赛尔笔记 | 对比学习
作者:哈工大SCIR 李明达
1.引言
近两年,对比学习(Contrastive Learning)在计算机视觉领域(CV)掀起了一波浪潮,MoCo[1]、SimCLR[2]、BYOL[3]、SimSiam[4]等基于对比学习思想的模型方法层出不穷,作为一种无监督表示学习方法,在CV的一些任务上的表现已经超过了有监督学习。同时,自然语言处理(NLP)领域近来也有了一些跟进的工作,例如ConSERT[5]、SimCSE[6]等模型利用对比学习思想进行句表示学习,在语义文本相似度匹配(STS)等任务上超过了SOTA。这篇笔记将带大家梳理一下对比学习的基本思想与方法,回顾一下CV领域对比学习的发展历程,并介绍几篇对比学习应用在NLP领域文本表示学习中的工作。
2.对比学习简介
2.1 基本思想
在介绍对比学习的具体方法之前,让我们先给对比学习下一个定义。对比学习是一种基于对比思想的判别式表示学习框架(或方法),主要用来做无监督(自监督)的表示学习(对比学习也可以用于有监督学习,但这不是对比学习的优势所在,故本文不再赘述)。可类比为NLP中Bert[7]应用的利用上下文重构遮盖词的遮盖语言模型(Masked Language Model),他不限于某一个或一类模型,而是一种利用无标签数据进行表示学习的思想。
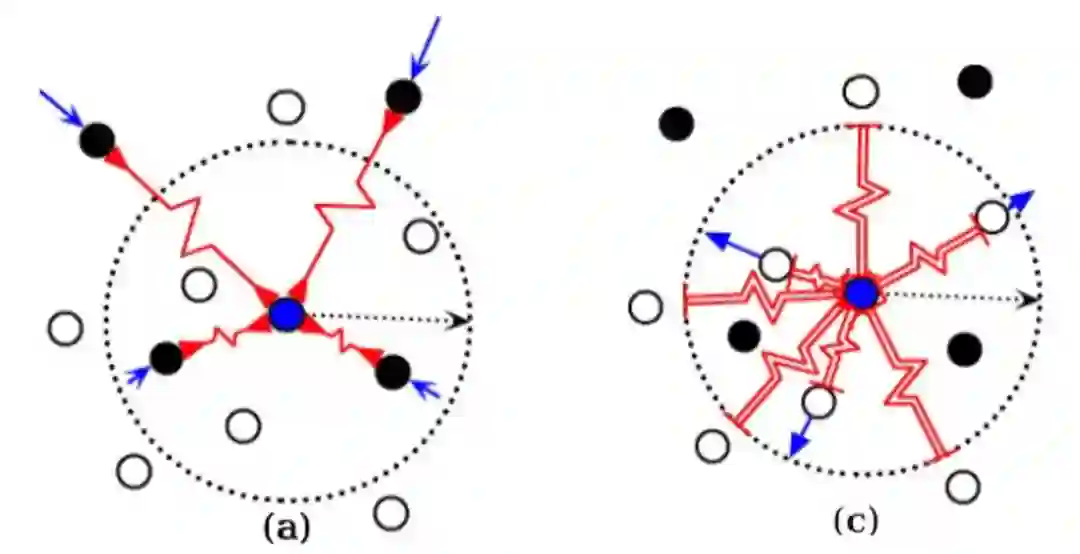
那对比学习采用的具体思想是什么呢?顾名思义,即将样例与与它语义相似的例子(正样例)和与它语义不相似的例子(负样例)进行对比,希望通过设计模型结构和对比损失,使语义相近的例子对应的表示在表示空间更接近,语义不相近的例子对应的表示距离更远,以达到类似聚类的效果,见图1。
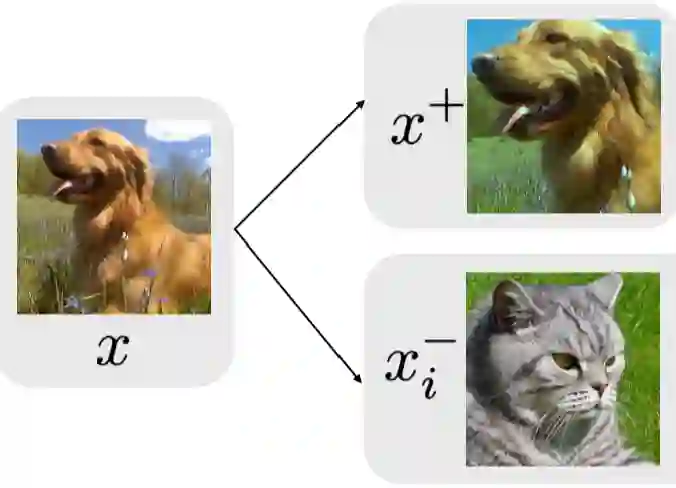
以图像为例,见图2,对比学习期望通过使同一类狗不同角度照片的表示相近,而不同种类动物对应的表示距离相远,使得学到的表示可以忽略掉角度(或光影等)变换带来的细节变动,进而学习到更高维度、更本质的特征(语义)信息。
这里我们引入两个重要的概念,对齐性(alignment)和均匀性(uniformity)[10]。由于对比学习的表示一般都会正则化,因而会集中在一个超球面上。对齐性和均匀性指的是好的表示空间应该满足两个条件:一个是相近样例的表示尽量接近,即对齐性;而不相近样例的表示应该均匀的分布在超球面上,即均匀性。满足这样条件的表示空间是线性可分的,即一个线性分类器就足以用来分类,因而也是我们希望得到的,我们可以通过这两个特性来分析表示空间的好坏。

