火山语音团队提出了一种能够有效建模不同领域之间相关性的迁移核函数(transfer kernel),在一些多源但低资源回归场景下显著提升了迁移效果。
一直以来,高斯过程回归模型(Gaussian process regression model, i.e., GP)作为一类基础的贝叶斯机器学习模型,在工程与统计等领域的回归问题中有着广泛应用;
传统的高斯过程回归模型需要大量的有监督数据进行训练才可发挥好的效果,但在具体实践中,收集和标记数据是一项昂贵且费时的工程。
相比之下,迁移高斯过程回归模型(Transfer GP)能够高效利用不同领域(domain)的数据来降低标记成本,使多源数据应用更加高效。
基于此,火山语音团队对目前研究领域关注较少的多源数据迁移回归问题做了基础探究,提出一种基于多源迁移核函数的迁移高斯回归过程模型( TRANSFER KERNEL LEARNING FOR MULTI-SOURCE TRANSFER GAUSSIAN PROCESS REGRESSION),并在理论与实验两个层面验证了模型的有效性:即理论上展示了迁移效果优劣与域相关性的必然关联;实验中验证了模型可以高效提升多源数据的迁移效果。
![]()
论文链接:https://ieeexplore.ieee.org/document/9802749
这项研究的主要贡献是提出一种能够有效建模不同领域之间相关性的迁移核函数(transfer kernel),并在一些多源但低资源回归场景下提升迁移效果。更重要的一点,该理论全面地展示了不同领域相关性与迁移效果的关系,对未来设计创新的多源迁移算法具有重要的借鉴意义。
该研究成果已被人工智能领域顶级国际
期刊 IEEE TPAMI 接收。
本文的核心是设计一种迁移核函数,不仅能够准确拟合不同领域的数据的特征,而且能够通过建模不同领域之间的相关性来控制不同源领域(source domain)与目标领域(target domain)的知识迁移强度。挑战在于设计的迁移核函数在符合上述条件的同时,还须满足核函数的基本要求,即半正定性(Postive Semi-definite)。
对此论文首先讨论了迁移核函数应用于迁移高斯回归过程模型中的两种不同策略,即集成策略(ensemble strategy)与一体化策略(all-in-one strategy)的优缺点,而火山语音团队提出的迁移核函数旨在融合两种策略的优势。
