AI看图说话首超人类!微软认知AI团队提出视觉词表预训练超越Transformer

来源:新智元

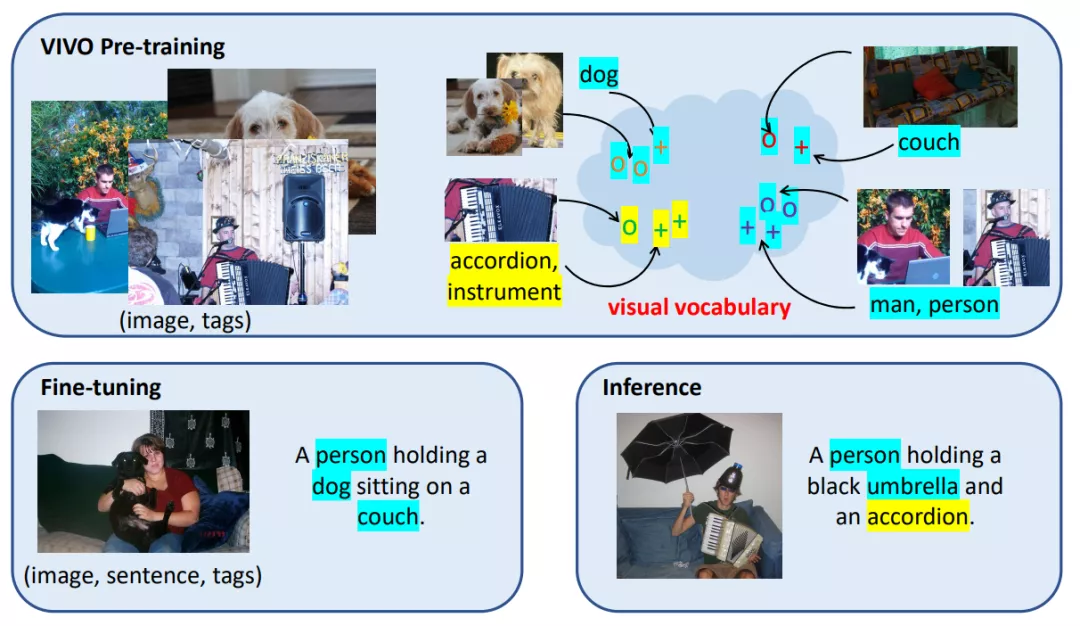
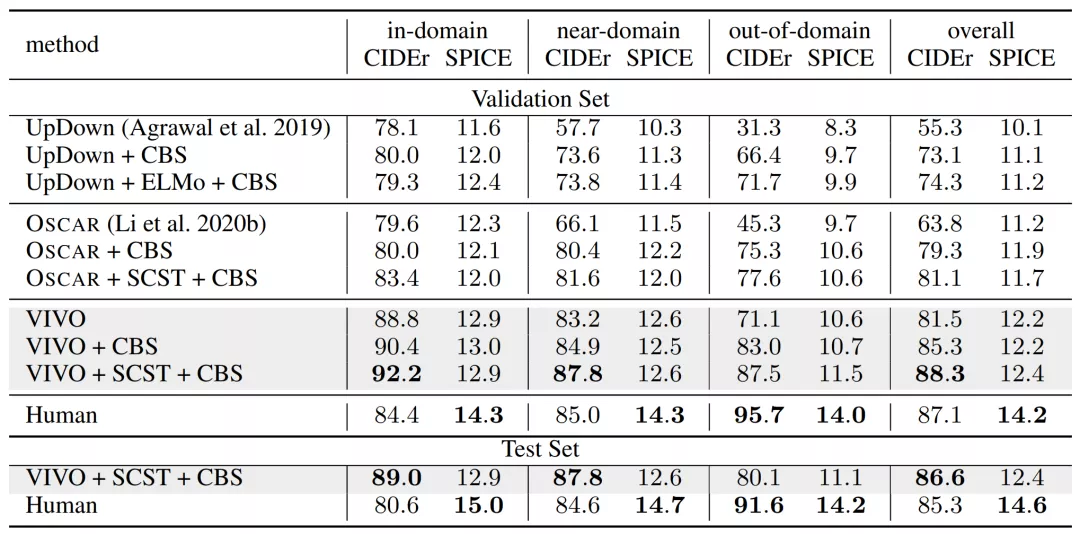
【导读】能看图会说话的AI,表现还超过了人类?最近,Azure悄然上线了一个新的人工智能服务,能精准的说出图片中的内容。而背后的视觉词表技术,更是超越了基于Transformer的前辈们,拿到nocaps挑战赛冠军。
看图说话(或者叫图像描述),近年来受到了很多关注,它可以自动生成图片描述。但是目前无论是学术界还是工业界,做的
效果都差强人意
。







登录查看更多
相关内容
Arxiv
0+阅读 · 2020年11月26日
相关主题





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2020年11月26日