最新综述 | 图数据挖掘中的算法公平性
作者:董钰舜
单位:弗吉尼亚大学
图数据挖掘算法已经在很多领域得到应用,但大多数图数据挖掘算法都没有考虑到算法的公平性。在本篇综述中,我们首先系统梳理了图数据挖掘领域内常见的算法公平性的定义和对应的量化指标。在此基础上,我们总结出了一个图数据挖掘算法公平性的分类法,并对现有提升公平性的方法进行了讨论。最后,我们整理了可以用于图数据挖掘中算法公平性研究的数据集,也指出了现有的挑战和未来的工作方向。
论文链接:https://arxiv.org/abs/2204.09888
在不同的工作中,算法公平性的定义可能是不同的。同时,提升算法公平性的方法也与公平性的定义相互耦合。如果没有系统地认识每一类公平性和对应的提升方法,研究者和工程师们很难针对一类图数据挖掘算法的公平性问题找到有效的解决方案。这很大程度上阻碍了这些提升算法公平性的方法在真实场景中的应用。为了解决这个矛盾,我们在本篇综述[2]中总结了常见的算法公平性的定义以及对应的量化指标。为了帮助研究者系统地认识现有方法,我们也对常用的实现图数据挖掘公平性的方法进行了分类和详细介绍。我们还汇总了可供图数据挖掘公平性研究的数据集,并指出了现有的挑战和未来的方向。
1. 图数据挖掘中算法公平性的定义
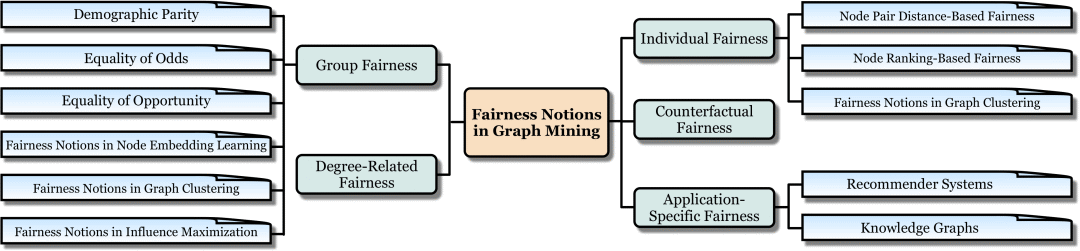
1.1 集体公平性
在一些围绕人(如电子商务平台的用户)的图数据挖掘场景中,数据中的信息可能会包含人的敏感特征(sensitive attributes),比如性别[3]。在这种情况下,现有的图数据挖掘算法可能会产生带有取决于敏感特征的有偏见的预测。在图数据挖掘领域,集体公平性大致要求算法不应在预测结果中展现出敏感特征上的偏见。常见的集体公平性的定义包括人口平等(Demographic Parity),几率平等(Equality of Odds),机会平等(Equality of Opportunity)。此外,还有一些集体公平性的定义是与具体的图数据挖掘算法耦合的。比如,在节点表示学习,图聚类和影响力最大化算法中,图数据挖掘算法的集体公平性都有不同的定义。更多内容见综述原文。
1.2 个人公平性
当图数据挖掘算法对人给出预测结果时,个人公平性大致要求如果两个人很相似,那他们对应的预测结果也应当相似。这种相似性可以以不同的方式量化,其中直接采用两个人在特征空间中的距离(距离越大,相似性越低)是最为广泛使用的方法。更多内容见综述原文。
1.3 反事实公平性