从上文的描述中我们可以轻易地发现对比学习有三个重要的组成部分:正负样例、对比损失以及模型结构。模型结构将在第三章介绍具体工作时详解介绍,这一章我们先来聊一聊正负样例和对比损失。
2.2 正负样例
如上所述,正样例指的是与给定样例语义相近的样例,而负样例指的是与给定样例语义不相近的样例。对于有监督的数据,正负样例很容易构造,同一标签下的例子互为正样例,不同标签下的例子互为负样例,但对于无标签的数据,我们如何得到正负样例呢?
目前的主流做法是对所有样例增加扰动,产生一些新的样例,同一个样例扰动产生的所有样例之间互为正样例,不同样例扰动产生的样例彼此之间互为负样例。现在的问题就变成了如何可以在保留原样例语义不变的情况下增加扰动,构造新样例。
图像领域中的扰动大致可分为两类:空间/几何扰动和外观/色彩扰动。空间/几何扰动的方式包括但不限于图片翻转(flip)、图片旋转(rotation)、图片挖剪(cutout)、图片剪切并放大(crop and resize)。外观扰动包括但不限于色彩失真、加高斯噪声等,见图4的例子。

自然语言领域的扰动也大致可分为两类:词级别(token-level)和表示级别(embedding-level)。词级别的扰动大致有句子剪裁(crop)、删除词/词块(span)、换序、同义词替换等。表示级别的扰动包括加高斯噪声、dropout等。见图5。
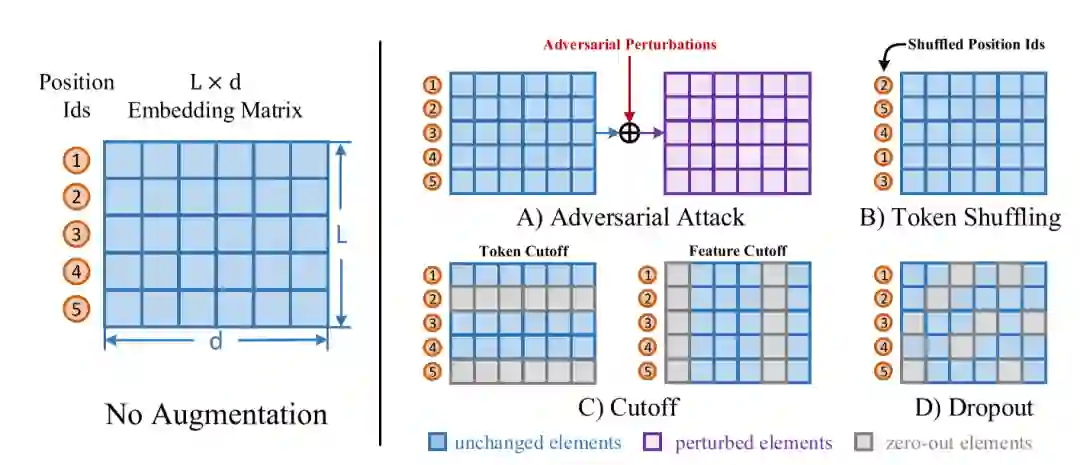
但是不同于图像领域,对自然语言的扰动很容易改变语义,这就会引入错误正例(False Positive)从而对模型训练产生不好的影响。同时,错误负例(False Negative)也是一个不容忽视的问题,见图6。文献[9]的作者证实了错误负例会对对比学习产生负面影响,并提出了一种对比损失去抵消这种影响,这里不赘述,感兴趣的朋友可以看原文。

2.3 对比损失
2.3.1 原始对比损失
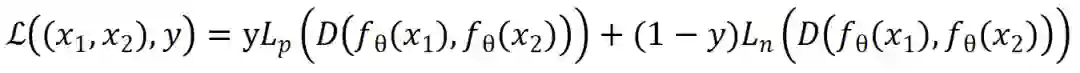
2.3.2 三元组损失(triplet loss)
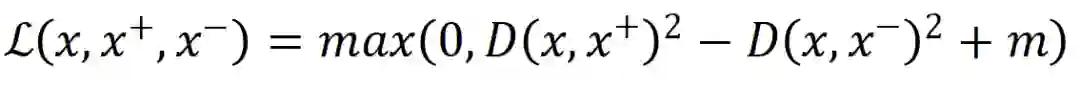
2.3.3 InfoNCE损失
