国科大UCAS胡包钢教授《信息论与机器学习》课程第六讲:信息指标与拒识分类评价
【导读】本章是应用信息指标对拒识分类结果进行评价考察的内容,在不平衡数据学习中首次同时考察了“误差类别(error types)”与“拒识类别(reject types)”。

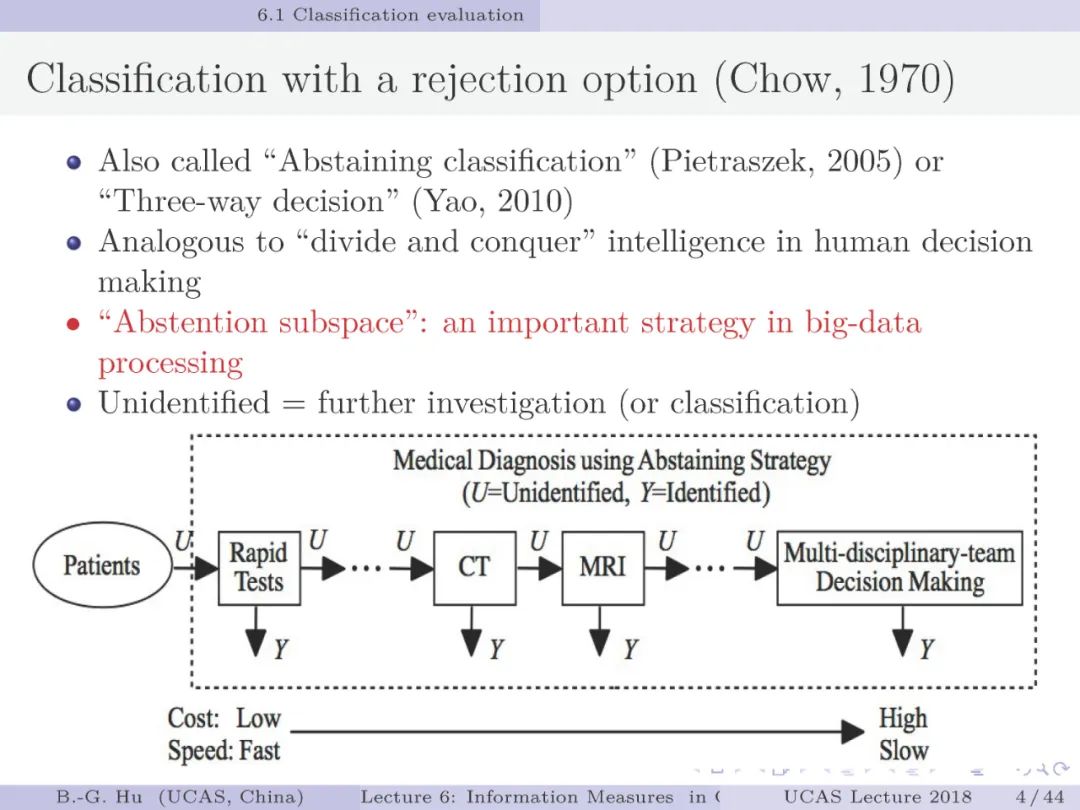
拒识分类体现人类智能决策方式,也是大数据中“分而治之”的重要方法之一,以实现快速筛选与减少风险的双重目标。如第4页中的医学诊断,图中的U即是“拒识”也是“疑似病人”。值此机会,特别致谢那些奋战在疫情前线的所有医护人员,志愿者与工作人员们。正如著名演员周星驰先生2月21日对四川前往武汉的第一批医疗队队长雷波医生说的“看到你们为了挽救生命全副武装的紧箍咒,你们是我心中的盖世英雄”。向英雄们致敬!