目前大多数公平性标准从统计学出发,缺乏因果性角度的定义。近年来,一种基于因果推断的公平性定义——反事实公平性逐渐引起很高的关注。反事实公平性要求当个人的敏感特征被改变时,算法针对此人做出的预测不变。在图挖掘领域,考虑到图节点之间的因果关系干涉,反事实公平性往往面临更复杂的挑战。更多内容见综述原文。
1.4 度公平性
在很多节点级的图数据挖掘算法中,算法的预测质量(utility,比如预测准确率)很大程度上被该节点的度(degree)决定。比如,在一个图(graph)中,度高的节点有更多的链接(link)和相邻节点(neighbor),图数据挖掘算法也就更容易地捕捉到这些节点的关键信息,从而给出更准确的预测结果。度公平性大致要求对度不同的节点,图数据挖掘算法应该给出相似质量的预测结果。更多内容见综述原文。
1.5 应用中的公平性
这里我们主要探讨两类应用场景中图数据挖掘算法公平性的定义,即推荐系统和知识图谱。在推荐系统中,用户公平性和流行公平性是最为广泛研究的两类算法公平性。其中,前者大致要求推荐算法应该为不同的用户产生相似质量(比如对用户偏好的符合程度)的推荐结果,而后者主张广泛受欢迎的物品在推荐系统中不应该主导绝大部分的推荐结果,否则一些冷门的物品将极少被推荐给用户[4]。在知识图谱中,社会性公平是一种被广泛研究的算法公平性。它大致要求基于知识图谱的图数据挖掘算法不应该被各种不公平的社会观念影响导致产生有偏见的结果(如有偏见的知识图谱实体表示)。更多内容见综述原文。
2. 提升图数据挖掘算法公平性的方法
在本篇综述中,我们将图数据挖掘中实现算法公平性的方法划分为以下六类。
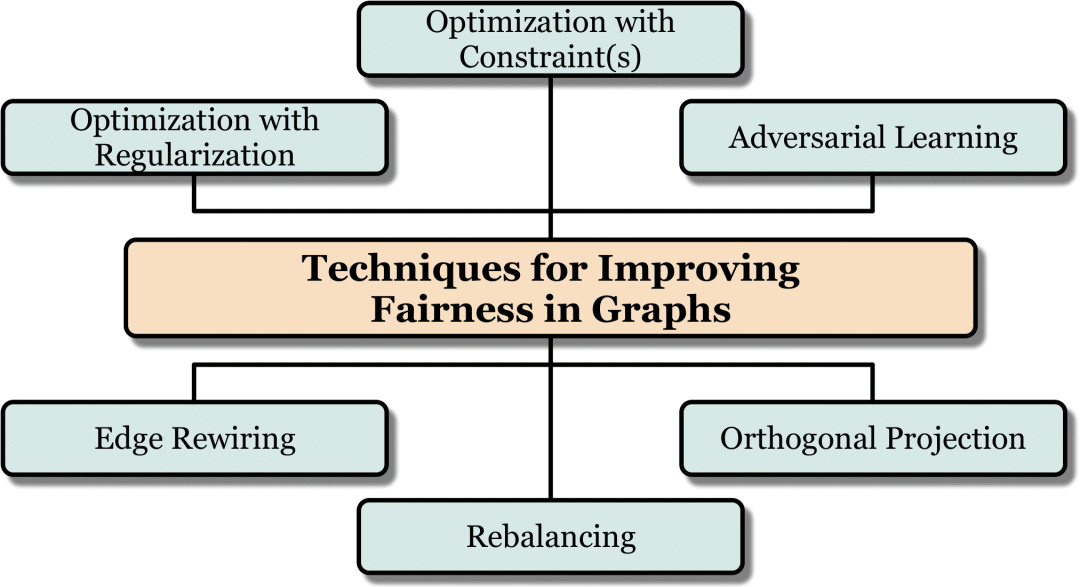
2.1 正则化
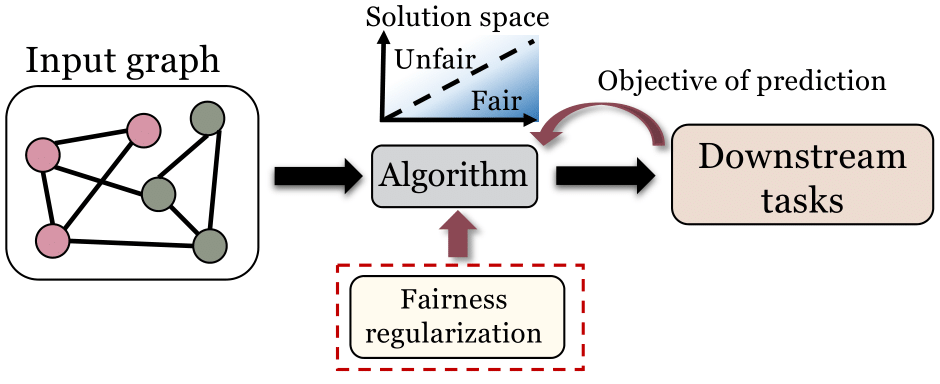
对于有目标函数的图数据挖掘问题,为目标函数设计一个正则项来实现更优的公平性是一个常见的提升算法公平性方法。该方法在诸多图数据挖掘算法以及与图数据相关的应用场景中均取得了良好的效果。我们在综述中详细介绍了正则化如何被用于提升集体公平性,个人公平性,反事实公平性。我们还介绍了在推荐系统和知识图谱场景中,正则化如何被应用以提升算法公平性。
2.2 约束优化
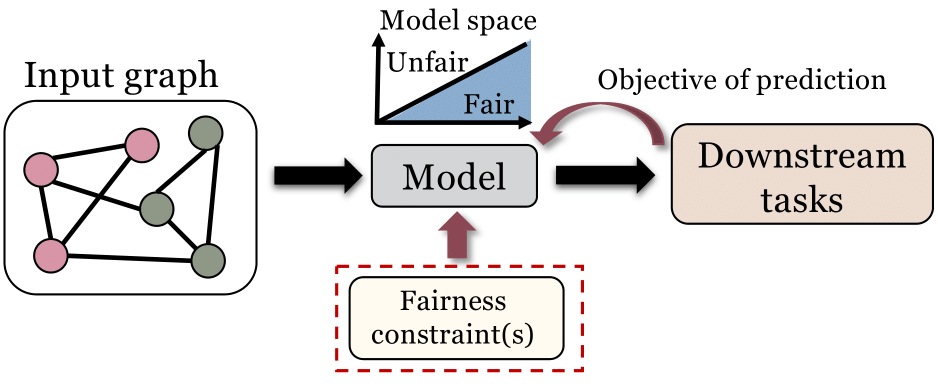
图4. 约束优化方法的基本框架
很多图数据挖掘算法是基于优化问题来的。对于这类算法,针对优化设计特殊的约束条件以实现算法公平性也是一个常用的方法。比如,在图谱聚类算法中,[5]要求图谱聚类算法的结果应该满足:每一个聚类中个体数量在全体中的占比应该与从属于任意集体的成员在本聚类中数量的比例相近。我们在综述中详细介绍了约束优化如何被用于提升集体公平性和个人公平性。