![]()
具体来说,团队提出了一种多源核函数
![]() 。
。
![]() 为每一领域(domain pair)赋予一个可学习的参数化系数,该系数用于建模该领域对的相关性。
为了能够拟合不同领域的
数据异构特性,针对不同的领域的数据,
为每一领域(domain pair)赋予一个可学习的参数化系数,该系数用于建模该领域对的相关性。
为了能够拟合不同领域的
数据异构特性,针对不同的领域的数据,
![]() 利用差异性的基础核函数进行建模。
相应就得到如下形式的多源核函数:
利用差异性的基础核函数进行建模。
相应就得到如下形式的多源核函数:
![]()
但在没有保证半正定性的情况下,上式并不能称为多源核函数,所以接下来就需要研究上述式子在什么条件下是半正定的,进而提出以下定理,其中定理 1 为我们展示了该如何设计
![]() 的各组成部分,从而使其成为一个半正定的多源核函数。
的各组成部分,从而使其成为一个半正定的多源核函数。
![]()
设计完成
![]() ,团队进一步提出了如何利用
,团队进一步提出了如何利用
![]() 进行迁
移高斯回归模型的学习与推理
,同时也推导了利用
进行迁
移高斯回归模型的学习与推理
,同时也推导了利用
![]() 的迁移高斯回归模
型的泛化误差的上下界 (
generalization error bounds)。
该 bounds 集中展示了迁移效果与不同领域相关性的息息相关,同时源领域与目标领域之间的相关性比不同源领域之间的相关性,对于迁移效果起到更重要的作用。
的迁移高斯回归模
型的泛化误差的上下界 (
generalization error bounds)。
该 bounds 集中展示了迁移效果与不同领域相关性的息息相关,同时源领域与目标领域之间的相关性比不同源领域之间的相关性,对于迁移效果起到更重要的作用。
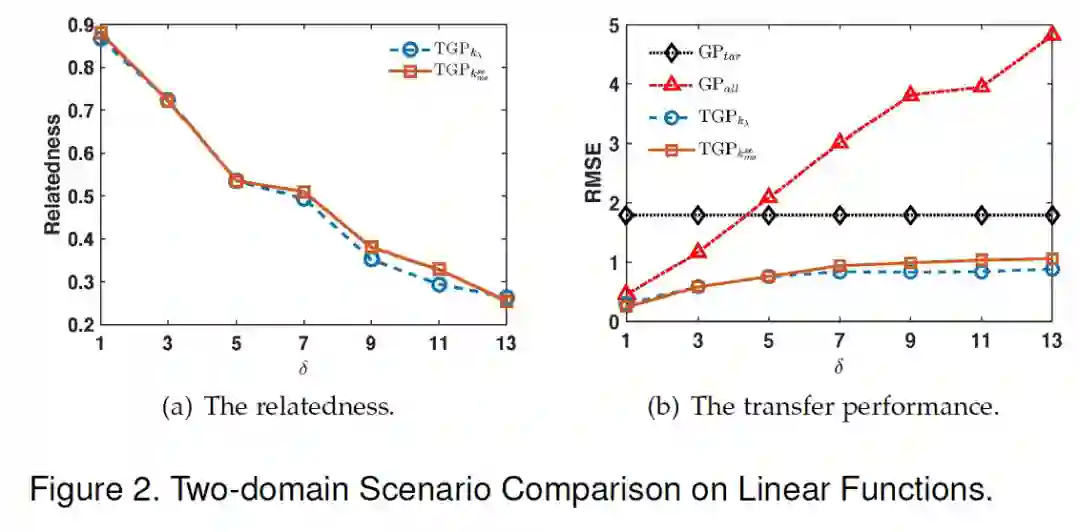
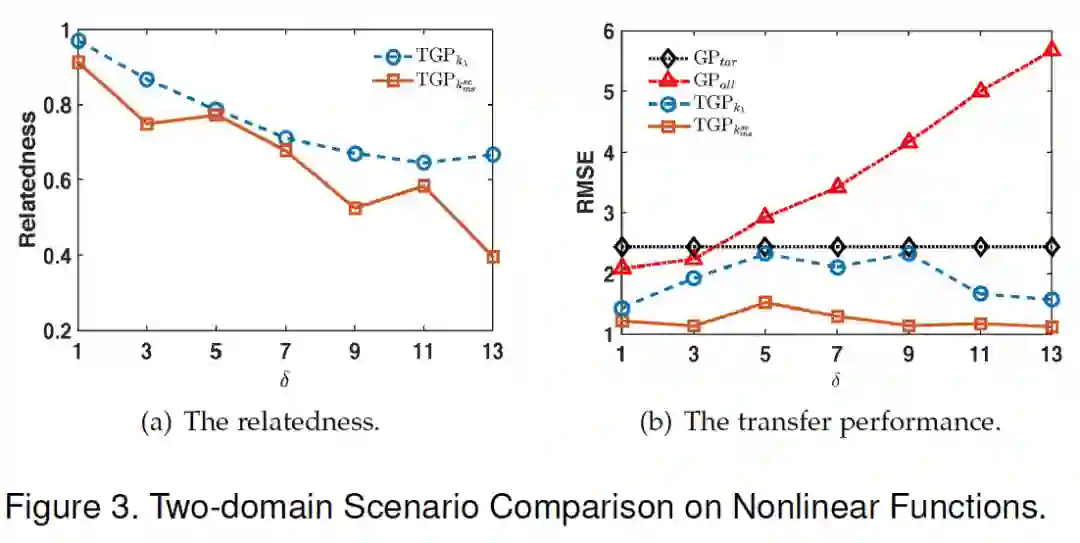
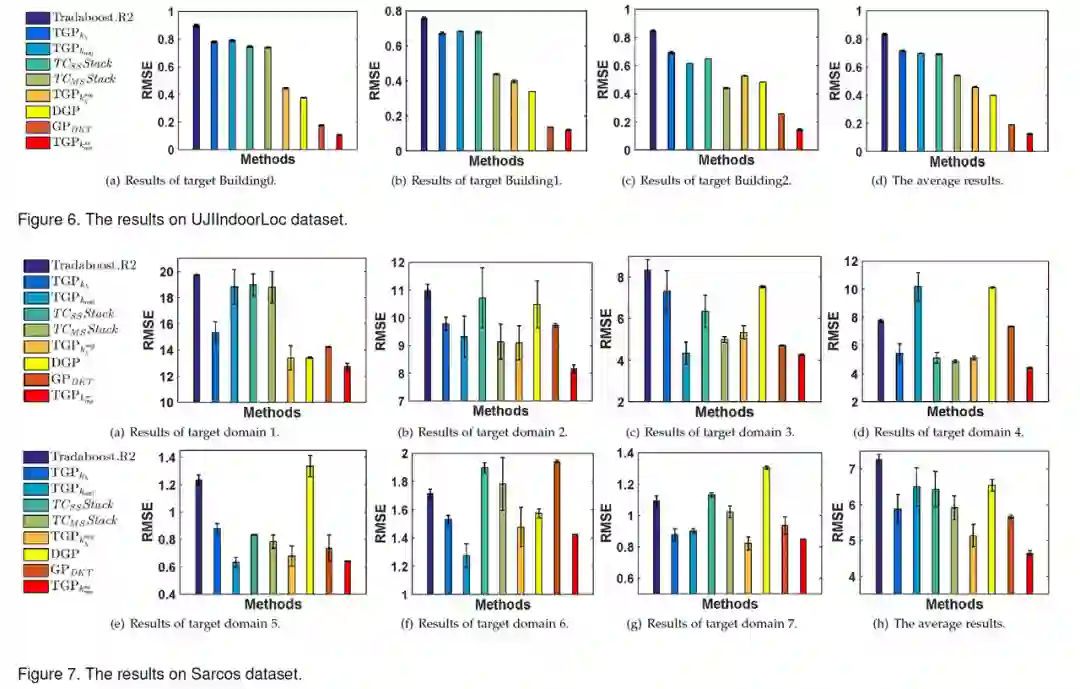
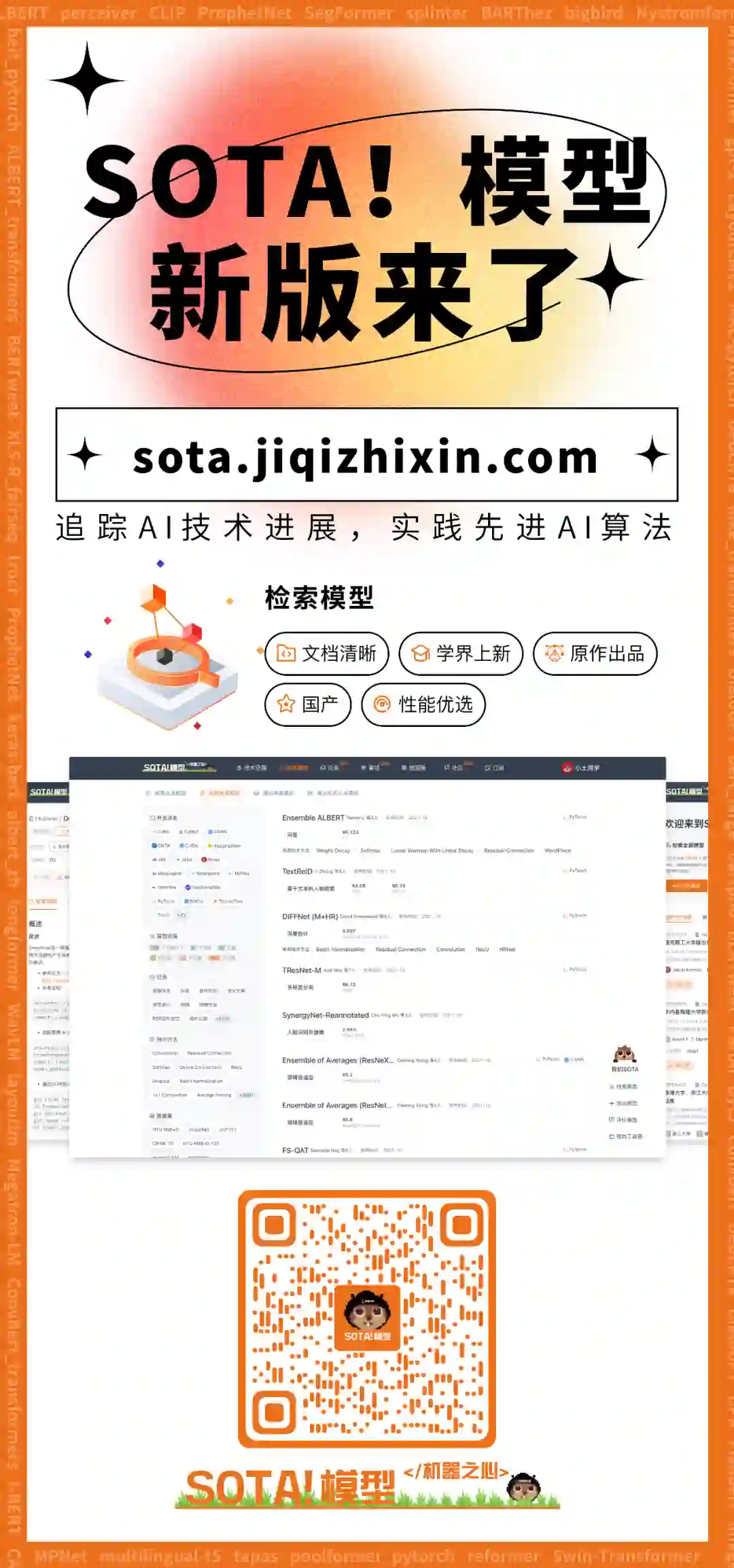
除了理论推导之外,论文验证了该模型准确学习不同领域相关性的能力,即首先研究两个领域下线性与非线性的情况。可以看出,不论是线性还是非线性函数,模型都能够很好学习到两个领域之间的相关性,同时在处理非线性函数时还能取得更好的迁移效果, 即更小的均方根差。
