可信图神经网络综述:隐私,鲁棒性,公平和可解释性

©作者 | 戴恩炎,赵天翔,王苏杭
单位 | 宾夕法尼亚州立大学
对于可信图神经网络(Trustworthy Graph Neural Networks)在隐私(privacy),鲁棒性(robustness),公平(fairness)和可解释性(explainability) 的研究工作,我们进行了系统的梳理和讨论。对于可信赖所要求的各个方面,我们将现有概念和方法归类并提炼出各类的通用框架。同时我们也给出了代表性工作和前沿方法的具体细节。对于未来的工作方向,我们也进行了探讨。

论文标题:
A Comprehensive Survey on Trustworthy Graph Neural Networks: Privacy, Robustness, Fairness, and Explainability
-
在 GNNs 的应用中, 隐私 和 鲁棒性 并不能得到保证。黑客可以对基于 GNNs 的服务进行隐私攻击或者对抗攻击。如通过 GNNs 获得的 node embedding,攻击者可以推断用户的私人信息。他们也可以采取各种方式如添加虚假联结去欺骗图神经网络模型。比如应用在金融风险评估的 GNNs 就可能被攻击,对个人,企业和社会带来重大损失。 图神经网络本身也有在公平性和可解释性的缺陷。现有研究已经证明图神经网络的结构会进一步加强隐藏在数据中的偏见,从而导致做出对年龄、性别、种族等带有歧视的决策。另一方面,由于模型深度导致的高度非线性, GNNs 模型给出预测难以被理解,这大大限制了 GNNs 在实际场景中的应用。
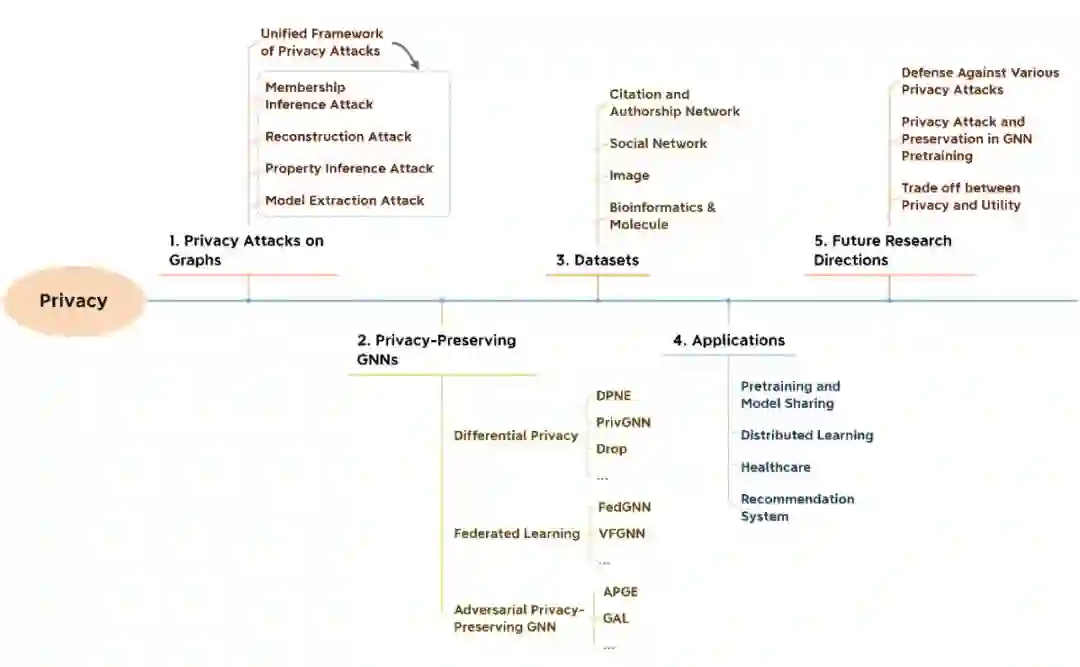