2.3 再平衡
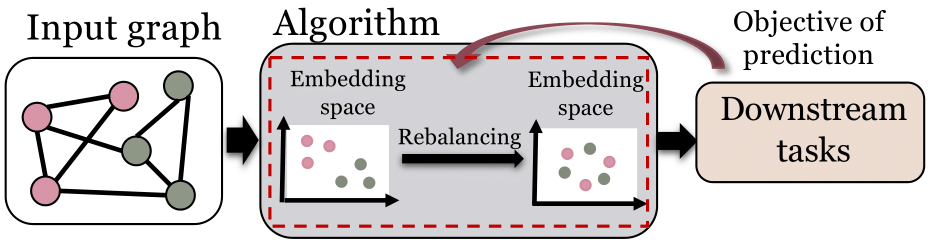
图5. 再平衡方法的基本框架
再平衡也是一种图数据挖掘中实现算法公平性的常用方法。一般情况下,再平衡可以通过人为修正一些算法过程中存在的概率分布来实现更为公平的算法结果。比如,随机游走算法(random walk)学到的节点表示常常是有偏见的,其中一个原因是拥有某些特定敏感特征的人可能在网络中占据了大部分节点的位置。可以预见,这将导致随机游走算法在运行的大部分时间步(time step)都停留在拥有这些敏感特征的人所占据的节点位置上。这种问题所导致的偏见就可以被再平衡策略很好的处理,比如Fairwalk [6]和Crosswalk [7]。我们在综述中详细介绍了再平衡如何被用于提升集体公平性和度公平性。同时,我们也介绍了再平衡如何被应用于推荐系统场景中来提高算法公平性。
2.4 对抗学习
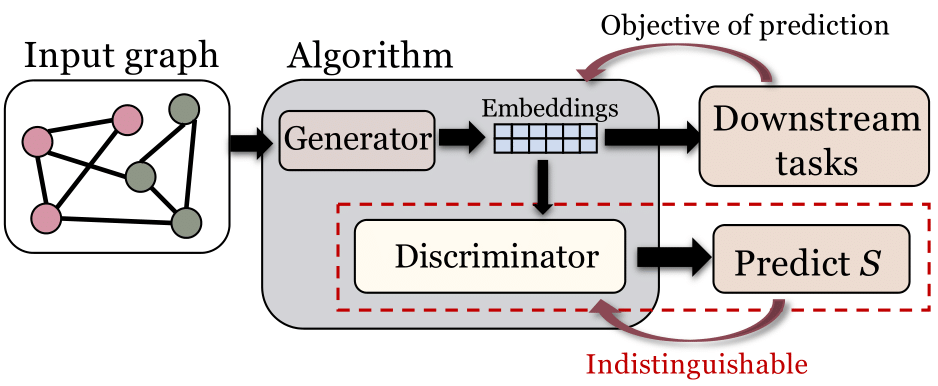
图6. 对抗学习方法的基本框架
对抗学习是应用非常广泛的提升图学习算法集体公平性的方法。这种方法大致要求即使通过学习,经过特定设计的神经网络模型也无法基于某些输出(比如节点表示和预测结果)准确预测个体所属的集体,也就是他们的敏感特征。在这种情况下,这些输出就被认为是与敏感特征相互解耦的。[1]和[3]都属于这类方法。我们在综述中详细介绍了再平衡如何被用于提升集体公平性,以及这种方法在知识图谱中的应用。
2.5 链接修正
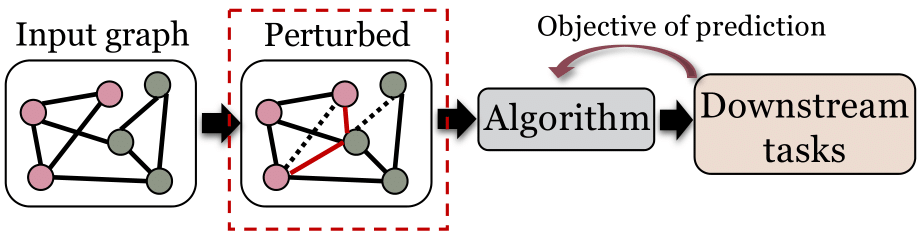
现有研究已经证明,算法的输入图数据本身就可能是包含偏见的,而这种偏见可能被图数据挖掘算法在预测结果中进一步放大。因此,直接修改图数据以减少数据本身包含的偏见成为了提高算法公平性的重要方法,其中又以修改图数据的链接(link)应用最为广泛。在本篇综述中,我们详细介绍了链接修正如何被用于提升集体公平性和个人公平性。我们也介绍了这种方法在推荐系统中的应用。
2.6 正交投影
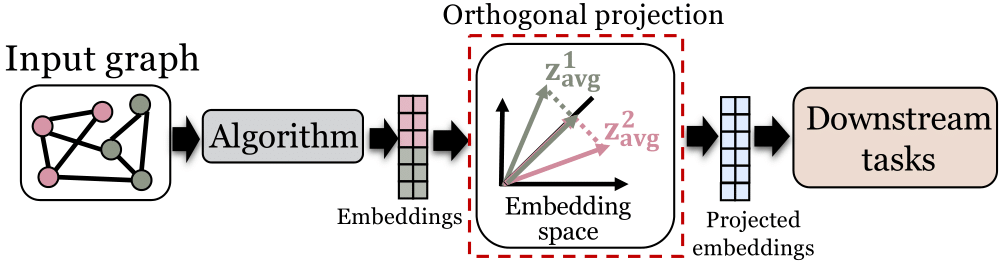
正交投影方法的基本理念是:如果能找到一个与偏见正交的超平面,那么只需要保证图数据挖掘算法的输出始终处在这个超平面内,就可以在理论上保证输出与偏见线性不相关。在本篇综述中,有关正交投影的介绍主要围绕节点表示学习展开:我们详细介绍了正交投影如何被用于提升节点表示学习算法的集体公平性。