![]()
![]()
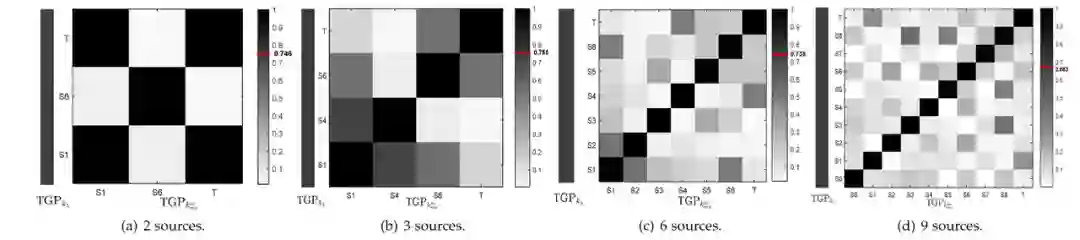
团队还进一步研究了多源情况,即有多个源领域且不同源领域与目标领域的相关性不同。实验结果表明,随着源领域的增多,学习到的源领域与目标领域的相关性越来越复杂,这是由于不同源领域之间的相关性也会影响到源领域与目标领域相关性的学习。
![]()
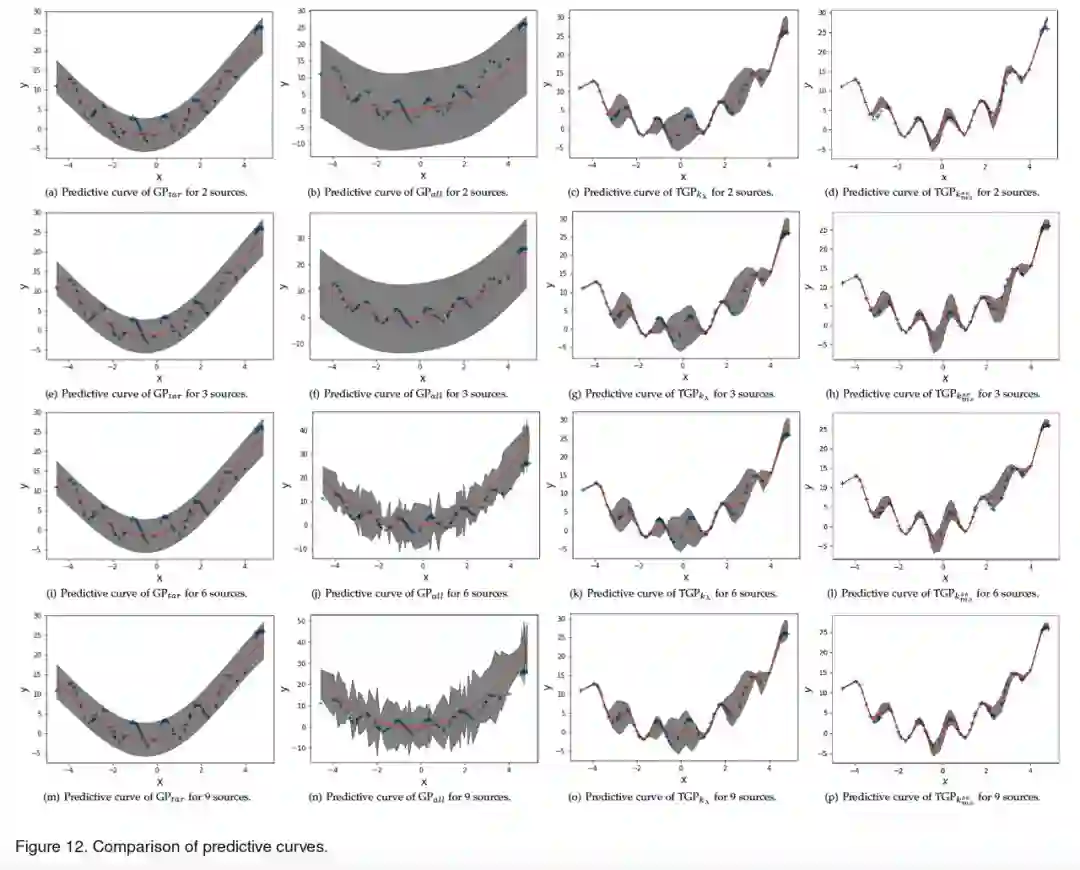
此外还研究了不同的模型下的迁移效果,即根据有限的目标数据和丰富的源数据对大量无监督目标数据的拟合能力,可以看出模型在迁移效果上要远远优于其他模型。
![]()
最后,团队还在两个现实数据集中对模型进行了验证。与 9 个 SOTA 方法相比,模型在不同的迁移回归任务中都取得了更好的迁移效果,即更小的均方根差。
![]()
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


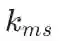 。
。