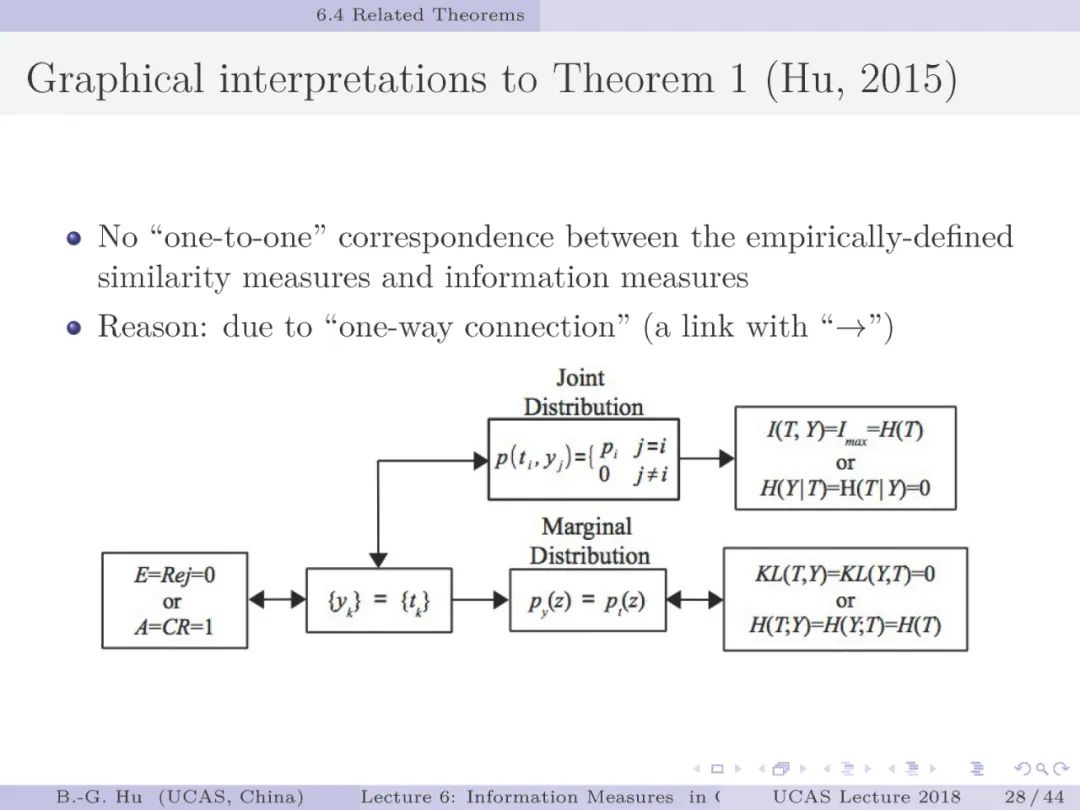
各种传统评价指标在拒识分类应用中已经失效。英国剑桥大学Mackay教授在其2003年经典著作中以两个例题(第8页)指出了拒识分类评价这个问题(在此致谢杨余久博士告知我有关信息)。书中建议应用互信息指标来评价考察两个例题,但未有展开研究。基于该思想,我们扩展到更多信息指标来综合考察,并将拒识分类延伸到区分“误差类别”与“拒识类别”的研究内容。由于问题复杂性,我们简化为四个例题来同时考察“误差类别”与“拒识类别”(第11页)。可以具体看到传统分类评价指标已经无法“合理”判定拒识分类结果。