超人总动员「真人版」长啥样?图像转换框架「pSp」让你变成「巴小飞」

新智元报道
【新智元导读】前几天的迪士尼风格的图像转换你试了吗?近期,国外研究人员又提出了一个通用的图像到图像的转换框架:Pixel2Style2Pixel(pSp),可以将皮克斯风格的动画角色变成同样风格的真人图像。
近年来,GAN已经具有非常好的图像合成功能,尤其是在人脸图像上,最新的图像生成方法已经实现了很高的视觉质量和保真度,现在可以生成逼真的图像。
而该团队专注于更广泛的隐空间的嵌入,旨在检索潜在的生成所需要的但不一定已经知道的图像的向量。
为此,他们引入了一种新颖的编码器架构,该架构的任务是将任意图像直接编码为隐空间W +。同时,使用了皮克斯动画里的角色进行测试,效果也是非常的感人:


是不是从皮克斯动画角色生成的「真人」,也非常动漫化呢?

蒙娜丽莎「现代版」也许长这样:

全新的框架:Pixel2Style2Pixel
全新的框架:Pixel2Style2Pixel
在最近发表的论文《Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation》中,来自 Penta-AI 和特拉维夫大学的研究人员介绍了一种通用的图像转换框架,称为 Pixel2Style2Pixel (pSp)。
与以往使用专用任务特定架构的方法不同,该论文提出的框架旨在使用相同的架构来解决各种图像到图像的任务,这是一种避免可能出现的局部偏差的全局方法。 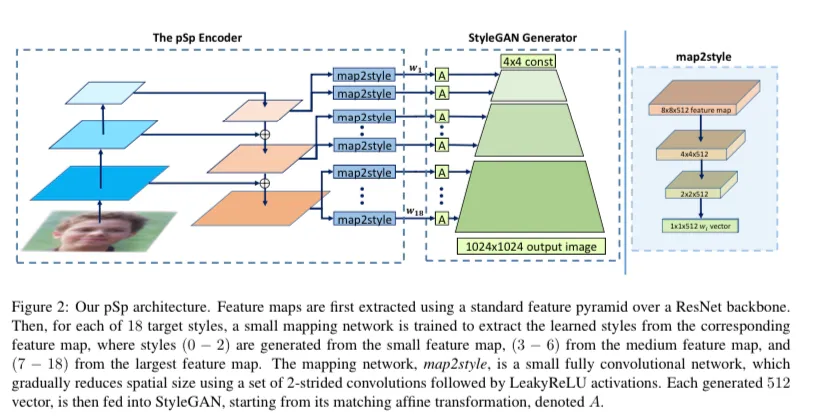
pSp框架是基于一种全新的编码器网络,直接生成一系列的风格向量,这些向量被输入预先训练好的StyleGAN生成器,形成扩展的W+潜在空间。
pSp是一个简单的架构,可以很容易地应用于image2image的转换任务。
通过样式表示来解决这些问题会产生一种不依赖于局部像素到像素对应的全局方法,并通过样式的重采样进一步支持多模态合成。

面部对齐
值得注意的是,我们证明了pSp可以在不使用任何标记数据的情况下将人脸图像与正面姿态进行对齐,可以为模糊任务生成多模态结果,如从分割图片生成条件人脸,并从相应的低分辨率图像构建高分辨率图像。

该方法在人脸前端化等任务中显示出强大的优势,其编码器可以在完全无监督的情况下训练,以一些表情将给定的人脸图像对齐。 
研究人员指出,尽管最先进的图像生成方法 StyleGAN 可以生成具有现实感的图像,但它也有一个分离的潜在空间 w,在那里可以进行有意义的操作。
条件图像合成
由于利用潜在空间的各种方法都显示出了良好的图像到图像的转换效果,将真实图像编码到扩展潜在空间 w + 中已成为研究人员的一种常用方法,在高分辨率合成、多模态图像合成、多域图像合成、条件图像合成等领域有着广泛的应用。

然而,快速、直接、准确地将真实图像转换成 w + 仍然是一个挑战。该小组专注于后期空间嵌入的任务,其目的是检索一个生成期望的(未必知道的)图像的向量。
超高分辨率
在这里,作者还证明了他们的框架可用于从相应的低分辨率(LR)输入图像构造高分辨率(HR)面部图像。

由于该编码器是基于特征金字塔网络,样式特征向量提取自各种金字塔尺度,并直接插入到一个固定的、对象再训练的 StyleGAN 生成器中,以配合技术空间的尺度。
研究人员观察到,当一个网络被训练时,其 ID 相似性损失与以前的直接方法相比,会表现出更好的效果。
在实验中,该团队证明了他们的image2image转换框架pSp在各种应用程序中取得了引人注目的结果,同时提出了一种通过样式重采样进一步支持多模态综合的全局方法。
他们还表明,一些固有的假设需要进一步验证,例如:由于提出的方法没有利用「局部性」,保留诸如耳环或背景细节等输入图像的精细细节已成为一个挑战。
参考链接:
https://www.reddit.com/r/MachineLearning/comments/jcuch4/p_creating_real_versions_of_pixar_characters/
https://arxiv.org/pdf/2008.00951.pdf