NCE全称是噪声对比估计(Noise Contrastive Estimation),是文献[13]中提出的一种通过引入一个噪声分布,解决多分类问题softmax分母归一化中分母难以求值的问题。具体做法是把多分类问题通过引入一个噪音分布变成一个二元分类问题,将原来构造的多分类分类器(条件概率)转化为一个二元分类器,用于判别给定样例是来源于原始分布还是噪声分布,进而更新原来多元分类器的参数。听起来好像跟对比学习没什么关系,但如果把噪音分布的样本想成负样例,那这个二元分类问题就可以理解为让模型对比正负样例作出区分进而学习到正样例(原始分布)的分布特征,这是不是就跟对比学习的思想很像了?
而InfoNCE, 又称global NCE, 在文献[14]中提出。InfoNCE继承了NCE的基本思想,从一个新的分布引入负样例,构造了一个新的多元分类问题,并且证明了减小这个损失函数相当于增大互信息(mutual information)的下界,这也是名字infoNCE的由来。具体细节这里不再赘述,感兴趣的读者可以参考这篇文章:http://karlstratos.com/notes/nce.pdf,里面有比较清晰的介绍与推导。我们直接看一下目前对比学习中常见的infoNCE loss形式:
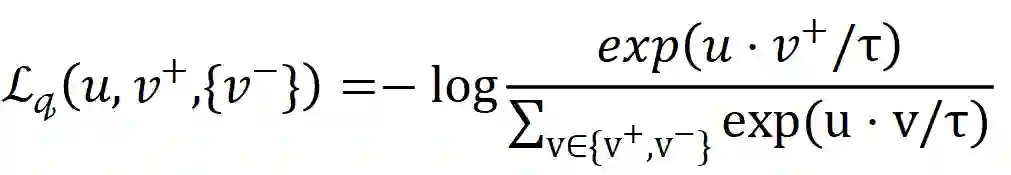
3.计算机视觉领域的对比学习
这一章将介绍近几年图像领域对比学习有代表性的几篇工作。
3.1 Memory Bank
根据infoNCE loss的特性,一般希望能提供尽量多的负样例进行优化,这样不但可以增加负例的多样性,同时可以提供更多的hard negatives,提升最终表现。但运算能力是有限的,因而就有工作考虑设计机制规避大量的运算,以增加一个样例可以对比负样例的个数,Memory Bank[15]和MoCo[1]就是其中的代表性工作。
Memory Bank顾名思义,在开始训练之前,先将所有图片的表示计算好储存起来,叫做memory bank。Bank中的表示将作为负例的表示参与构建对比损失,每次迭代更新参数后,当前batch中样例对应的memory bank中的表示将会用更新后的参数更新,以这样的方式慢慢更新memory bank中的样例表示。这种方式就不需要对大量负样例做前馈和反向传播运算,大大降低了运算量。但是这种方式有两大缺点:1、当样例数目很大时,需要占用极大的内存。2、样例迭代太慢,由于不同步更新的表示对应的表示函数不同,第一步batch更新的表示和第10000步batch更新的表示对应的函数参数可能差别非常大,造成了不一致的情况,那这两种表示进行对比会有很大的噪声。MoCo则借鉴强化学习的一些工作,引入了动量更新来解决这一问题。