针对问题,我们首先提出拒识分类中要有三组“元准则(即关于准则之上的准则,也可以理解为是一种广义约束)”来满足“合理”评价(第12-15页)。然后应用24个信息指标来考察四个例题以及多类别分类。我们称为指标(或准则)而非度量是因为有些指标并非符合度量属性。其中只有第2个信息指标更为“合理”。我们首次推导了信息指标为极值时对应的分类情况,即三个定理。第18页图示了分类性能与信息指标极值之间的关联关系。对于理解两种学习目标中的极值情况十分重要。当完全正确分类时可以对应信息指标极值,但是反之则不然。这也意味着单纯应用信息指标不能确保正确分类。应用中同时需要分类性能指标来完成辅助评价。
第6页: 对于有拒识二值分类中混淆矩阵,我们建议统一应用这样2x3的矩阵元素方式表示,这样能够确保第一类错误以及第一类拒识都在矩阵中位于第一行中,并与统计学中第一类错误定义内涵保持一致。注意有些表示方法(如[1])扩展到拒识情况后将无法实现上述要求。
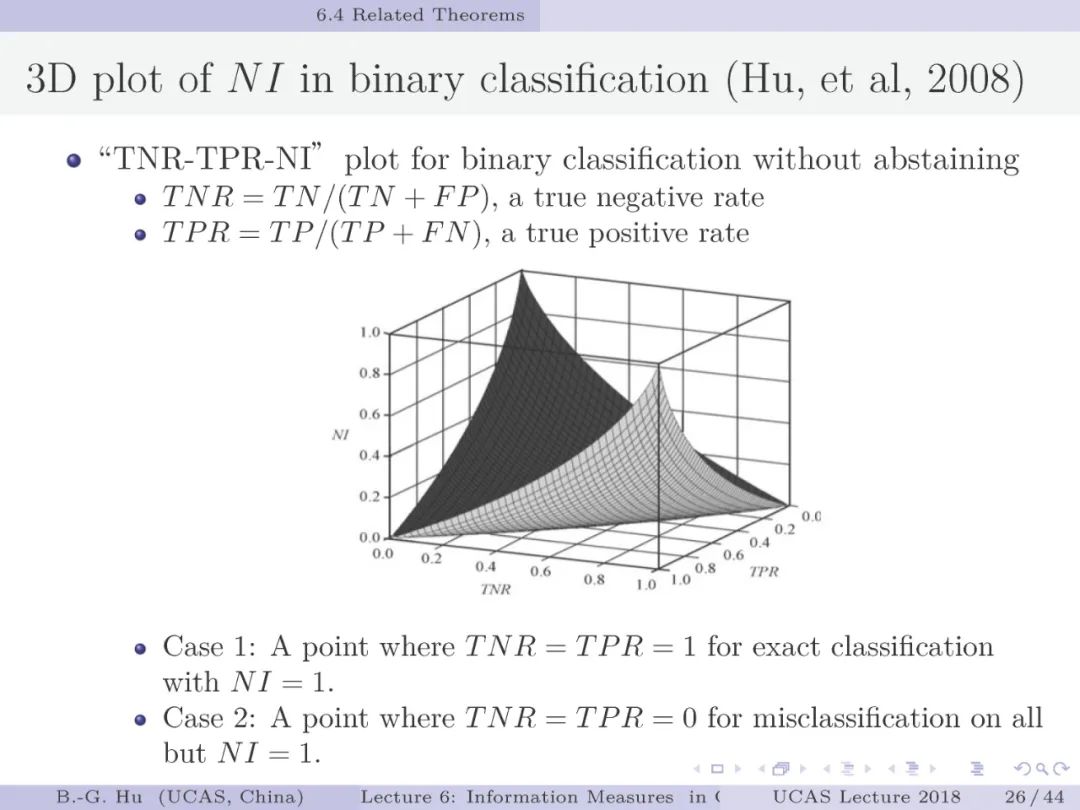
第26页: 该图给出了熵界分析的又一种表达方式,也是基于二值分类建立了信息指标与分类性能指标的关联。该图应用了三维表示,其中两个信息指标为独立变量,且熵界形状固定并与类别比例无关(考虑为什么)。这个熵界分析对应非贝叶斯误差情况。