最新综述 | 可信图神经网络: 隐私, 鲁棒性, 公平和可解释性

摘要:对于可信图神经网络(Trustworthy Graph Neural Networks)在隐私(privacy),鲁棒性(robustness), 公平(fairness)和可解释性(explainability) 的研究工作,我们进行了系统的梳理和讨论。对于可信赖所要求的各个方面,我们将现有概念和方法归类并提炼出各类的通用框架。同时我们也给出了代表性工作和前沿方法的具体细节。对于未来的工作方向,我们也进行了探讨。
综述论文链接:https://arxiv.org/pdf/2204.08570.pdf
在现实应用当中,大量的数据列如交通网络,社交网络,知识图谱乃至蛋白质结构,都是以图的形式存在的。图神经网络(GNNs)将深度学习拓展到图结构数据的处理和建模。典型的图神经网络会汇聚邻居节点(neighbor node)的信息来增强目标节点(target node)来获取更强的特征。这种被称作message-passing的机制使得图神经网络在处理图结构数据上取得了巨大成功并被广泛应用到日常生活。例如,Pinterest就应用了GNNs在他们的图片推荐系统当中。一些将GNNs应用到信用评估等金融领域的工作也已开展。但是正如深度学习那样,GNNs在于可信赖性方面仍然存在很多问题:
-
在GNNs的应用中, 隐私和 鲁邦性并不能得到保证。黑客可以对基于GNNs的服务进行隐私攻击或者对抗攻击。如通过GNNs获得的node embedding,攻击者可以推断用户的私人信息。他们也可以采取各种方式如添加虚假联结去欺骗图神经网络模型。比如应用在金融风险评估的GNNs就可能被攻击,对个人,企业和社会带来重大损失。 -
图神经网络本身也有在 公平性和 可解释性的缺陷。现有研究已经证明图神经网络的结构会进一步加强隐藏在数据中的偏见,从而导致做出对年龄、性别、种族等带有歧视的决策。另一方面,由于模型深度导致的高度非线性, GNNs模型给出预测难以被理解,这大大限制了GNNs在实际场景中的应用。
以上的这些问题都阻碍了GNNs在高风险场景如金融和医疗领域进一步的发展。因此可信赖图神经网络的构建已经成为了热门方向。在我们的综述中 [6],我们对已有的可信赖图神经网络在隐私,鲁棒性,公平性和可解释性方面进行了总结归纳,并展望了进一步的工作方向。接下来在这篇博客中,我们将简要的介绍综述的框架及所包含的具体方向。
隐私(Privacy)

Figure 1. 关于隐私章节的综述结构.
模型训练集中的隐私信息可能会在发布的模型或者提供的服务泄露。然而现有的综述论文多以讨论在图像和文本这类数据的隐私问题,其中讨论的方法难以拓展到图数据结构和采用message-passing架构的图神经网络。因此我们对隐私攻击(privacy attacks)以及图神经网络的隐私保护(privacy-preserving GNNs)进行了概述总结。囊括的概念和方法都列在图1之中。首先,我们对隐私攻击方法总结出了统一的框架。然后,我们详细介绍了四种隐私攻击:Membership Inference Attack, Reconstruction Attack, Property Inference Attack和Model Extraction Attack。至于图神经网络的隐私保护,我们在综述中按照采用的方法将其归类为差分隐私(differential privacy),联邦学习(federated learning)和对抗隐私保护(adversarial privacy preserving)。部分在文章讨论过得方法也列举在图1之中。对于更的技术细节以及相关方法请见于综述论文第三章。这一章节还包含了不同领域的数据集以及图神经网络隐私保护的实际应用。同时我们发现对于一些类型的隐私攻击如Property Inference Attack及Model Extraction Attack现在都缺乏行之有效的防御办法。因此对于不同的隐私攻击的防御会是一个未来的研究方向。其他的未来研究方向也在文章中进行了讨论。更多细节请见原文。鲁棒性(Robustness)
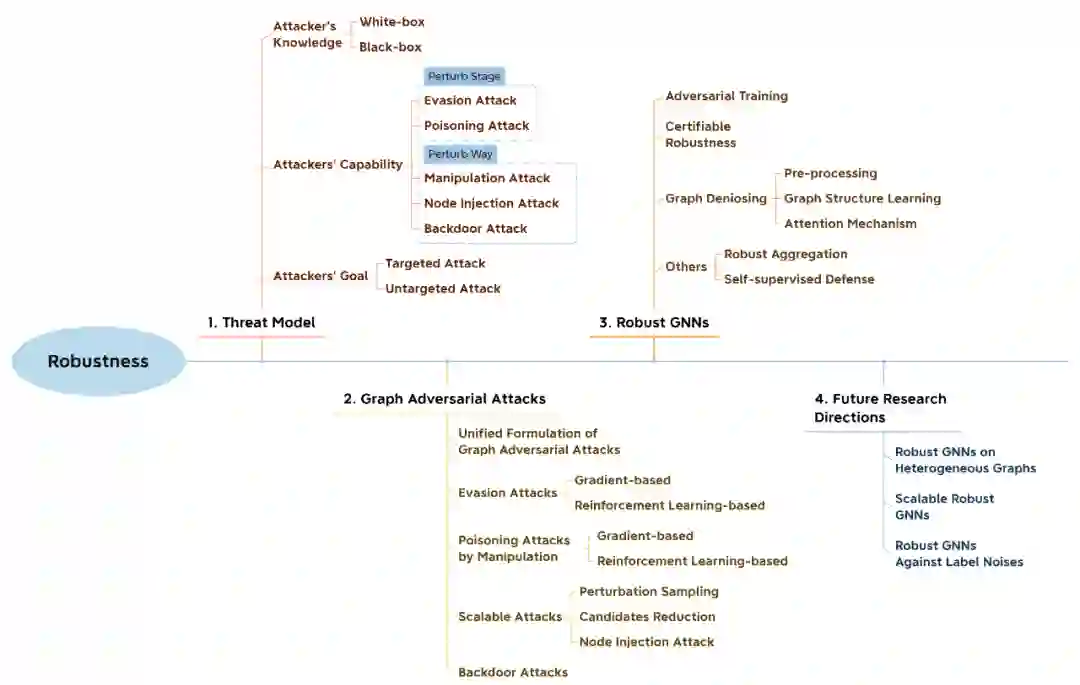
Figure 2. 关于鲁棒性章节的综述组织结构.
