华为诺亚、北大提出GhostNet,使用线性变换生成特征图,准确率超MobileNet v3 | CVPR 2020


受限于内存空间和计算资源,将卷积神经网络部署到嵌入式设备中会比较困难。CNNs中特征图的冗余性是保证其成功的关键,但是在神经网络的结构设计中却鲜有研究。
本文提出了一个全新的Ghost模块,旨在通过极其小的代价操作生成更多更丰富的特征图。基于一组固有的特征图,作者应用一系列线性变换,以很小的代价生成许多能充分揭示固有特征信息的虚特征图(Ghost feature maps)。
新提出的Ghost模块可以作为一个即插即用的组件来升级现有的卷积神经网络,通过将Ghost模块堆叠得到Ghost bottlenecks,然后就可以轻易的构建出轻量级的Ghost网络——GhostNet。实验证明了Ghost替代传统卷积层的有效性,在ImageNet分类数据集上,与MobileNet v3相比,GhostNet在相似计算复杂度的情况下,top-1 上的正确率达到75.7% 。

引言
深度卷积神经网络在诸如目标识别,目标检测,实例分割等任务上都取得了很大的进步。为了获得更好地准确率表现,传统的卷积神经网络需要大量的参数和浮点运算,在ResNet-50中,大约有25.6M的参数,如果需要处理一张224x224的图片,需要的浮点数计算有4.1B。这种需求需要巨大的存储空间和算力要求。对于嵌入式设备和移动计算来说基本不可能。
因此,需要探索同时兼顾轻量级和效率的网络结构来满足移动计算的需要。在过去的几年,有很多探索轻量级网络的方法被提出,代表性的有网络剪枝,知识蒸馏等,除此之外,高效的神经网络结构设计在建立高效的、参数和计算较少的深度网络方面具有很高的潜力,并且最近已经取得了相当大的成功。这种方法也可以为自动搜索方法提供新的搜索单元,代表性的有MobileNet系列,将传统卷积方法拆分为深度卷积和点卷积。
ShuffleNet主要思路是使用Group convolution和Channel shuffle改进ResNet,可以看作是ResNet的压缩版本,进一步提升了轻量模型的性能。在一个训练良好的深度神经网络特征图中,通常会包含丰富甚至冗余的信息,以保证对输入数据有全面的理解。如下图所示,在ResNet-50中,将经过第一个残差块处理后的特征图拿出来,其中三个相似的特征图使用相同颜色的框圈出。其中一个特征图可以通过对另一个特征图进行简单的变换(用扳手表示)来近似得到。这些相似的特征映射对,就类似彼此的虚像,作者用Ghost表示,十分形象。

由此可见,特征图中的冗余度是深度神经网络成功的重要保证。作者并没有刻意避免冗余的特性图,而是倾向于采用它们,但是以了一种低成本的方式。
在本文中,作者引入了新的Ghost模块,旨在通过更少的参数生成更多更丰富的特征。具体来说,Ghost模块将传统的卷积层划分为两部分。第一部分就是常规的卷积但是它们的数量会受到严格的限制。将第一部分得到的特征图作为固有卷积,应用一系列的线性变换生成更多特征图。在不改变输出特征图尺寸的情况下,与普通卷积神经网络相比,Ghost模块的参数总需求和计算复杂度都有所降低。GhostNet就是在Ghost模块的基础上建立的。
作者首先在基准神经架构中替换原有的卷积层来证明Ghost模块的有效性,然后在多个数据集上验证GhostNets的性能。实验结果表明,所提出的Ghost模块在保持相似的识别性能的同时,能够有效降低计算成本,并且GhostNets能够超越目前最先进的深度模型模型MobileNetV3,适用于移动计算。