其中互信息I=0时,对应的混淆矩阵中四个元素的关系如同第24页Case 4中所表达。
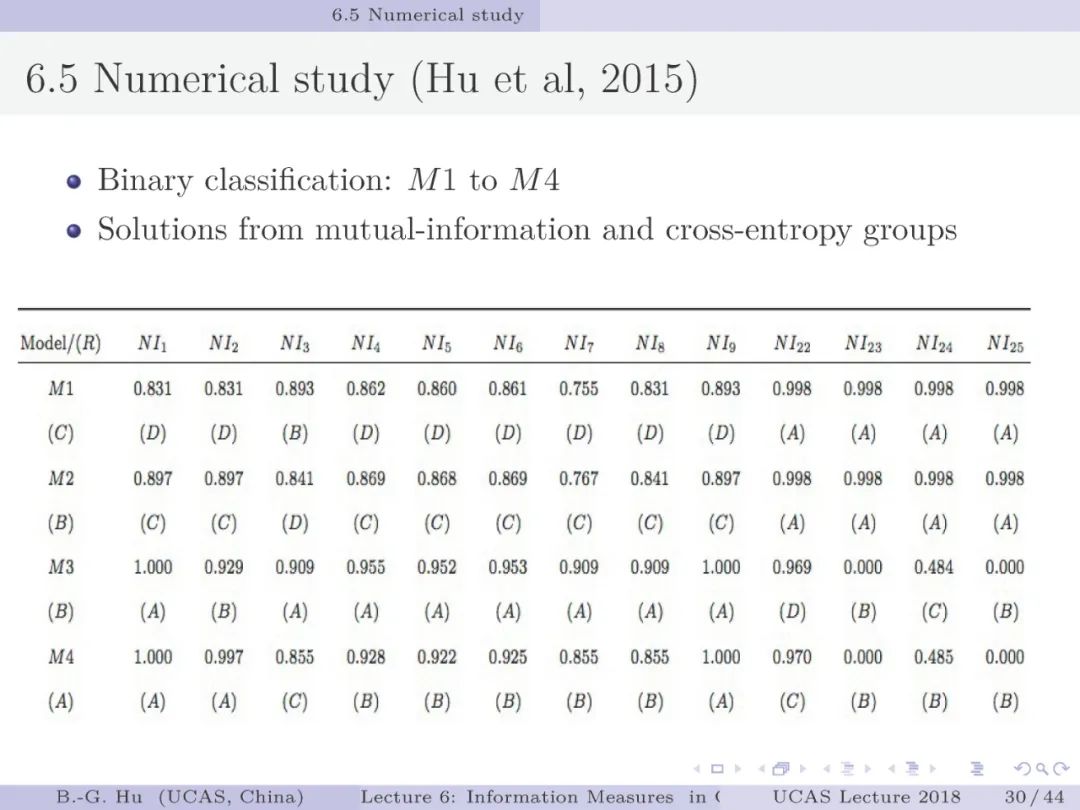
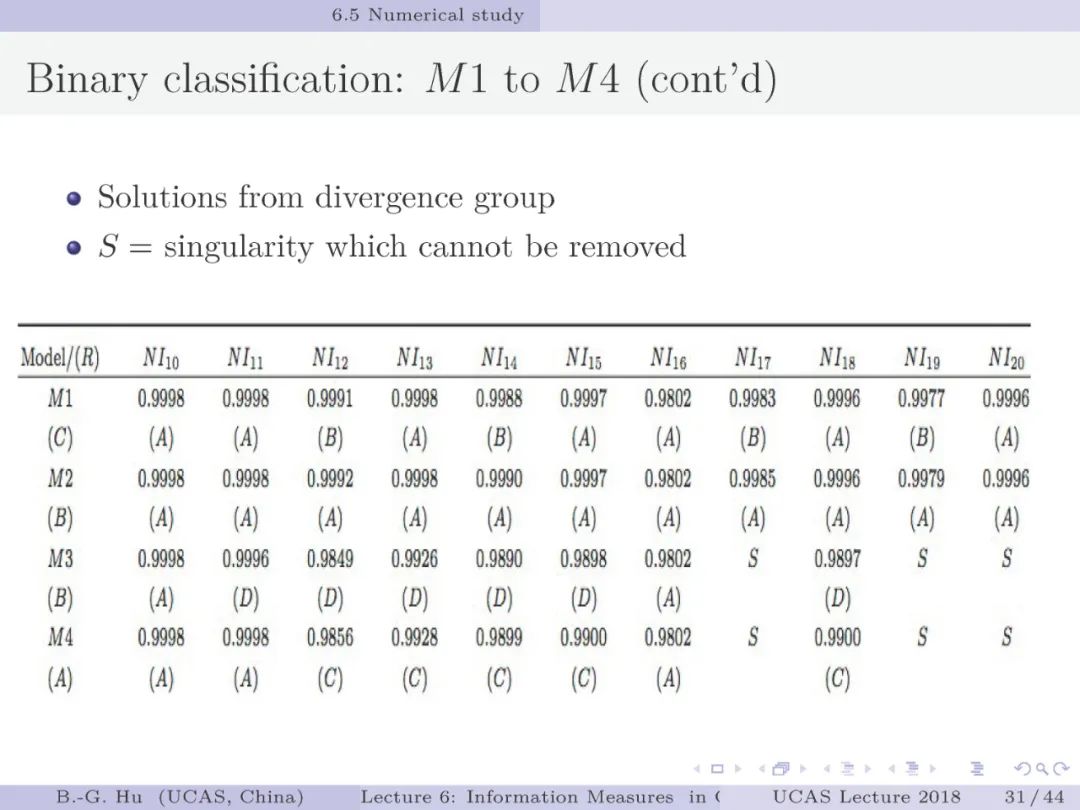
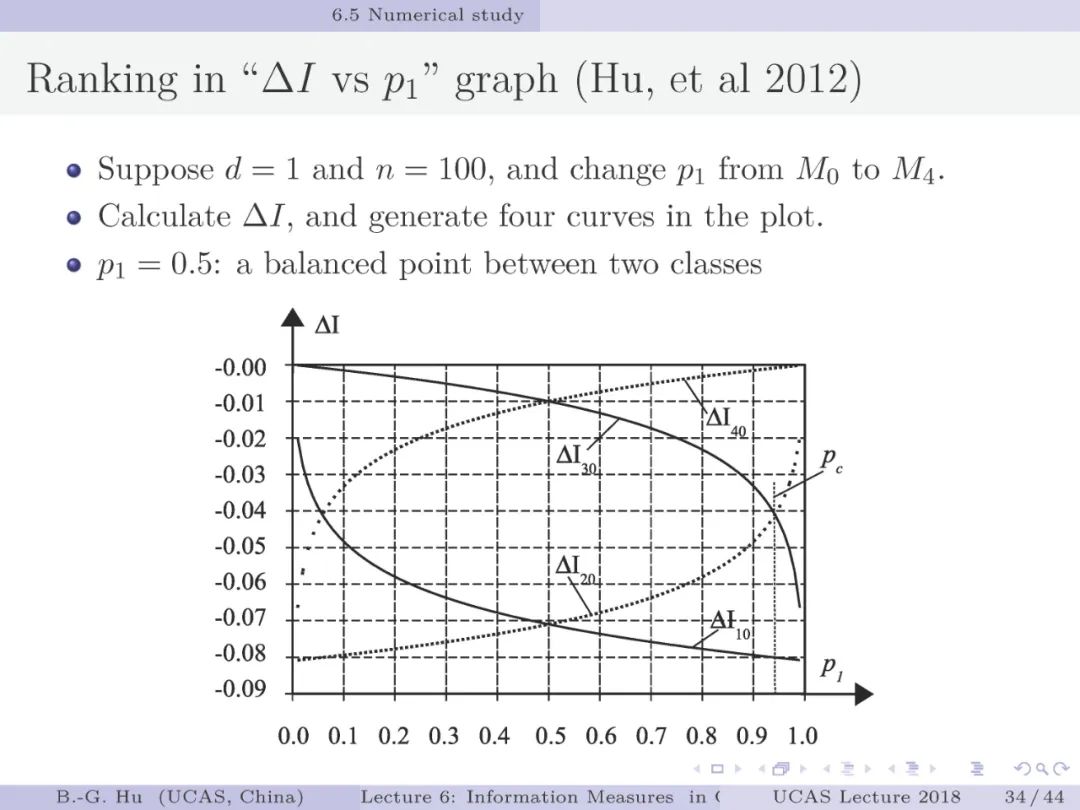
第32-36页: 验证NI_2符合第三元准则并进一步数值考察。可以发现NI_2还能在大类别比例趋于极端时,大类一个样本错误代价与小类的一个样本拒识代价之间的大小关系会发生变化(其中代价是指互信息损失)。这种变化应是合理的。此例题结果很具启迪性。