鲁棒性是可信赖模型的另一个重要方面。由于message-passing机制和图结构,GNNs可能会被节点特征和图结构上的对抗性扰动影响。例如,诈骗犯可以通过创造和一些特定高信用用户的交易来逃过基于GNNs的诈骗检测。所以研发鲁邦的图神经网络对于一些安全风险较高的领域如医疗和金融是十分有必要的。
现在已有一些综述文章讨论在图学习上的鲁邦性。因此,我们专注于讨论在这个领域内新兴的研究方向如大规模攻击(scalable attack),图后门攻击(graph backdoor attack)和最近的提出的防御方法。扰动采样(perturbation sampling)和减少候选扰动(perturbation candidate reduction)便是对已有方法进行改进,从而实现对大规模网络攻击。另外,节点插入攻击(node injection attack)作为添加扰动的时间复杂度与图规模线性相关的方法也具备对大规模网络攻击的潜力。至于图后门攻击,已有方法较少,我们对其进行了细致的介绍。
对于图对抗攻击的防御方法,如图2所示,我们将其归类为:对抗训练(adversarial training),可验证鲁棒性(certifiable robustness),图去噪(graph denoising)及其他方法。在这些方向中,基于自监督(self-supervision)的方法未在以往综述中被讨论过。因此我们讨论了如SimP-GNN [1]的一些基于自监督的防御方法。对于其他的方向,我们则讨论了些最新的进展,比如可以同时处理标签稀少和对抗攻击的RS-GNN [2]。关于图神经网络鲁棒性的未来研究方向也包含在综述当中,详情请见综述第四章。
Figure 3. The organization of fairness section (Sec.5) in our survey.
公平(Fairness)

Figure 3. 关于公平性章节的综述组织结构.
我们最近的研究 [3] 表明GNNs中的message-passing机制相较于多层感知机(MLP)会加剧数据中的偏见。这也证明了针对图神经网络实现公平性是十分有必要的。最近有很多研究保证GNNs满足不同公平性标准的工作涌现。因此我们对与这些工作进行了系统的回顾和归纳,整体的结构可参见图3。
首先我们介绍了两类可能存在于图结构数据的偏见:一类是广泛存在各类数据如表格,文本和图数据的偏见;另一类则是图结构数据所特有的偏见。对于算法公平性的研究,其中一个最重要的问题就是如何定义和量化算法公平与否。所以我们还列举出被GNNs公平性文献广泛采用的定义。这些公平性的定义多数适用于各种数据结构。只有Dyadic fairness是为链接预测任务设计,仅适用于图结构数据。
对于实现GNNs公平性的算法,我们将其分类为对抗去偏(adversarial debiasing),公平性约束(fairness constraints)以及其他方法。部分我们讨论的代表性方法在图三当中也有列举。在对抗去偏和公平性约束的已有方法的介绍中,我们首先分别归纳了其目标函数的统一形式。关于具体方法的各自确切目标函数也一一进行了介绍。由于需要用户的隐私信息用于训练和验证公平图神经网络,可以用图神经网络公平性研究的数据集较难获得。因此我们还列举了各应用领域可用的数据集来帮助未来的研究。
可解释性(Explainability)
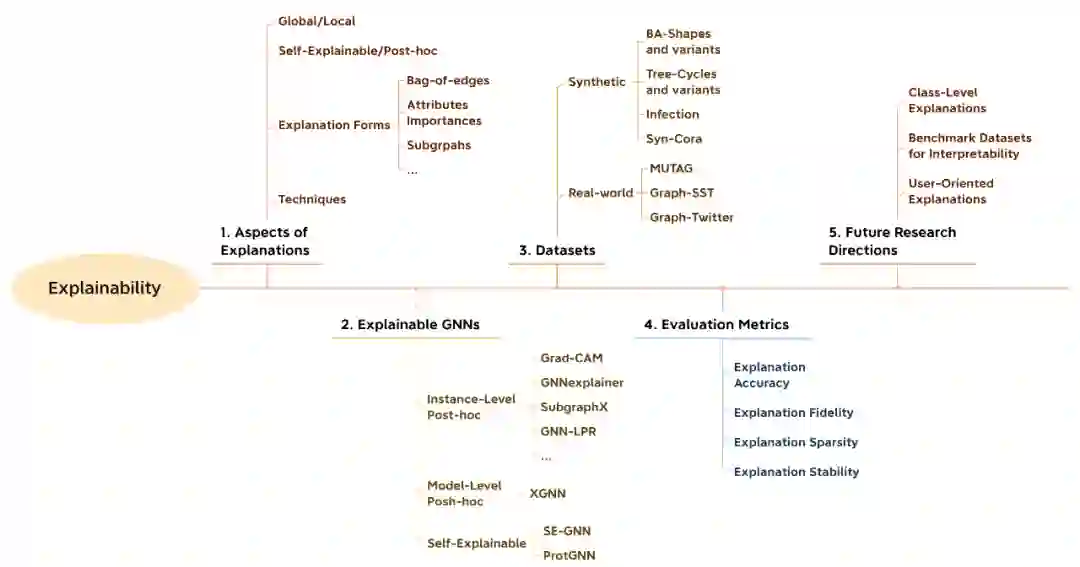
Figure 4. 关于可解释性章节的综述组织结构..
