图卷积网络到底怎么做,这是一份极简的Numpy实现
选自TowardsDataScience
作者:Tobias Skovgaard Jepsen
机器之心编译
参与:Geek AI、路
由于图结构非常复杂且信息量很大,因此对于图的机器学习是一项艰巨的任务。本文介绍了如何使用图卷积网络(GCN)对图进行深度学习,GCN 是一种可直接作用于图并利用其结构信息的强大神经网络。
本文将介绍 GCN,并使用代码示例说明信息是如何通过 GCN 的隐藏层传播的。读者将看到 GCN 如何聚合来自前一层的信息,以及这种机制如何生成图中节点的有用特征表征。
何为图卷积网络?
GCN 是一类非常强大的用于图数据的神经网络架构。事实上,它非常强大,即使是随机初始化的两层 GCN 也可以生成图网络中节点的有用特征表征。下图展示了这种两层 GCN 生成的每个节点的二维表征。请注意,即使没有经过任何训练,这些二维表征也能够保存图中节点的相对邻近性。

更形式化地说,图卷积网络(GCN)是一个对图数据进行操作的神经网络。给定图 G = (V, E),GCN 的输入为:
一个输入维度为 N × F⁰ 的特征矩阵 X,其中 N 是图网络中的节点数而 F⁰ 是每个节点的输入特征数。
一个图结构的维度为 N × N 的矩阵表征,例如图 G 的邻接矩阵 A。[1]
因此,GCN 中的隐藏层可以写作 Hⁱ = f(Hⁱ⁻¹, A))。其中,H⁰ = X,f 是一种传播规则 [1]。每一个隐藏层 Hⁱ 都对应一个维度为 N × Fⁱ 的特征矩阵,该矩阵中的每一行都是某个节点的特征表征。在每一层中,GCN 会使用传播规则 f 将这些信息聚合起来,从而形成下一层的特征。这样一来,在每个连续的层中特征就会变得越来越抽象。在该框架下,GCN 的各种变体只不过是在传播规则 f 的选择上有所不同 [1]。
传播规则的简单示例
下面,本文将给出一个最简单的传播规则示例 [1]:
f(Hⁱ, A) = σ(AHⁱWⁱ)
其中,Wⁱ 是第 i 层的权重矩阵,σ 是非线性激活函数(如 ReLU 函数)。权重矩阵的维度为 Fⁱ × Fⁱ⁺¹,即权重矩阵第二个维度的大小决定了下一层的特征数。如果你对卷积神经网络很熟悉,那么你会发现由于这些权重在图中的节点间共享,该操作与卷积核滤波操作类似。
简化
接下来我们在最简单的层次上研究传播规则。令:
i = 1,(约束条件 f 是作用于输入特征矩阵的函数)
σ 为恒等函数
选择权重(约束条件: AH⁰W⁰ =AXW⁰ = AX)
换言之,f(X, A) = AX。该传播规则可能过于简单,本文后面会补充缺失的部分。此外,AX 等价于多层感知机的输入层。
简单的图示例
我们将使用下面的图作为简单的示例:
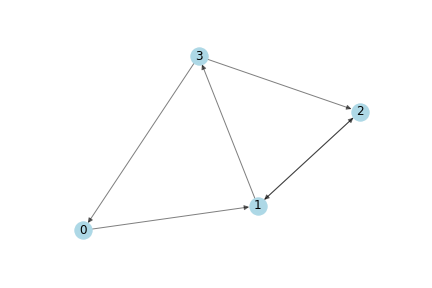
一个简单的有向图。
使用 numpy 编写的上述有向图的邻接矩阵表征如下:
A = np.matrix([
[0, 1, 0, 0],
[0, 0, 1, 1],
[0, 1, 0, 0],
[1, 0, 1, 0]],
dtype=float
)接下来,我们需要抽取出特征!我们基于每个节点的索引为其生成两个整数特征,这简化了本文后面手动验证矩阵运算的过程。
In [3]: X = np.matrix([
[i, -i]
for i in range(A.shape[0])
], dtype=float)
X
Out[3]: matrix([
[ 0., 0.],
[ 1., -1.],
[ 2., -2.],
[ 3., -3.]