说明一个熵的概念可以同时兼容“误差类别”与“拒识类别”之间的平衡。而传统经验指标处理该类问题必须要应用“误差”与“拒识”两个概念。
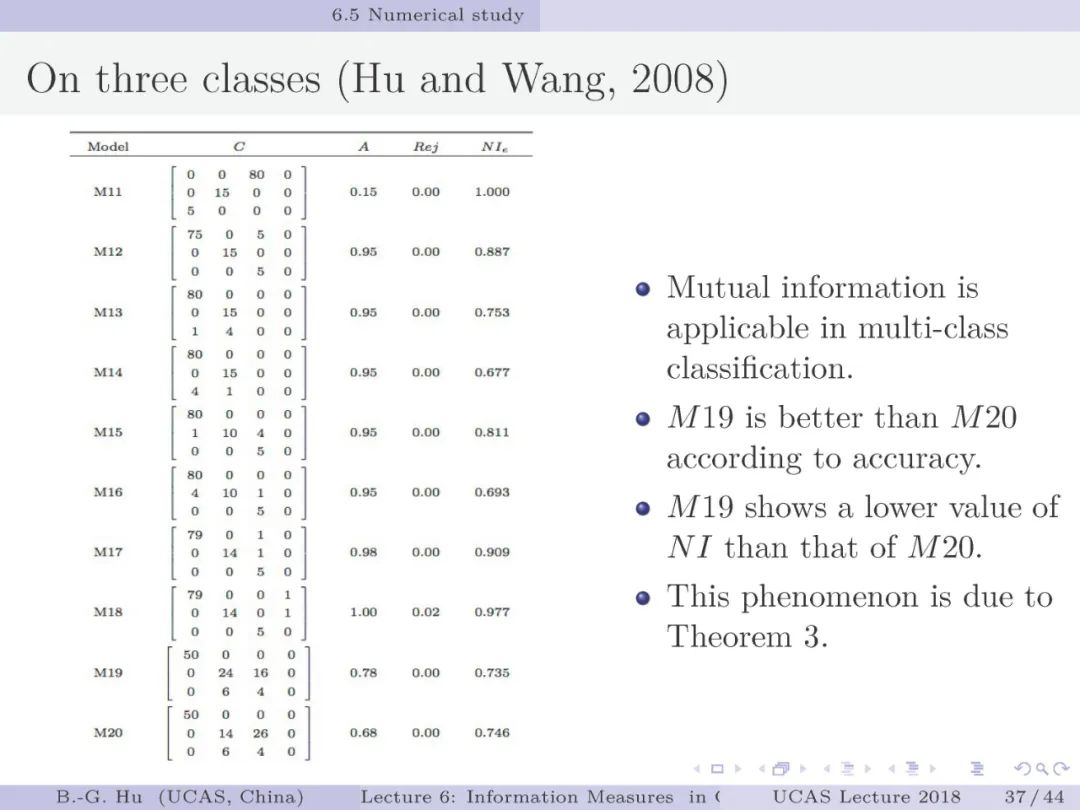
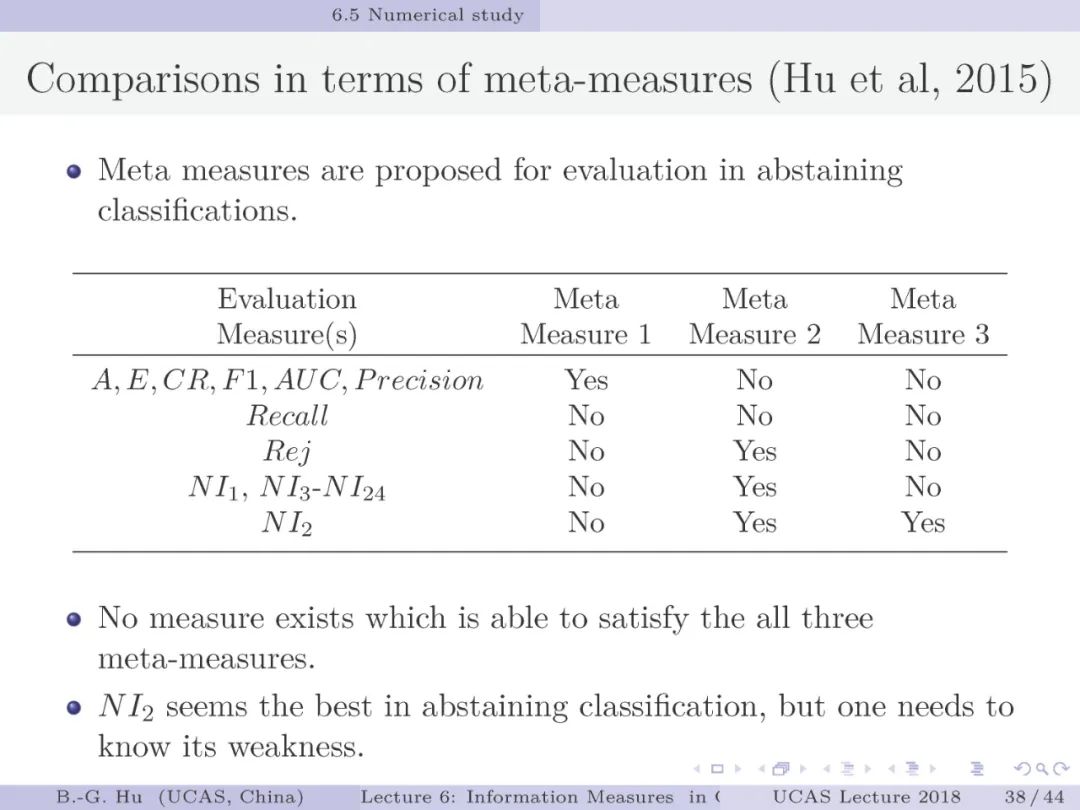
第38页: 考察了主要分类性能指标及24个信息指标与三个元准则之间的关系。目前没有一个传统性能指标能够处理拒识分类并可以考察拒识类别。其中信息指标NI_2的具体定义见第七章。互信息指标不满足第一元准则,具体实例见第37页中M19-与M20例题。想想该现象根源是什么?