由于复杂图结构的离散型和高度的非线性,再加上message-passing机制在GNNs中的应用,图神经网络普遍缺乏可解释性。而开发可解释图神经网络(explainable GNNs)是十分关键的。因为提供的解释可以让参与者更信任图神经网络模型所做的预测。并且提供的解释可以用来了解模型所学到的知识,据此我们可以评估现有模型是否带有偏见或者已经被对抗攻击影响。因此已经有一些工作开展了可解释GNNs的研究,我们在这里则对其进行了总结性回顾。对于可解释GNNs的讨论框架可见于图4。其中我们首先对可解释性的应该考虑的各个方面进行了探讨。之后我们对已有的解释GNNs的方法分为 实例级事后(instance-level post-hoc),模型级事后(model-level post-hoc)以及自解释方法(self-explainable)。值得强调的是,其中的self-explainable GNNs是一个未被讨论的新方向。因此我们详述了self-explainable GNNs如SE-GNN [4] 和ProtGNN [5] 的技术细节。对于其他种类的方法,我们根据其采用的方法进一步分为多个子类。由于在现实世界的图中很难获得可以作为检验标准的解释,因此数据集及其评估指标也是可解释性研究的一大挑战。虽然已有人造数据集以及部分现实数据集被应用,但是创造可解释性的基准数据集仍会一个重要的研究方向。更多内容详见我们的综述原文。
引用
[1] Jin, Wei, Tyler Derr, Yiqi Wang, Yao Ma, Zitao Liu, and Jiliang Tang. "Node similarity preserving graph convolutional networks." In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, pp. 148-156. 2021.
[2] Dai, Enyan, Wei Jin, Hui Liu, and Suhang Wang. "Towards Robust Graph Neural Networks for Noisy Graphs with Sparse Labels." Proceedings of the 15th ACM International Conference on Web Search and Data Mining. 2022.
[3] Dai, Enyan, and Suhang Wang. "Say no to the discrimination: Learning fair graph neural networks with limited sensitive attribute information." Proceedings of the 14th ACM International Conference on Web Search and Data Mining. 2021.
[4] Dai, Enyan, and Suhang Wang. "Towards Self-Explainable Graph Neural Network." Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021.
[5] Zhang, Zaixi, Qi Liu, Hao Wang, Chengqiang Lu, and Cheekong Lee. "ProtGNN: Towards Self-Explaining Graph Neural Networks." arXiv preprint arXiv:2112.00911 (2021).
[6] Dai, Enyan, Tianxiang Zhao, Huaisheng Zhu, Junjie Xu, Zhimeng Guo, Hui Liu, Jiliang Tang, and Suhang Wang. "A Comprehensive Survey on Trustworthy Graph Neural Networks: Privacy, Robustness, Fairness, and Explainability." arXiv preprint arXiv:2204.08570 (2022).
团队简介:该综述论文主要由宾夕法尼亚州立大学(PSU) 王苏杭助理教授团队协作完成。其他主要贡献作者包括戴恩炎和赵天翔。戴恩炎是来自PSU的第三年PhD学生,他目前的主要科研方向为Trustworthy Graph Neural Networks。赵天翔也是来自PSU的第三年PhD学生,他主要从事Weakly-Supervised Graph Learning方向的研究。王苏杭教授对于数据挖掘和机器学习有着广泛的兴趣,最近的研究主要集中于图神经网络的各个方向如Trustworthiness, self-supervision, weak-supervision 和 heterophilic graph learning,deep generative models和causal recommender systems。
英文版综述简介链接:
https://enyandai.github.io/posts/2022/04/trustworthy/