3.2 MoCo
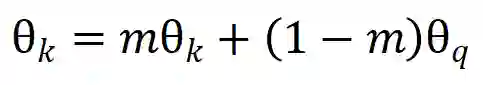
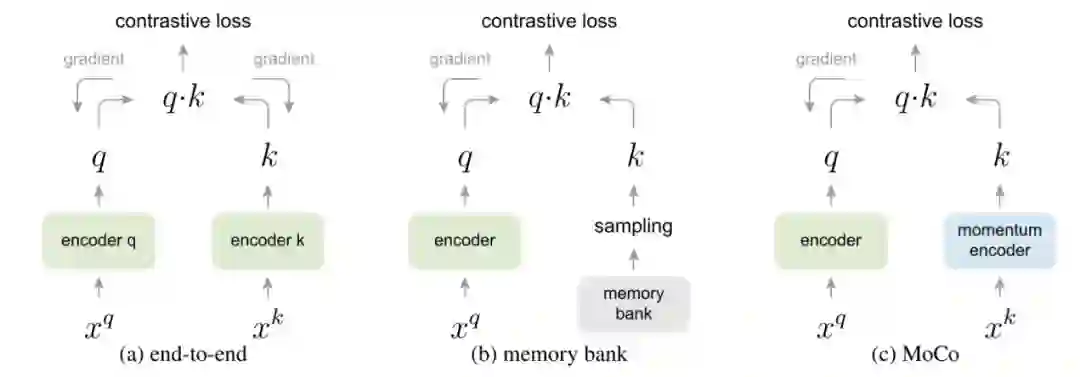

相信有些读者肯定有疑问,这种的做法是否有必要,负样例是否越多越好?SimCLR[2]的答案是,负样例越多越好,但是上述做法并没有必要,只要你有钱!
3.3 SimCLR
作为Google的大作,SimCLR用了128核的TPU和最标准的对比学习结构使得对比学习在图像领域第一次超过了有监督学习。同时他们做了大量的实验,得到了很多有意思的结论。
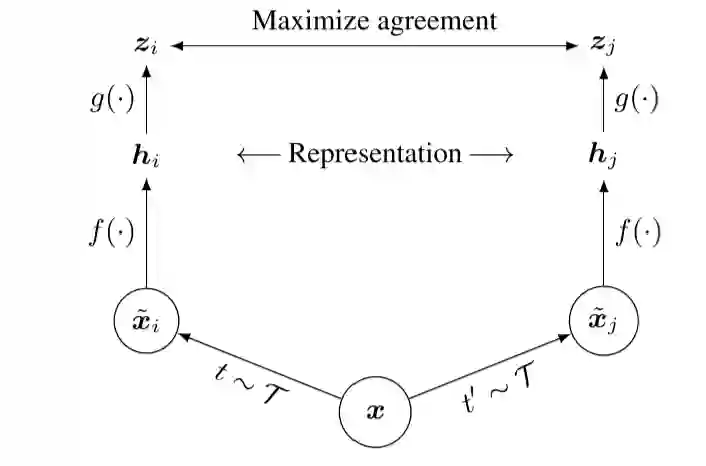
SimCLR的结构非常简单,见图9,一个对称的孪生网络。
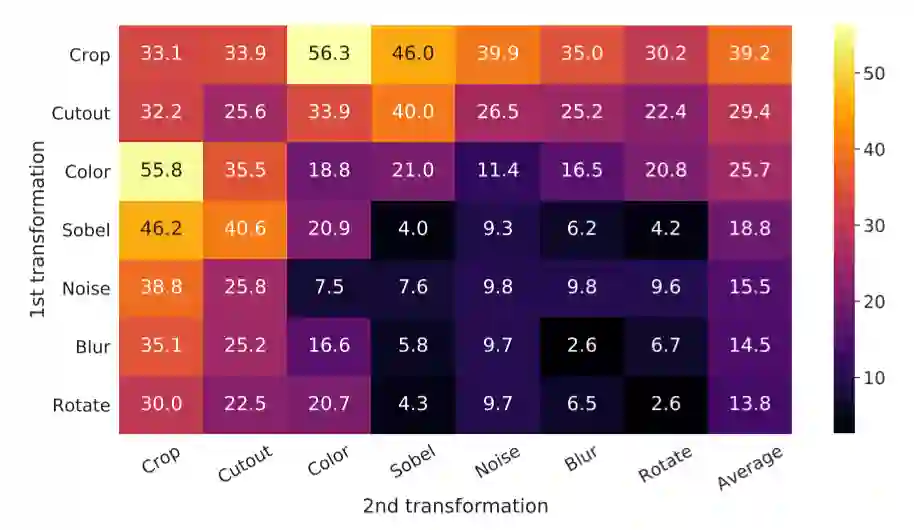
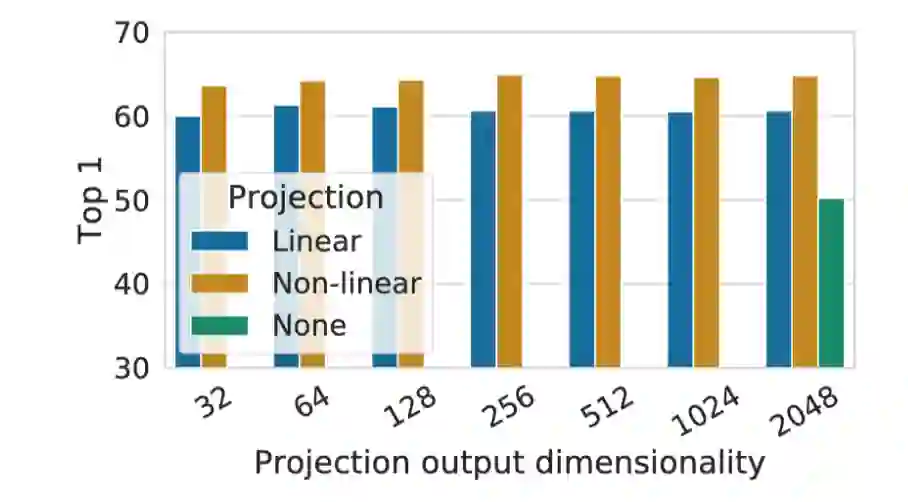
2、非线性映射头对提升表示的质量非常重要,见图11。
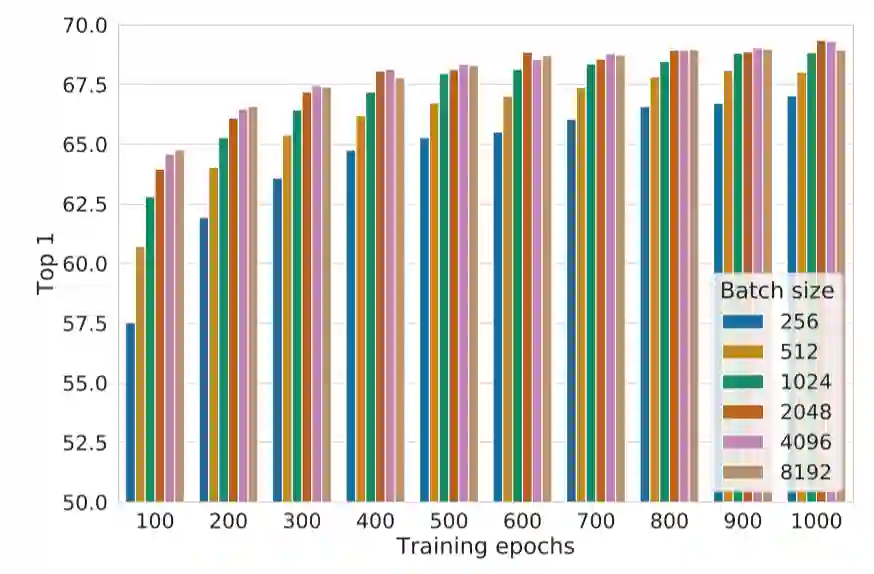
3、总的来说,batch size越大越好,训练时间越长越好,见图12。(这两个结论后来都被别的工作证实不总是正确的)
还有一些其他有意思的结论感兴趣的读者可以阅读原文。
但是并不是所有机构都有像谷歌一样的算力能够用128核的TPU进行运算,同时越大的batch size,就有越大的可能包含错误负例(False Negative);由于infoNCE损失的特性,这些错误负例会极大地影响损失函数进而提供错误信号影响模型学习,文献[9]也证实了这一现象。那我们能不能不对比负例,只通过对比正例进行对比学习,这样不就可以规避上述问题了吗?这直观上是不现实的,因为如果不拉远与负例的距离只拉近正例间的距离,那么模型很容易使所有样例的表示塌缩到同一个常数表示,这时损失为0,同时表示也失去了任何信息。神奇的是,有工作通过非对称结构避免了表示塌缩,实现了只用正例进行有效地对比学习,其中的典型工作就是接下来要介绍的BYOL[3]和SimSiam[4]。
3.4 BYOL与SimSiam