作业:
1. 讨论题:如果将多类分类混淆矩阵对角线元素总和视为两个随机变量的相似性度量,应用该度量为横轴,混淆矩阵的互信息为纵轴。那么你认为它们之间的关系曲线大体上是什么形状,是单调的吗?(提示:先考虑两个端点,之后应用定理3。)
2. 讨论题:定理3是否意味应用互信息为相似性度量工具会有问题?包括应用在图像配准或特征选择中?
3. 思考你能否发展出一种指标可以全部满足三个元准则吗?
附录
这里介绍我与董未名教授合作发表的一篇观点文章“格数致知:走向对世界的深度认知”[1]。“格数致知”说法是借鉴古代东西方哲人思想后,将东西方智慧相融合的一种创新尝试。它的具体解释是:“推究事物之内在本源,获取知识之数学表达”。我们以人工智能发展背景来讨论,在强调数学工具必要性同时,也指出应用方面与本质方面可能存在的问题。这个世界本质上是属于无监督(没有标准答案)学习为内涵,人类对世界认知犹如“盲人摸象”(如第一章第54页)或“坐井观天”,我们需要依赖大数据从更高维度以数学方式去认知真实世界[2]。
此课教学我们特别强调“个人思考”。个人见解可容错,独立思考方有成。第一章中我们有“学而不思则罔,思而不学则殆”的英文翻译(第一章第27页)。这是查阅翻译反复推敲后给出个人见解。其中加上关键词“知识”,明确了“学”与“思”的目标对象是什么 。由此正好契合于考察机器学习或人工智能研究。2017年3月深度学习开创者之一杨立昆(Yann LeCun)教授访问我们模式识别国家重点实验室并做精彩讲座之后,我提问中包括向他介绍了这个翻译,并认为目前深度学习或阿尔法狗似乎缺少“思”的部分。他的反应是头一次听到这样有道理的古代东方说法。由此可以理解学习前人是为了不断发展。向世界介绍并发展东方文化中的科学内涵应是中国学者的使命?东方特色讲究“包容(本质是“人文”)”,西方特色讲究“科学”。两种文化无有对错而只含利弊。学习西方文化不应丢弃东方文化优势。我喜欢中国文化哲理,比如“厚德载物”,“和而不同”、“仁者爱人”、“天人合一”、“天下为公”、“修身齐家治国平天下”等思想,可以看到东方智慧中一种“大我”、"大爱”以及“大美”之境界。“包容”与“科学”传统应是“互补而非竞争(模糊理论之父扎德对不同理论学派的用语[3])”。当世界变为地球村时,人类社会之间的“包容”以及“中庸之道”是否会并变得更为重要?我们应该向社会学家费孝通先生学习,从“天下大同”创新为“各美其美,美人之美,美美与共,天下大同”思想。要理解从来没有一门学科会像人工智能学科这样需要各种学科的“综合”思考。没有人文精神指导下的科学研究会否走偏?人类如何不成为自己创造工具下的奴隶?这些都为我们提供了更大的创新研究空间。
鼓励同学们发展宏观层面开放与跨领域思考的尝试,只是硕士或博士论文中如果没有“小心求证”工作可要小心哟?
1. https://en.wikipedia.org/wiki/Receiver_operating_characteristic
2. https://arxiv.org/abs/1901.01834
3. https://zhuanlan.zhihu.com/p/79100698
4. Zadeh, L. A., "Discussion: Probability theory and fuzzy logic are complementary rather than competitive", Technometrics, 37(3), 271-276, 1997.
前期课程链接:
第一讲:
国科大UCAS《信息论与机器学习》课程,中国科学院自动化研究所胡包钢研究员
第二讲:
国科大UCAS胡包钢教授《信息论与机器学习》课程第二讲:信息论基础一
第三讲:
国科大UCAS胡包钢教授《信息论与机器学习》课程第三讲:信息论基础二
第四讲:
熵与其它信息量估计—国科大UCAS胡包钢教授《信息论与机器学习》课程第四讲
第五讲:
二值分类熵界分析—国科大UCAS胡包钢教授《信息论与机器学习》课程第五讲
课件文件:



































附录文件:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ITML2020” 就可以获取《国科大UCAS《信息论与机器学习》课件》专知下载链接