隐私(Privacy)
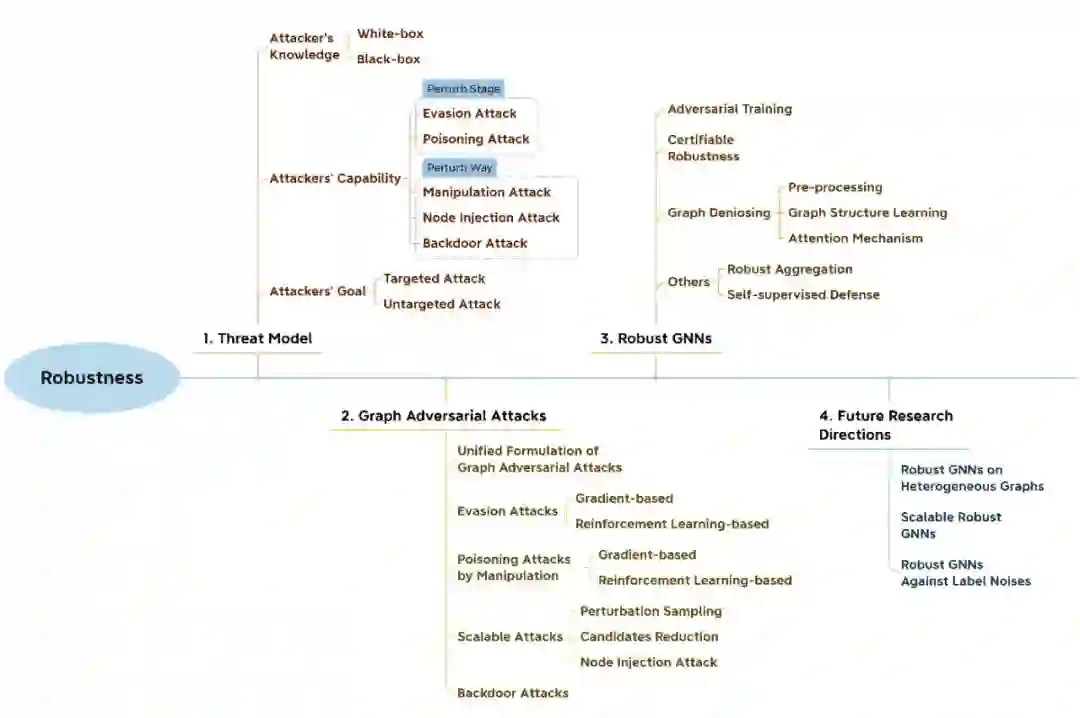

鲁棒性(Robustness)
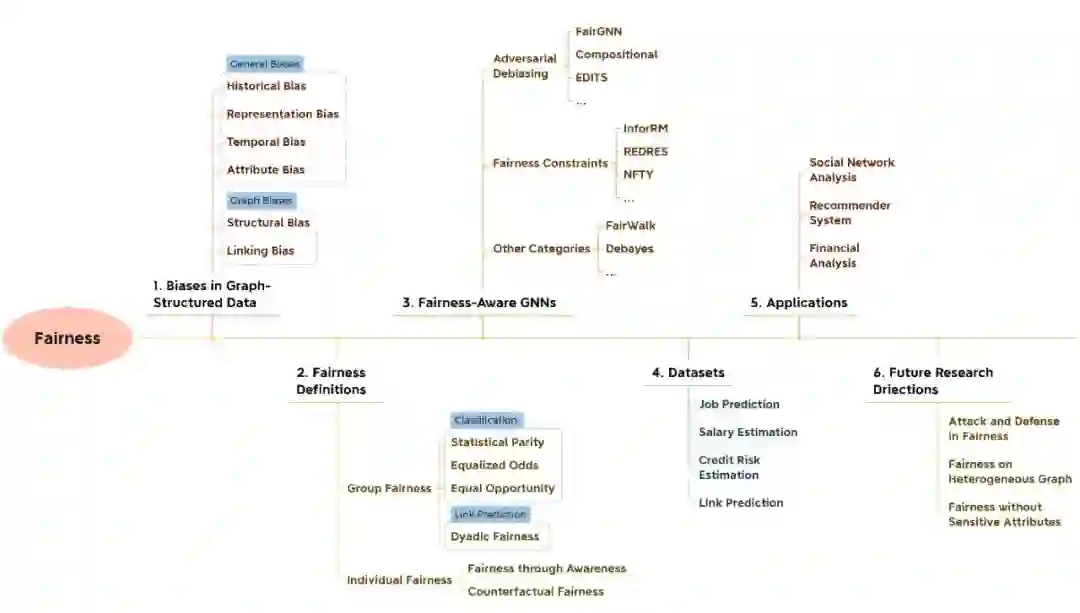

公平(Fairness)
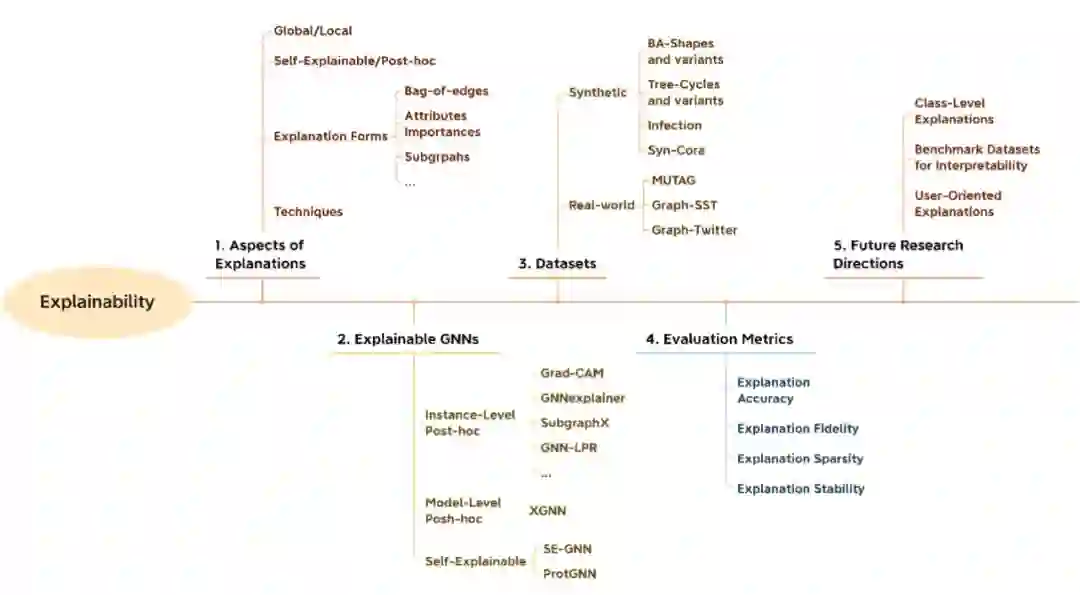

可解释性(Explainability)
► 团队简介
该综述论文主要由宾夕法尼亚州立大学(PSU)王苏杭助理教授团队协作完成。其他主要贡献作者包括戴恩炎和赵天翔。
戴恩炎是来自 PSU 的第三年 PhD 学生,他目前的主要科研方向为 Trustworthy Graph Neural Networks。赵天翔也是来自 PSU 的第三年 PhD 学生,他主要从事 Weakly-Supervised Graph Learning 方向的研究。王苏杭教授对于数据挖掘和机器学习有着广泛的兴趣,最近的研究主要集中于图神经网络的各个方向如 Trustworthiness, self-supervision, weak-supervision 和 heterophilic graph learning, deep generative models 和 causal recommender systems。

参考文献
[1] Jin, Wei, Tyler Derr, Yiqi Wang, Yao Ma, Zitao Liu, and Jiliang Tang. "Node similarity preserving graph convolutional networks." In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, pp. 148-156. 2021.
[2] Dai, Enyan, Wei Jin, Hui Liu, and Suhang Wang. "Towards Robust Graph Neural Networks for Noisy Graphs with Sparse Labels." Proceedings of the 15th ACM International Conference on Web Search and Data Mining. 2022.
[3] Dai, Enyan, and Suhang Wang. "Say no to the discrimination: Learning fair graph neural networks with limited sensitive attribute information." Proceedings of the 14th ACM International Conference on Web Search and Data Mining. 2021.
[4] Dai, Enyan, and Suhang Wang. "Towards Self-Explainable Graph Neural Network." Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021.
[5] Zhang, Zaixi, Qi Liu, Hao Wang, Chengqiang Lu, and Cheekong Lee. "ProtGNN: Towards Self-Explaining Graph Neural Networks." arXiv preprint arXiv:2112.00911 (2021).
[6] Dai, Enyan, Tianxiang Zhao, Huaisheng Zhu, Junjie Xu, Zhimeng Guo, Hui Liu, Jiliang Tang, and Suhang Wang. "A Comprehensive Survey on Trustworthy Graph Neural Networks: Privacy, Robustness, Fairness, and Explainability." arXiv preprint arXiv:2204.08570 (2022).
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