3. 未来研究展望
本篇综述主要在五个方面讨论了现有工作的局限性和未来的工作方向,它们是:(1)为图数据挖掘定义新的公平性概念;(2)同时在图数据挖掘中实现多种公平性要求;(3)平衡图数据挖掘模型的公平性和效用;(4)解释图数据挖掘中偏见产生的原因;(5)图数据挖掘算法在公平方面的鲁棒性。详见综述原文。
4. 引用
[1] Dai et al. Say no to the discrimination: Learning fair graph neural networks with limited sensitive attribute information. WSDM, 2021.
[2] Dong et al. Fairness in Graph Mining: A Survey. arXiv, 2022.
[3] Bose et al. Compositional fairness constraints for graph embeddings. ICML, 2019
[4] Nguyen et al. Exploring the filter bubble: the effect of using recommender systems on content diversity. WWW, 2014.
[5] Kleindessner et al. Guarantees for spectral clustering with fairness constraints. ICML, 2019.
[6] Rahman et al. Fairwalk: Towards fair graph embedding. IJCAI, 2019.
https://arxiv.org/abs/2204.09888
团队简介:
该综述论文由美国弗吉尼亚大学(UVa)李骏东助理教授团队完成,其他主要贡献作者包括董钰舜,马菁和陈諃助理教授。董钰舜是UVa的三年级博士生,他目前的主要研究集中在图数据挖掘算法,尤其是图神经网络算法中的公平性问题上。马菁是UVa的四年级博士生,主要从事因果推断与机器学习、图挖掘方面的研究。陈諃是UVa Biocomplexity Institute and Initiative的研究助理教授,主要从事复杂网络方面的研究。李骏东助理教授对数据挖掘,机器学习以及因果推断领域有着广泛的研究兴趣。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