相关工作
目前对于轻量神经网络的设计主要有两大方法:模型压缩和紧凑模型设计。
模型压缩
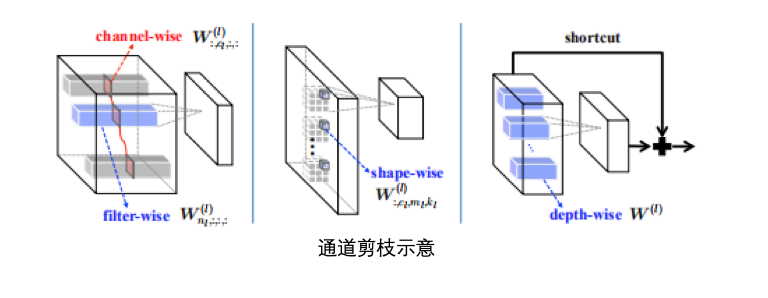
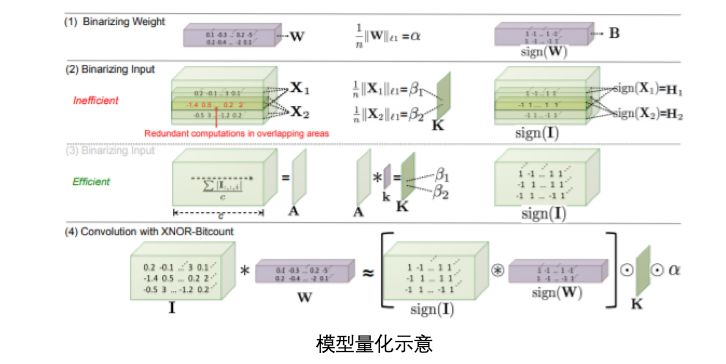
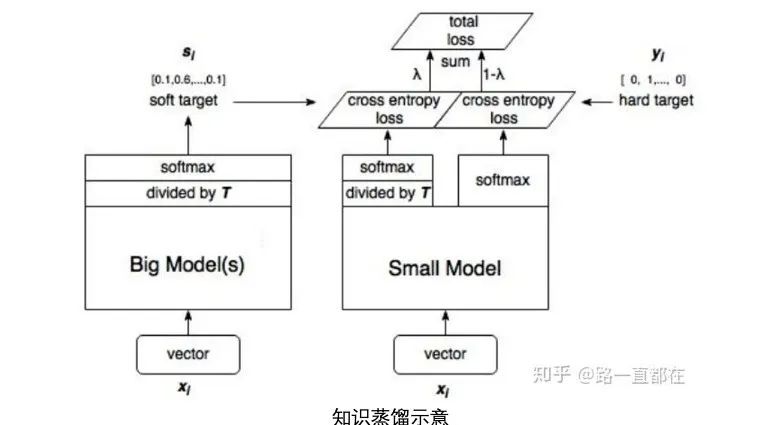
对于给定的神经网络,模型压缩的目的是减少计算和存储成本。连接剪枝将那些不重要的神经元连接剪掉,通道剪枝将无用通道去除,实现计算加速。模型量化用离散值表示神经网络中的权重,实现压缩和加速。知识蒸馏将网络分为教师网络和学生网络,旨在通过强大的教师网络得到兼具正确率和轻量的学生网络。
紧凑模型设计
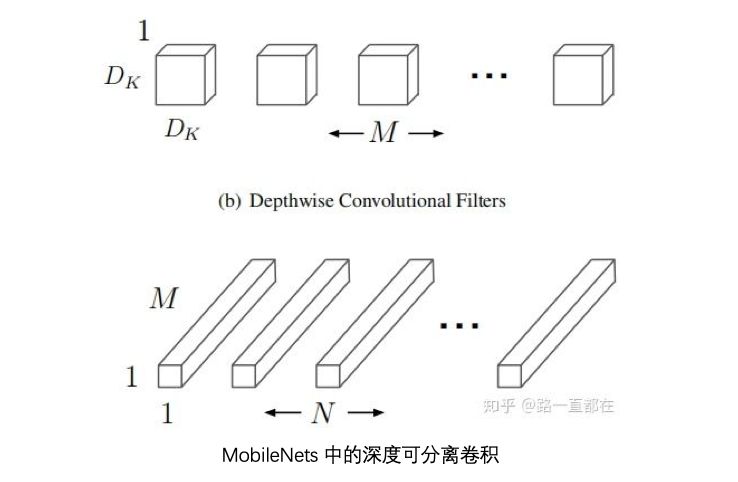
为了将神经网络嵌入到移动设备上,近年来提出了很多紧凑型网络。SqueezeNet利用bottleneck结构在比AlexNet减少50倍参数的基础上,达到了相似精度。MobileNets是一系列基于深度可分卷积的轻量级深度神经网络,经过三个版本的进化迭代,实现了很高的精度。ShuffleNet引入了shuffle机制,改进了通道组之间的信息流交换。虽然这些模型获得了很好的性能,但是特征图之间的相关性和冗余性一直没有得到很好的利用。

