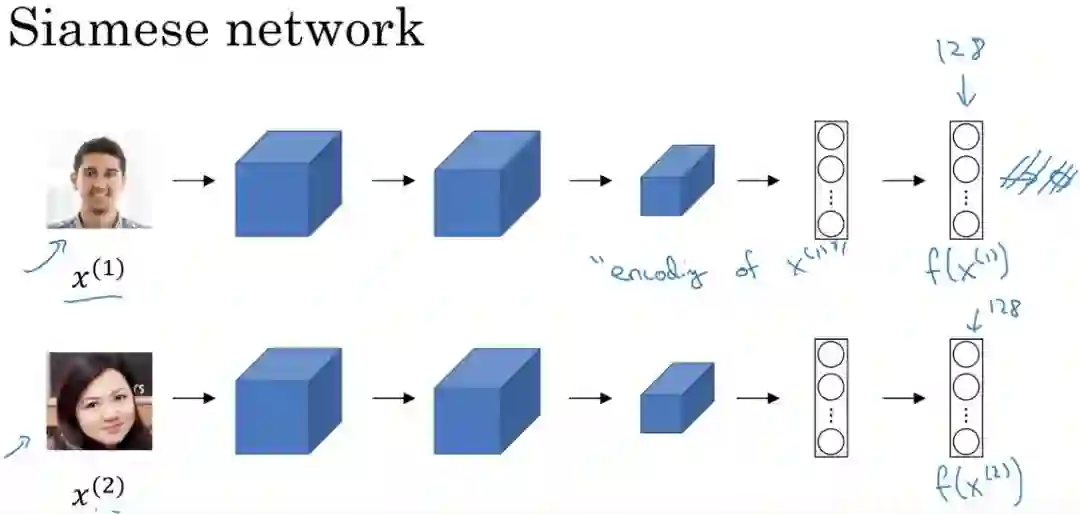

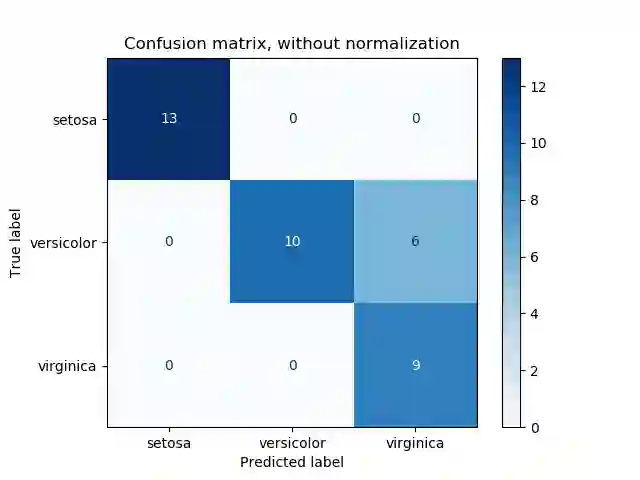
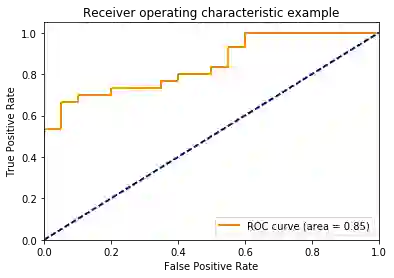
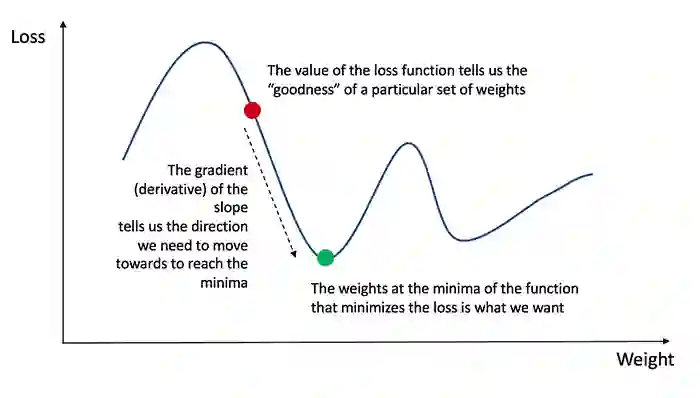
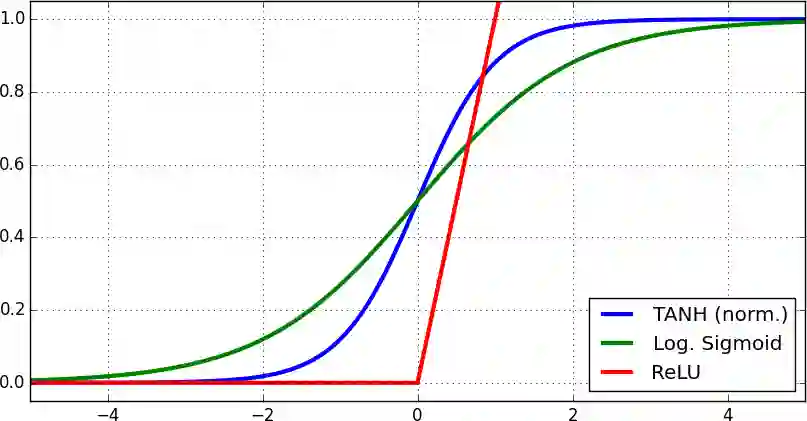
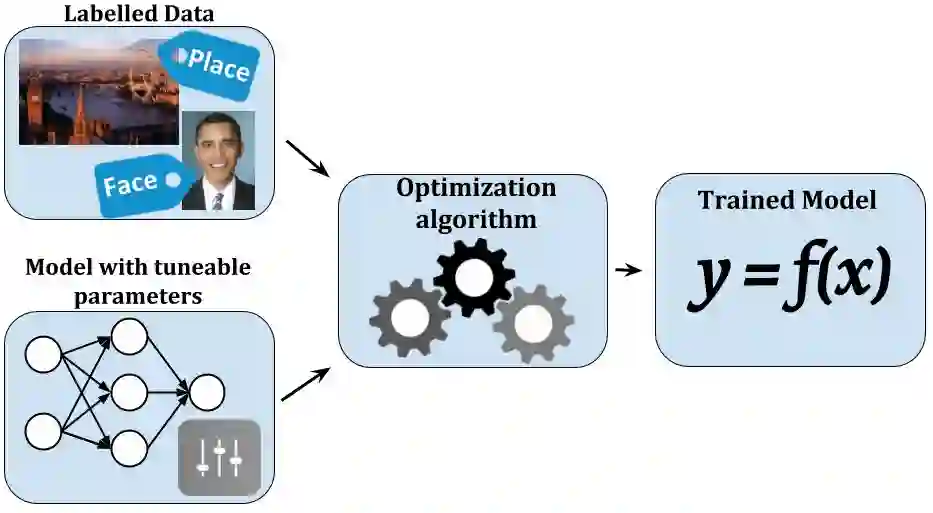
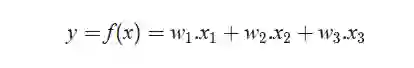
可用于预测新数据;
能展现我们使用的模型的能力,通常通过准确度等指标表示;
是直接从训练数据集学习到的;
不是由人类人工设置的。
在训练过程中使用,帮助模型寻找最合适的参数;
通常是在模型设计时由人工选择的;
可基于几种启发式策略来定义。