])应用传播规则
我们现在已经建立了一个图,其邻接矩阵为 A,输入特征的集合为 X。下面让我们来看看,当我们对其应用传播规则后会发生什么:
In [6]: A * X
Out[6]: matrix([
[ 1., -1.],
[ 5., -5.],
[ 1., -1.],
[ 2., -2.]]每个节点的表征(每一行)现在是其相邻节点特征的和!换句话说,图卷积层将每个节点表示为其相邻节点的聚合。大家可以自己动手验证这个计算过程。请注意,在这种情况下,如果存在从 v 到 n 的边,则节点 n 是节点 v 的邻居。
问题
你可能已经发现了其中的问题:
节点的聚合表征不包含它自己的特征!该表征是相邻节点的特征聚合,因此只有具有自环(self-loop)的节点才会在该聚合中包含自己的特征 [1]。
度大的节点在其特征表征中将具有较大的值,度小的节点将具有较小的值。这可能会导致梯度消失或梯度爆炸 [1, 2],也会影响随机梯度下降算法(随机梯度下降算法通常被用于训练这类网络,且对每个输入特征的规模(或值的范围)都很敏感)。
接下来,本文将分别对这些问题展开讨论。
增加自环
为了解决第一个问题,我们可以直接为每个节点添加一个自环 [1, 2]。具体而言,这可以通过在应用传播规则之前将邻接矩阵 A 与单位矩阵 I 相加来实现。
In [4]: I = np.matrix(np.eye(A.shape[0]))
I
Out[4]: matrix([
[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]
])
In [8]: A_hat = A + I
A_hat * X
Out[8]: matrix([
[ 1., -1.],
[ 6., -6.],
[ 3., -3.],
[ 5., -5.]])现在,由于每个节点都是自己的邻居,每个节点在对相邻节点的特征求和过程中也会囊括自己的特征!
对特征表征进行归一化处理
通过将邻接矩阵 A 与度矩阵 D 的逆相乘,对其进行变换,从而通过节点的度对特征表征进行归一化。因此,我们简化后的传播规则如下:
f(X, A) = D⁻¹AX
让我们看看发生了什么。我们首先计算出节点的度矩阵。
In [9]: D = np.array(np.sum(A, axis=0))[0]
D = np.matrix(np.diag(D))
D
Out[9]: matrix([
[1., 0., 0., 0.],
[0., 2., 0., 0.],
[0., 0., 2., 0.],
[0., 0., 0., 1.]
])在应用传播规则之前,不妨看看我们对邻接矩阵进行变换后发生了什么。
变换之前
A = np.matrix([
[0, 1, 0, 0],
[0, 0, 1, 1],
[0, 1, 0, 0],
[1, 0, 1, 0]],
dtype=float
)变换之后
In [10]: D**-1 * A
Out[10]: matrix([
[0. , 1. , 0. , 0. ],
[0. , 0. , 0.5, 0.5],
[0. , 0.5, 0. , 0. ],
[0.5, 0. , 0.5, 0. ]
])可以观察到,邻接矩阵中每一行的权重(值)都除以该行对应节点的度。我们接下来对变换后的邻接矩阵应用传播规则:
In [11]: D**-1 * A * X
Out[11]: matrix([
[ 1. , -1. ],
[ 2.5, -2.5],
[ 0.5, -0.5],
[ 2. , -2. ]
])得到与相邻节点的特征均值对应的节点表征。这是因为(变换后)邻接矩阵的权重对应于相邻节点特征加权和的权重。大家可以自己动手验证这个结果。
整合
现在,我们将把自环和归一化技巧结合起来。此外,我们还将重新介绍之前为了简化讨论而省略的有关权重和激活函数的操作。
添加权重
首先要做的是应用权重。请注意,这里的 D_hat 是 A_hat = A + I 对应的度矩阵,即具有强制自环的矩阵 A 的度矩阵。
In [45]: W = np.matrix([
[1, -1],
[-1, 1]
])
D_hat**-1 * A_hat * X * W
Out[45]: matrix([
[ 1., -1.],
[ 4., -4.],
[ 2., -2.],
[ 5., -5.]
])如果我们想要减小输出特征表征的维度,我们可以减小权重矩阵 W 的规模:
In [46]: W = np.matrix([
[1],
[-1]
])
D_hat**-1 * A_hat * X * W
Out[46]: matrix([[1.],
[4.],
[2.],
[5.]]
)添加激活函数
本文选择保持特征表征的维度,并应用 ReLU 激活函数。
In [51]: W = np.matrix([
[1, -1],
[-1, 1]
])
relu(D_hat**-1 * A_hat * X * W)
Out[51]: matrix([[1., 0.],
[4., 0.],
[2., 0.],
[5., 0.]])这就是一个带有邻接矩阵、输入特征、权重和激活函数的完整隐藏层!
