YesOfCourse团队在Kaggle文本匹配竞赛中获得优异成绩

本次竞赛由全球最大的在线知识平台Quora主办,Kaggle竞赛平台承办。Quora为本次比赛提供了百万级别的带有标签信息的文本匹配数据集,以期望参赛选手能够准确的判断一组问题是否具有相同的语义,从而帮助Quora用户更有效地从海量数据中找到所需要的问题。该项赛事吸引了来自全球各地相关领域研究者组成的数千只队伍,其中包括Microsoft、IBM等顶级IT公司以及MIT、UCL、UMass、清华等知名高校和研究机构。
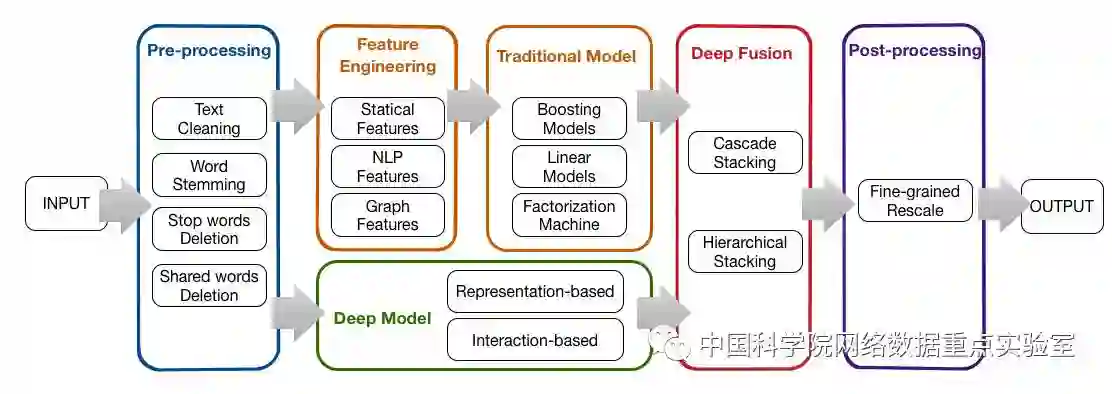
YesOfCourse团队将问题转换为预处理、特征工程、单模型构建、多模型整合以及后处理等五个主要步骤并分别进行优化,如下图所示。在预处理阶段,将原始文本通过词干还原、词性抽取、停用词去除等多种文本处理方式生成多通道数据以从多角度进行特征提取和模型构建。在特征构建阶段,除了构建基本的统计特征,自然语言句法语法特征,分布式文本表达特征以外,还利用问题共现关系构建了关系图网络,并通过图连接,图节点等信息抽取得到相应特征,有效的利用了其他维度的信息来帮助完成自然语言处理的问题。单模型主要包含两个方面:一方面利用深度学习模型,其中主要包括实验室自主研发的深度文本匹配模型(相关模型由TextNet[2]实现):MatchPyramid[3]、MV-LSTM[4] 和MatchSRNN[5]等;另一方面利用传统的机器学习模型如GBDT,分解机模型,线性模型等。最终,通过我们提出的Deep Fusion方法,将大量不同类别的模型结果进行整合,利用多模型之间的差异性和互补性进一步提升结果。除此之外,团队还开发了FeatWheel轻量级机器学习流程框架,用以快速、有效地完成在中小数据级上的实验,不仅方便管理各种不同版本之间的迭代,同时还有有效的简化了数据集划分,特征整合等多个关键步骤。基于以上工作,YesOfCourse团队将结果(交叉熵误差)从0.3提升至0.11768,最终取得了全球第4名的成绩。
Refenrence:
[1] https://www.kaggle.com/c/quora-question-pairs
[2] https://github.com/pl8787/textnet-release
[3] Pang L, Lan Y, Guo J, etal. Text Matching as Image Recognition[C]. Thirtieth AAAI Conference onArtificial Intelligence. 2016.
[4] Wan S, Lan Y, Guo J, etal. A deep architecture for semantic matching with multiple positional sentencerepresentations[C]. Thirtieth AAAI Conference on Artificial Intelligence. 2016.
[5] Wan S, Lan Y, Xu J, etal. Match-SRNN: Modeling the Recursive Matching Structure with Spatial RNN[C]. Twenty-FifthInternational Joint Conference on Artificial Intelligence (IJCAI-16). 2016.
[6]https://github.com/HouJP/kaggle-quora-question-pairs