BYOL的结构非常简单,与MoCo非常相似,也应用了动量更新。见图13,BYOL用了非对称的孪生网络,原文分别称为在线网络(online network)和目标网络(target network)。
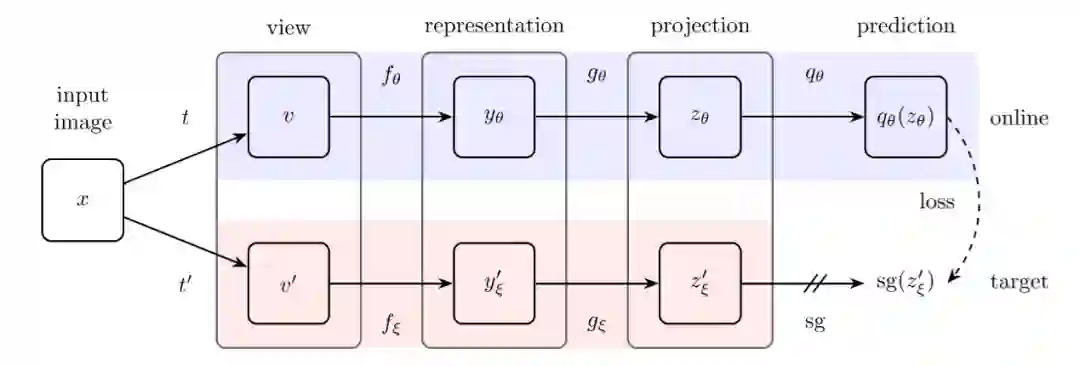
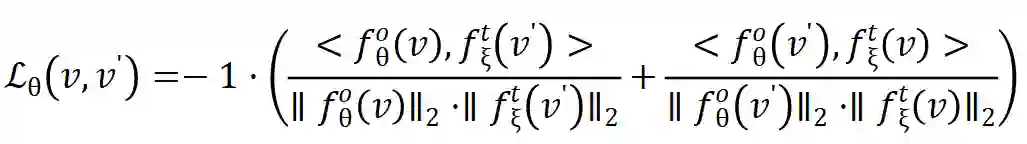
可以看到两个正样例交换顺序通过了两次孪生网络以充分利用数据。
虽然BYOL强调动量更新对构造非对称结构避免表示塌缩非常重要,但SimSiam证明了真正重要的并不是动量更新,而是在于不求导操作。SimSiam的结构同BYOL基本一样,见图14,encoder由ResNet和一映射头组成。
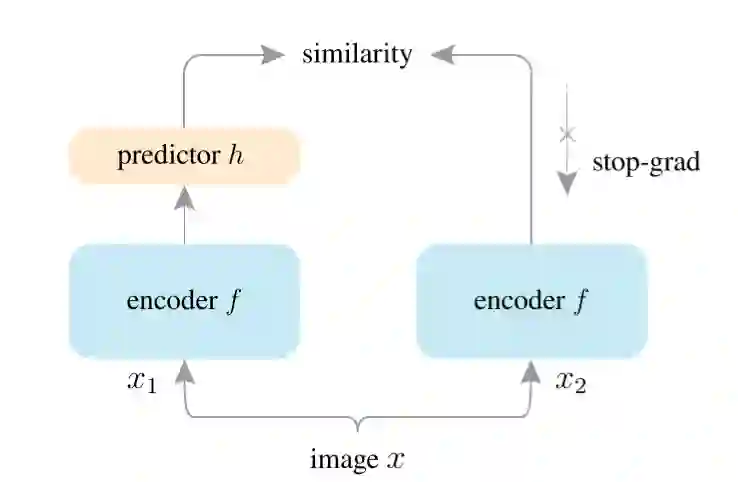
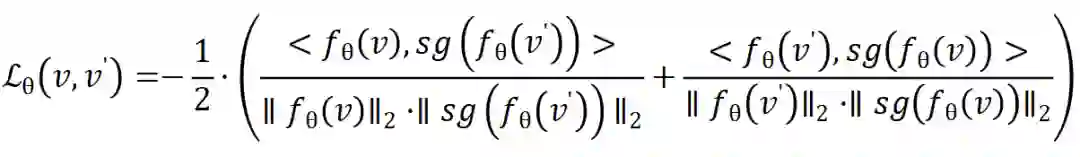
4.自然语言处理领域的对比学习
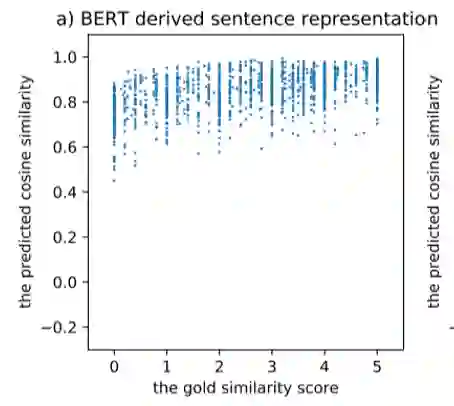
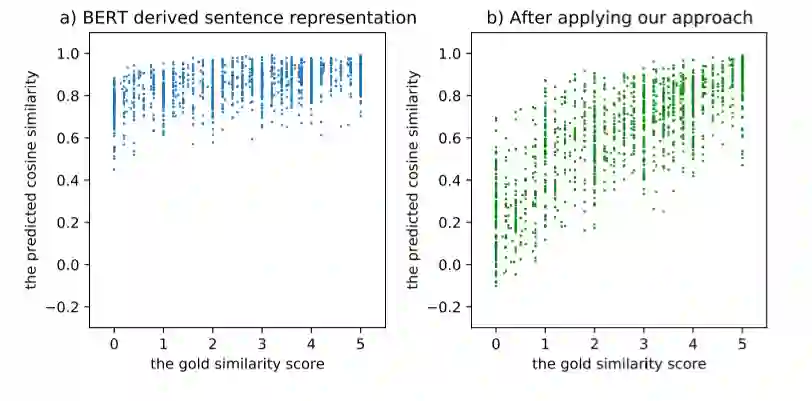
我们都知道,通过以Bert为代表的预训练模型得到的词表示在广泛的下游任务上都取得了非常不错的表现,但是句子表示(无论是用[CLS]特殊字符还是平均池化得到)的表现远不如词表示这么亮眼。文献[17]指出,通过Bert学到的词表示根据词频呈现不均匀分布,高频词离原点更近且彼此间距离更近,低频词离原点更远且更稀疏,因此平均后高频词对最终句表示的影响更大,导致Bert学到的句表示对语义变化不敏感,如图15,横坐标为文本语义匹配数据集中对句子相似度的人工评分,纵坐标为对应的Bert句向量得到的相似度评分,会发现Bert句向量并不能很好的区分语义相近和语义不相近的句子,而对比学习通过告诉模型拉远负例间的举例,很好的解决这个问题。
4.1 ConSERT
ConSERT[5]的模型结构非常简单,基本与SimCLR相同,只是把ResNet换成了Bert,并且去掉了映射头,见图16。
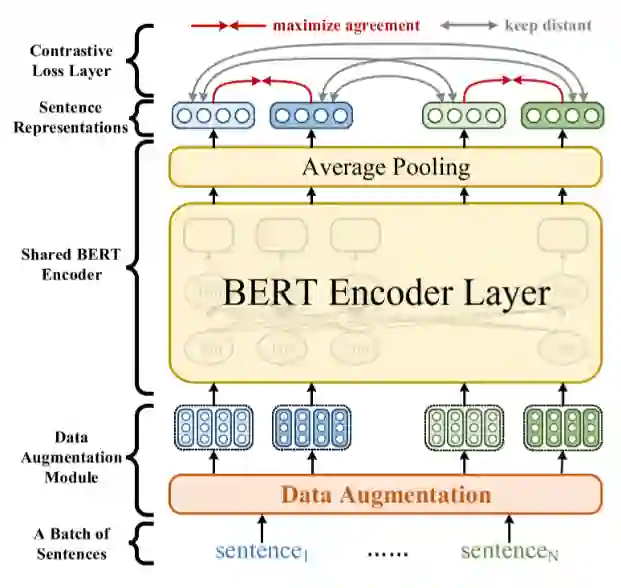
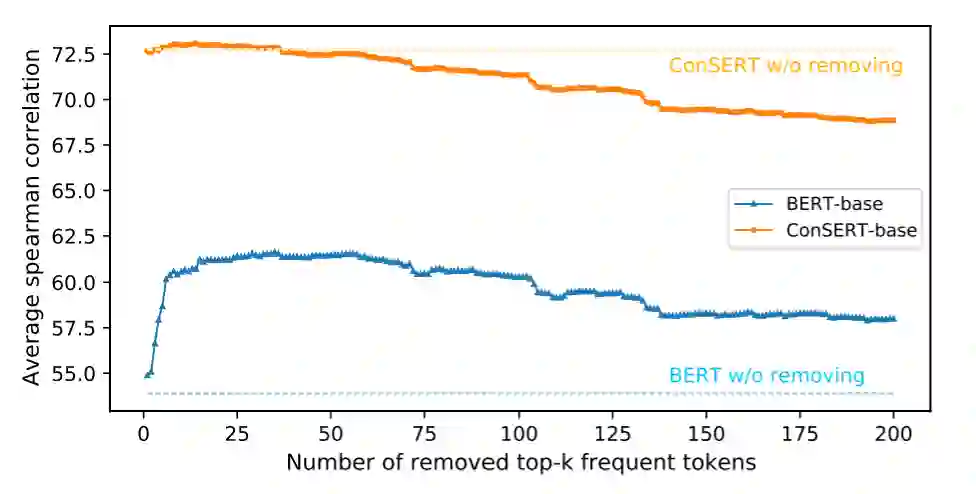
对比损失就是InfoNCE,数据增强方式见图5,包括词级别的词换序、删词,和表示级别的对抗扰动、删特征和输入dropout,作者还特意将Bert中原有的dropout率设为0,以保证正负样例对应的编码结构相同。实验结果表明学到的句表示可以很好的解决上文提到的问题,见图17。学到的句表示在语义匹配任务上的表现也远超之前方法。