在真实场景下的应用
最后,我们将图卷积网络应用到一个真实的图上。本文将向读者展示如何生成上文提到的特征表征。
Zachary 空手道俱乐部
Zachary 空手道俱乐部是一个被广泛使用的社交网络,其中的节点代表空手道俱乐部的成员,边代表成员之间的相互关系。当年,Zachary 在研究空手道俱乐部的时候,管理员和教员发生了冲突,导致俱乐部一分为二。下图显示了该网络的图表征,其中的节点标注是根据节点属于俱乐部的哪个部分而得到的,「A」和「I」分别表示属于管理员和教员阵营的节点。

Zachary 空手道俱乐部图网络
构建 GCN
接下来,我们将构建一个图卷积网络。我们并不会真正训练该网络,但是会对其进行简单的随机初始化,从而生成我们在本文开头看到的特征表征。我们将使用 networkx,它有一个可以很容易实现的 Zachary 空手道俱乐部的图表征。然后,我们将计算 A_hat 和 D_hat 矩阵。
from networkx import to_numpy_matrix
zkc = karate_club_graph()
order = sorted(list(zkc.nodes()))
A = to_numpy_matrix(zkc, nodelist=order)
I = np.eye(zkc.number_of_nodes())
A_hat = A + I
D_hat = np.array(np.sum(A_hat, axis=0))[0]
D_hat = np.matrix(np.diag(D_hat))接下来,我们将随机初始化权重。
W_1 = np.random.normal(
loc=0, scale=1, size=(zkc.number_of_nodes(), 4))
W_2 = np.random.normal(
loc=0, size=(W_1.shape[1], 2))接着,我们会堆叠 GCN 层。这里,我们只使用单位矩阵作为特征表征,即每个节点被表示为一个 one-hot 编码的类别变量。
def gcn_layer(A_hat, D_hat, X, W):
return relu(D_hat**-1 * A_hat * X * W)
H_1 = gcn_layer(A_hat, D_hat, I, W_1)
H_2 = gcn_layer(A_hat, D_hat, H_1, W_2)
output = H_2我们进一步抽取出特征表征。
feature_representations = {
node: np.array(output)[node]
for node in zkc.nodes()}你看,这样的特征表征可以很好地将 Zachary 空手道俱乐部的两个社区划分开来。至此,我们甚至都没有开始训练模型!
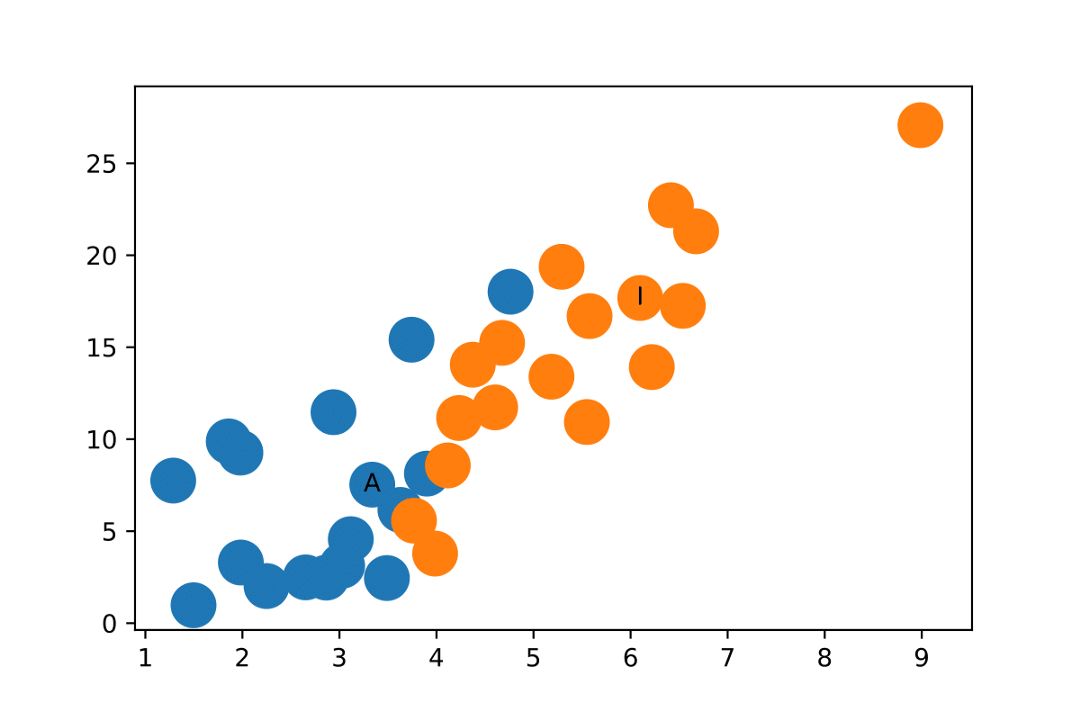
Zachary 空手道俱乐部图网络中节点的特征表征。
我们应该注意到,在该示例中由于 ReLU 函数的作用,在 x 轴或 y 轴上随机初始化的权重很可能为 0,因此需要反复进行几次随机初始化才能生成上面的图。
结语
本文中对图卷积网络进行了高屋建瓴的介绍,并说明了 GCN 中每一层节点的特征表征是如何基于其相邻节点的聚合构建的。读者可以从中了解到如何使用 numpy 构建这些网络,以及它们的强大:即使是随机初始化的 GCN 也可以将 Zachary 空手道俱乐部网络中的社区分离开来。

参考文献
[1] Blog post on graph convolutional networks by Thomas Kipf.
[2] Paper called Semi-Supervised Classification with Graph Convolutional Networks by Thomas Kipf and Max Welling.
原文链接:https://towardsdatascience.com/how-to-do-deep-learning-on-graphs-with-graph-convolutional-networks-7d2250723780
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


