重大影响!非参数估计和GAN的研究人员看过来| NeurIPS 2019杰出论文荣誉提名奖
Nonparametric density estimation
& convergence of GANs under Besov IPM losses
论文作者:
AnanyaUppal, ShashankSingh, BarnabásPóczos(卡耐基梅隆大学)
论文地址:
https://www.aminer.cn/pub/5db9297547c8f766461f721d/

前言
本文将对NeurIPS 2019获得杰出论文奖荣誉提名的论文《Nonparametric density estimation & convergence of GANs under Besov IPM losses》进行解读。该论文以严格的理论方法表明,在密度估计方面,GAN的性能优于线性方法(就收敛速度而言)。利用先前关于小波收缩的结果,本文为GAN的表征能力提供了新的见解。具体来说,作者在大型函数类别(Besov空间)内的大型损失类别(所谓的积分概率度量)下,得出了用于非参数密度估计的最小极大收敛速度。审稿人认为,这篇论文将对从事非参数估计和GAN的研究人员产生重大影响。
摘要
本文研究非参数概率密度的估计问题(Besov IPMs)。其中包括一个大类的损失距离,例如,距离,总方差距离,和普适的Wasserstein-Kolmogorov距离。对于各类的参数设置,作者提供上下两种界限,准确地描述损失函数和假设,以此通过数据交互来确定最小极大最优收敛速度。本文也同时展示了线性分布估计,例如经验分布或核密度估计。这些往往不能以最佳速率收敛。文章中设定的界限为普适、统一或改进几个最近的和经典的结果。此外,IPMs还可以用于建立生成性对抗网络的统计模型(GANs)。因此,作者展示了如何推导GAN统计误差的界限。例如,GANs可以严格地优于最佳线性估计。
研究背景


相关工作
本文对非参数密度估计中的一些最新和经典结果进行了统一、扩展或改进。先前相关工作主要是两个方面:



研究成果
本文的主要有三大技术贡献:

结果讨论
首先,文中注意到q_d和q_g没有出现在界限中。Tao认为q_d和q_g可能只有对数效应(与σ_d, p_d, σ_g, p_g多项式效应对比)。因此,一个更细化的分析可能需要合并和q_d和q_g,以弥补作者的一般估计器上下界之间的多对数差距。
另一方面,在线性和一般情况下,参数σ_d, p_d, σ_g, p_g在确定最小极大收敛速度方面都起着重要作用。文中首先单独讨论这些参数,然后讨论它们之间的一些相互作用。
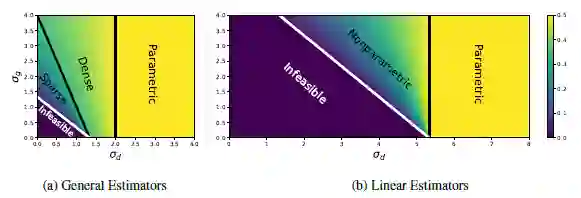
图1:最小极大收敛速度与判别平滑度σ_d和分布函数平滑度σ_g的函数。a)一般估计和(b)线性估计,在D=4, p_d=1.2, p_q=2。颜色表示最小最大收敛速度的指数,忽略多对数因子。
成果总结
本文证明,对于大类的F_d—IPM损耗和F_g分布类,统一的最小极大收敛速度可以达到对数指标。因此,文中总结了一些以前在特殊情况下观察到的现象。
首先,在足够弱的损失函数下,即使在非常大的非参数分布类上,也可以在参数速率O(n^-1/2)进行分布估计;
其次,在许多情况下,最优估计需要适应非齐次平滑条件;许多常用的分布估计器无法做到这一点,因此会以次优速率收敛,甚至无法收敛;
最后,具有足够大的全连通ReLU神经网络的GANs,利用小波阈值正则化进行统计上的极大极小率最优分布估计,比非齐次非参数平滑分类上更优(假设GAN优化问题可以精确求解)。
重要的是,由于GANS优化IPM的损失比传统L^p损失要小,它们可以学习更高维分布的合理近似值,通过采样复杂性,或者可以解释为什么它们在图像数据的情况下是更优的。因此,作者的结果表明,维数的缺陷可能比经典的非参数下界表示的要轻微。
作者| 王健嘉(上海大学)
排版| 学术菠菜
校对| 小满
责编| 学术青 优学术

往期精彩回顾
【NeurIPS100】NeurIPS2019 七篇获奖论文揭晓 入选论文深度分析!
点击“阅读原文”查看NeurIPS 2019报道及论文解读集合↓