4.2 SimCSE
在模型结构和对比损失上,SimCSE与ConSERT基本相同,只是把映射头又加上了,最大的区别就是数据增强方式。SimCSE的增强方式只有一种,Dropout,不是ConSERT中对输入的表示做dropout,而是BERT里原本的Dropout,对你没有看错,就是ConSERT故意删去的最基本的Dropout!SimCSE的两个正例仅仅是同一个句子过两遍Bert,这样简单的增强配上对比学习就实现了文本语义匹配任务的SOTA!不得不让人惊叹对比学习在语义表示学习上的能力。
5.总结
本文粗略的介绍了一下对比学习的思想与方法,以及一系列在图像、文本上的工作。对比学习在语义表示学习上的能力有目共睹,但还有一些问题,比如在自然语言领域,复杂的数据增强方式反而不如简单的dropout,这有没有可能是由于自然语言对扰动语义鲁棒性不强导致的呢?同时,CV领域的对比学习已经可以不用负例,那在NLP领域是不是也会有相似的发展轨迹呢?让我们拭目以待!
参考资料
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross B. Girshick. Momentum contrast for unsupervised visual representation learning. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020.
[2]Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020.
[3]Jean-Bastien Grill, Florian Strub, Florent Altch´e, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila´ Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, R´emi Munos, and Michal Valko. Bootstrap your own latent - A new approach to self-supervised learning. Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020.
