AI学会理解物理力学,机器像人更进一步 | 清华学神在MIT新研究

| 全文共1887字,建议阅读时2分钟 |
转载自公众号:量子位
微信号: QbitAI
作者:问耕
机器能自行理解我们这个物理世界的基本规则么?答案是能。
多年以来,麻省理工学院(MIT)的研究人员一直在寻求解释和复制人类智能,而他们最近的研究成果,是如何让AI智能体拥有认知世界的基本能力。
即:学会分辨不同的对象,以及推断它们如何受到物理作用力的影响。
这包括几个方面。首先是看到图片后,能脑补其中物体的三维形状;其次是判断物体的物理特性,例如质量和摩擦力等;然后是推断随着时间推移,这些它们会如何被物理作用力改变,比方会发生何种位移。
在这个方向上,MIT博士生吴佳俊和团队一起发表了四篇研究论文,这四篇论文入选了刚刚结束的NIPS,而且有两篇被选为spotlight。
其中三篇论文谈及如何从视觉和听觉数据中,推断出物体的物理结构。另外一篇,则是预测这些物体会会如何发生变化。
“总而言之,我们已经能够让机器像人类一样,掌握越来越多对物理世界的基本理解”,吴佳俊的导师Josh Tenenbaum教授表示。
脑补
首先要解决的问题是,如何正确认知这个世界。