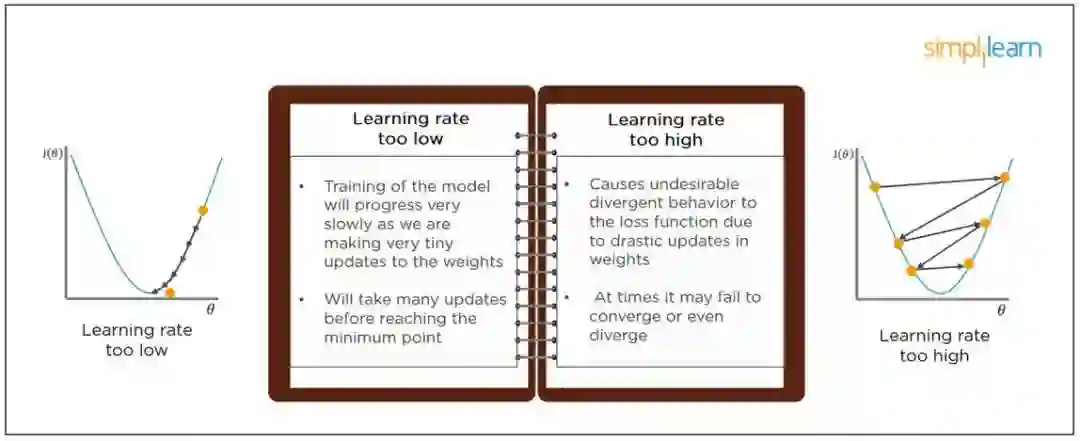
训练人工神经网络时的学习率指数;
训练支持向量机时的 C 和 σ 参数;
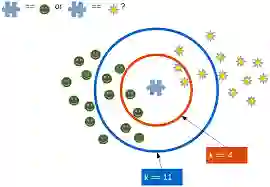
k 最近邻模型中的 k 系数。
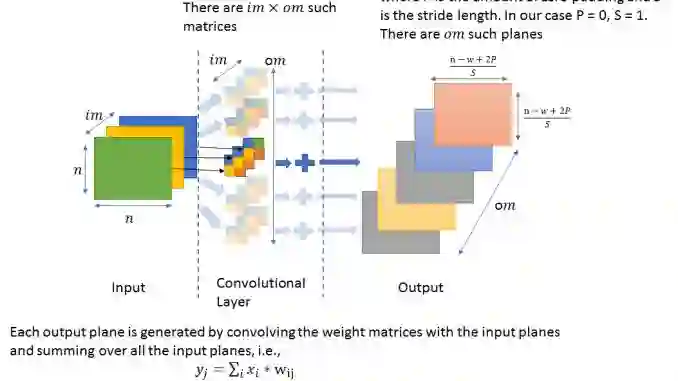
epoch:代表在整个数据集上的一次迭代(所有一切都包含在训练模型中);
batch:是指当我们无法一次性将整个数据集输入神经网络时,将数据集分割成的一些更小的数据集批次;
iteration:是指运行一个 epoch 所需的 batch 数。举个例子,如果我们的数据集包含 10000 张图像,批大小(batch_size)是 200,则一个 epoch 就包含 50 次迭代(10000 除以 200)。

登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文