[4]Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. CoRR, abs/2011.10566, 2020.
[5]Yuanmeng Yan, Rumei Li, Sirui Wang, Fuzheng Zhang, Wei Wu, and Weiran Xu. Consert: A contrastive framework for self-supervised sentence representation transfer. CoRR, abs/2105.11741, 2021.
[6]Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Simple contrastive learning of sentence embeddings. CoRR, abs/2104.08821, 2021.
[7]Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Association for Computational Linguistics, 2019.
[8]Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimensionality reduction by learning an invariant mapping. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2006). IEEE Computer Society, 2006.
[9]Ching-Yao Chuang, Joshua Robinson, Yen-Chen Lin, Antonio Torralba, and Stefanie Jegelka. Debiased contrastive learning. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020.
[10]Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020.
[11]Sumit Chopra, Raia Hadsell, and Yann LeCun. Learning a similarity metric discriminatively, with application to face verification. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), IEEE Computer Society, 2005.
[12]Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, IEEE Computer Society, 2015.
[13]Michael Gutmann and Aapo Hyv¨arinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Yee Whye Teh and D. Mike Titterington, editors, Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2010.
[14]A¨aron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. CoRR, 2018.
[15]Zhirong Wu, Yuanjun Xiong, Stella X. Yu, and Dahua Lin. Unsupervised feature learning via nonparametric instance discrimination. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018. IEEE Computer Society, 2018.
[16]Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
[17]Bohan Li, Hao Zhou, Junxian He, Mingxuan Wang, Yiming Yang, and Lei Li. On the sentence embeddings from pre-trained language models. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online.Association for Computational Linguistics, 2020.
本期责任编辑:冯骁骋
理解语言,认知社会
以中文技术,助民族复兴