挑战在于,如何构建一个神经网络模型,能够基于给定的二维图片,脑补出隐藏在视线之外的物体形状,最终还原构建出一个三维图像。
这需要模型能看透物体间的相互遮挡,滤除混杂期间的视觉纹理、反射和阴影,推断看不见的地方究竟是什么形状等等。
显然这是一个复杂的问题。参与这项研究的不止MIT学者,还有来自DeepMind、上海科技大学、上海交通大学的各路高手。
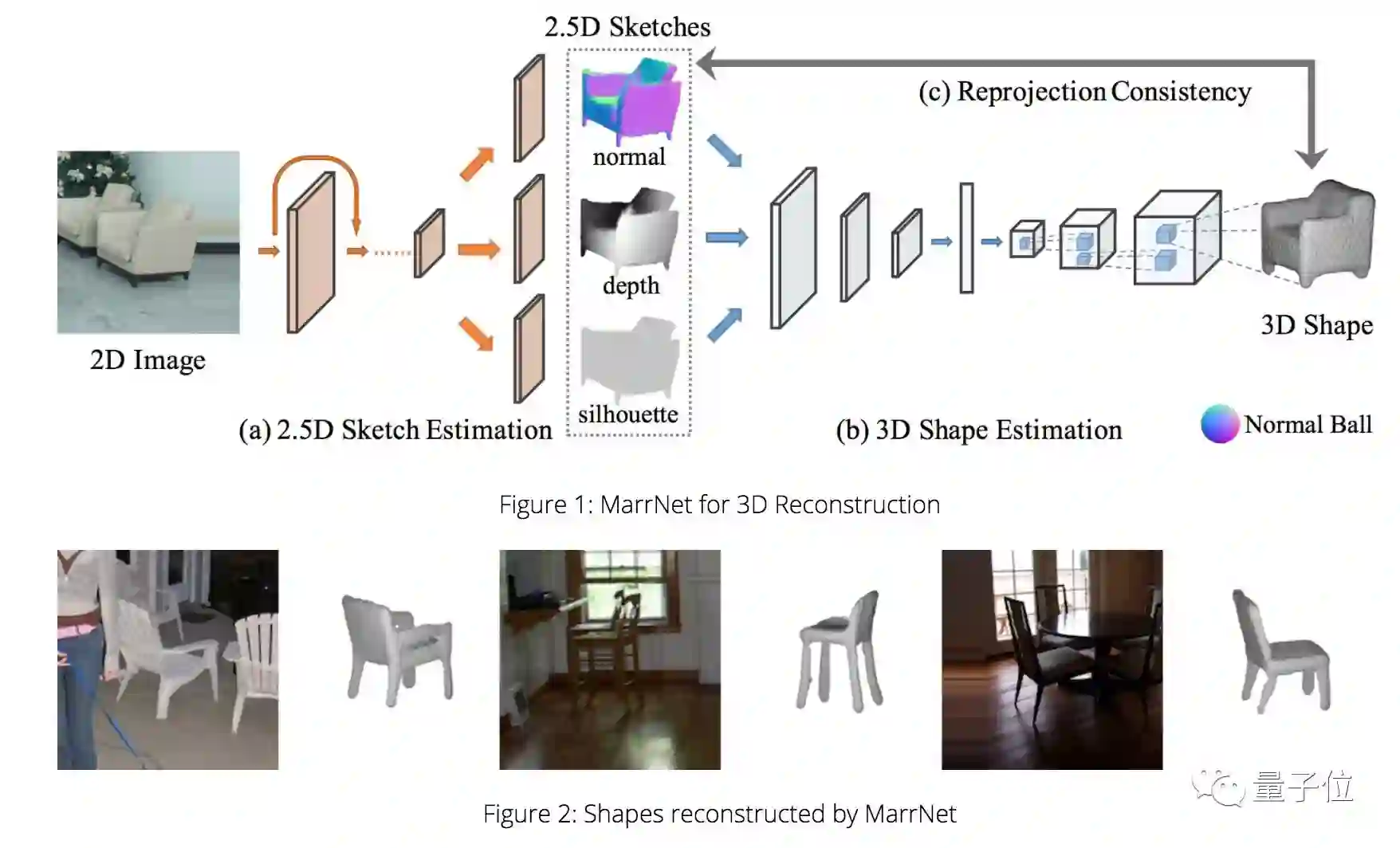
这些研究基于MIT神经科学家大卫·马尔(David Marr)的理论。这位英年早逝的科学家认为,在解释一个视觉场景时,大脑首先从观察角度建立对象的2.5D草图,然在在此基础上,大脑继续推断出物体完整的三维形状。
这不是一件易事。
吴佳俊和同事们为了训练神经网络,会首先建立一个三维场景模型,然后再生成一张二维图片。整个过程就像拍摄动画电影似的。一旦有了数据,就能让AI开始自学如何基于二维图片,脑补出三维场景。
还有更有意思的挑战。
比方,听声脑补。在另一篇论文中,他们训练了一个系统,通过物体被丢弃时发出的声音,推断物体的形状、材质以及跌落的高度。
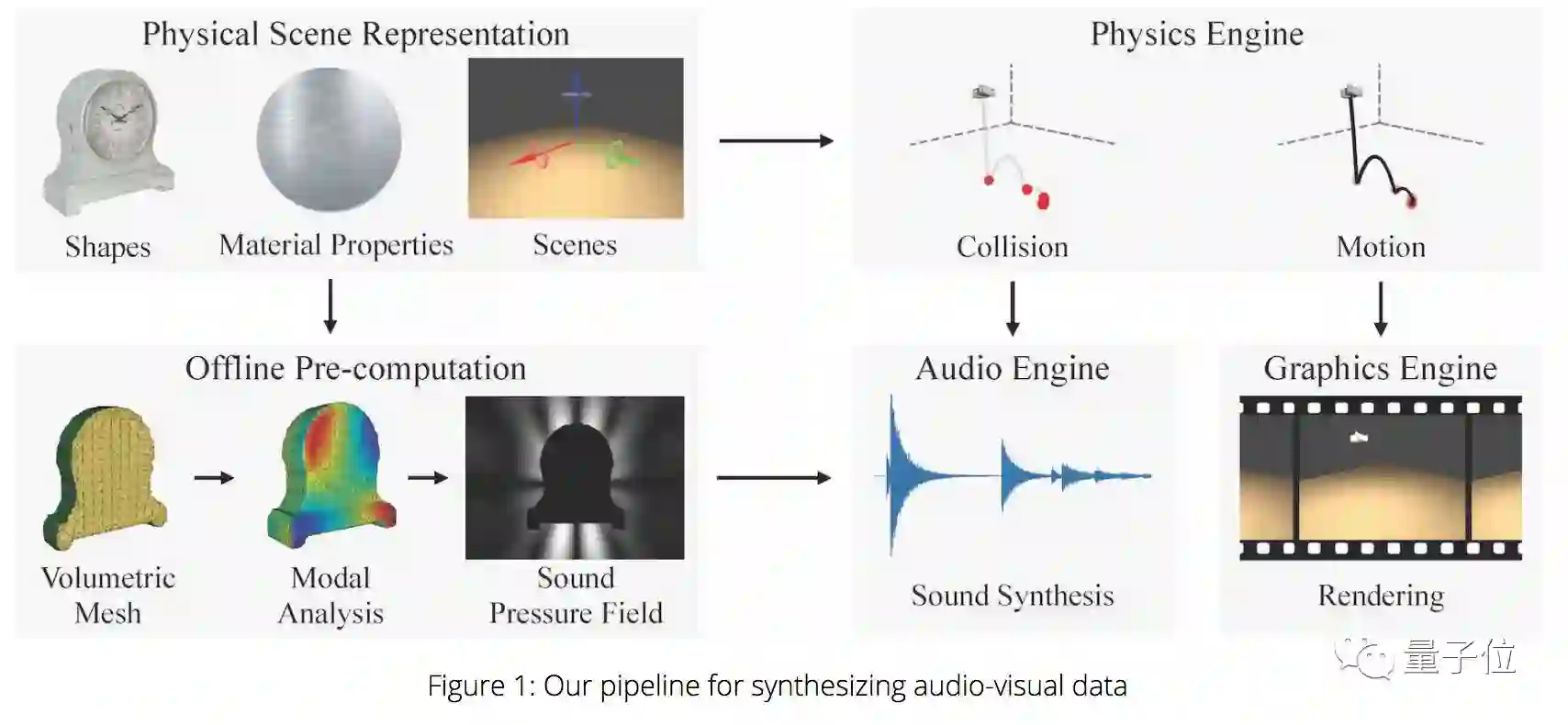
物理
神经网络已经学会如何脑补一个三维世界,现在,是时候让AI学习如何像人类一样,掌握对真实世界物理作用力的直观理解了。
研究人员一共交待了两项任务。
其一,是估计台球的运行速度,并据此预测台球(们)发生撞击后,后续的运动情况。其二,是分析堆叠的方块静态图,并据此判断这堆方块是否会掉落,以及会落在何处?
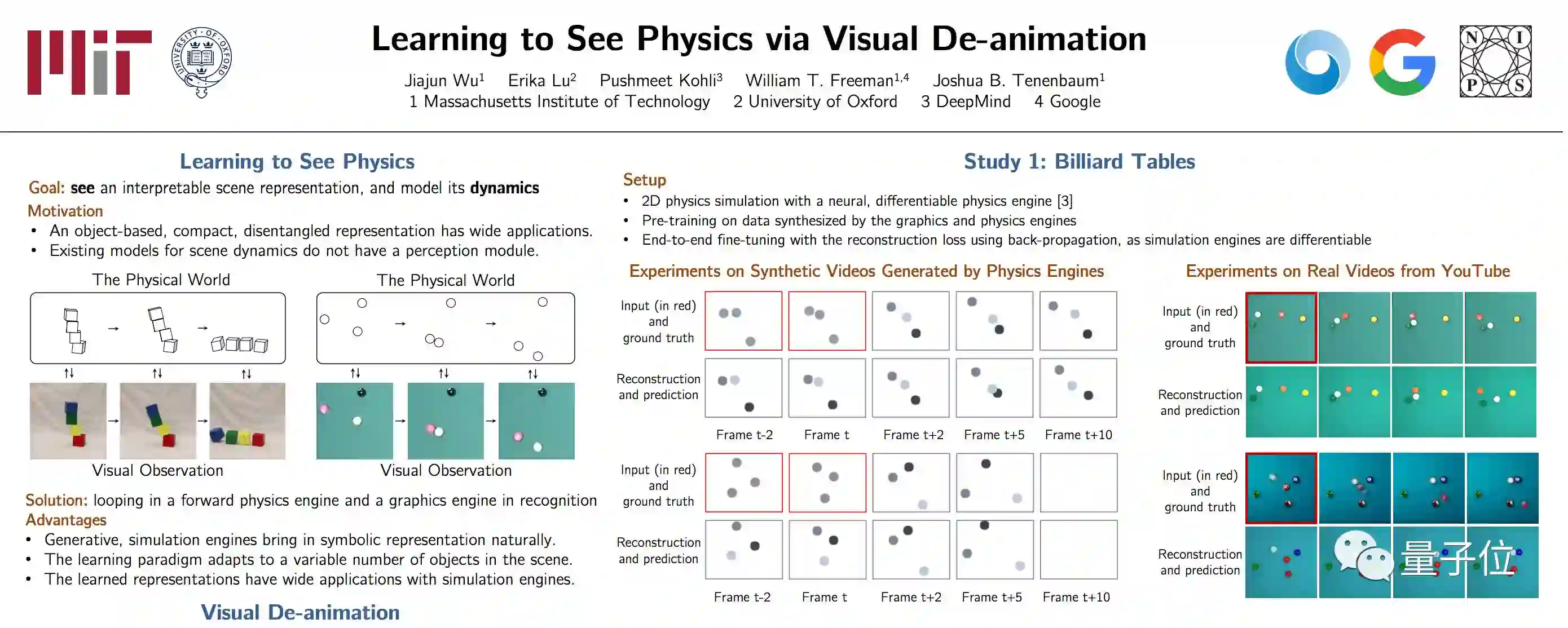
吴佳俊为此开发了一种称为场景XML的表示语言,可以定量描述视觉场景中物体的相对位置。神经网络首先学习使用这个语言输入数据,然后把这个描述提供给一个物理引擎,这个引擎负责基于物理作用力进行建模。
物理引擎最终完成台球和方块运动的预测之后,信息被发送给图形引擎,最终形成一张预测图片。这张图片会与真实场景的物理作用结果进行比较。
在测试中,MIT的研究超过了前人的成果。

“他们使用了物理工具来训练生成模型”,南加州大学计算机科学助理教授Joseph Lim表示:“这个简单而优雅的想法与最先进的深度学习技术结合,在与解释物理世界相关的多项任务中展现了非常棒的结果”。
上述内容主要源自MIT News,原文地址:
http://news.mit.edu/2017/computer-systems-predict-objects-responses-physical-forces-1214
吴佳俊
上面提及的四篇论文中,吴佳俊都有参与,其中两篇是作为第一作者。
前面已经提到,吴佳俊现在是MIT的博士生。他的导师是Bill Freeman教授Josh Tenenbaum教授。吴佳俊的研究方向主要为计算机视觉、机器学习和计算认知科学。
吴佳俊本科毕业于清华大学交叉信息研究院,导师为屠卓文教授。

2010年9月,18岁的吴佳俊通过全国信息学奥林匹克竞赛从上海华东师范大学第二附属中学保送至清华大学。
就读清华期间,吴佳俊一度成为话题人物。当时吴佳俊正参选2013年清华大学本科生特等奖学金,他的一份个人履历引起了广泛的关注。其中最受关注的一项成就是:顶级会议CVPR 2014审稿人。
此后,吴佳俊时常被被外界冠以超强履历、新一代学神等形容词。
喜欢我们就多一次点赞多一次分享吧~
有缘的人终会相聚,慕客君想了想,要是不分享出来,怕我们会擦肩而过~
《【调查问卷】“屏幕时代,视觉面积与学习效率的关系“——你看对了吗?》