方法
Ghost 模块
深度卷积神经网络通常包含大量的卷积计算,导致需要大量的计算成本,对移动计算,嵌入式设备来说很不现实。而事实上,主流CNNs的中间特征图中有广泛存在的冗余。作者提出通过减少诸如CNNs中的卷积核数量等来减少所需的资源需求。给定输入数据X,表示为:
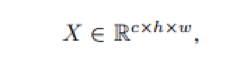
其中,c是通道数,h,w分别表示输入数据的高和宽。任意卷积层生成n个feature map的操作可以表示为:
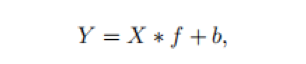
其中,*表示卷积操作,b是偏置项,此时得到的特征图Y维度信息为[h’ x w’ x n],需要的卷积核f维度信息为[ c x k x k x n ]。
接下来计算一下这个卷积过程需要的浮点数(FLOPs):
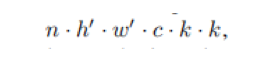
这个数据量高达数十万,因为卷积核的数目n和通道数目c通常都非常大(例如256或512)
回顾常规卷积计算过程我们可以知道,要优化的参数(在f和b中)的数量由输入和输出特征映射的维数显式地确定,又因为卷积层的输出特征图往往包含大量的冗余,有些可能是相似的。作者认为没有必要用大量的FLOPs和参数一个个地生成这些冗余的特征图。设输出的特性图是通过对固有特性图进行简单转换后得到的“幽灵”(Ghost)特征图。这些固有的特征图由常规卷积产生且尺寸较小。假定,现在的固有特征图Y’维度信息为[h’ x w’ x m ],可以通过一个普通卷积操作生成:
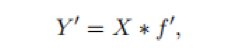
其中,f'维度为[c x k x k x m]。与上文中普通卷积的卷积核f相比,m小于等于n。其他的超参数诸如卷积核尺寸,填充方式,步长等都与普通卷积保持一致以此确保输出的特征图空间大小与普通卷积相同。在保证了空间尺度相同的情况下,现在需要得到n维的feature maps,现在固有的feature maps只有m维。为此,作者对这些固有feature maps进行一系列简单线性变换。具体公式为:
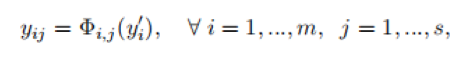
其中, 表示固有feature maps中的第i个特征图, 表示对第i个feature map进行的第j个线性变换,也就是说,某一层feature map可能对应多个线性变换,得到多个变换结果。在变换的最后,还需要增加一个同等映射,也就是将固有的feature maps原封不动的叠加到变换后的feature maps上去,以此保留固有特征中的信息。通过上式,我们可以得到经过Ghost模块后的n维特征图Y=[y11,y12,...,yms],n=mxs,示意图如下:
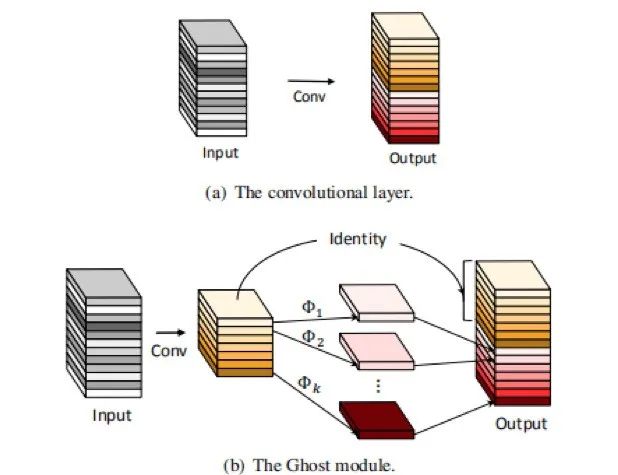
与现有方法的不同:
与那些利用1x1点卷积的方法相比,Ghost模块对固有卷积的操作可以不限制卷积核大小。
现有的方法]采用逐点卷积跨通道处理特征,然后采用深度卷积处理空间信息。与之相反,Ghost模块首先通过普通卷积操作生成小数量的固有特征图,此时的空间大小信息已经固定,只需要再通过简单的线性变化进行空间通道的扩充和丰富。
在过去的结构中,处理每个特征图的操作仅限于深度卷积或移位操作,而Ghost模块中的线性操作可以具有较大的多样性。
在Ghost模块中,同等映射与线性变换并行,以保持原有的特征映射。
GhostNets的构建
Ghost Bottlenecks
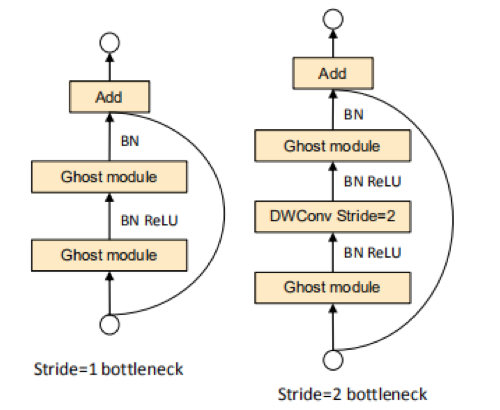
ResNet中的bottleneck结构大家非常了解,作者针对Ghost模块,专门为小卷积构建了bottlenecks。如下图所示,与ResNet中的结构很相似,在Ghost中,bottlenecks主要由两个堆积的Ghost模块构成,第一个Ghost模块的作用是扩展特征图的通道数,我们把输出通道数与输入通道数之比称为扩展比。第二个Ghost模块的作用是减少通道数来匹配捷径路径(shortcut path)。然后将这两个Ghost模块的输入和输出连接起来,除了按照MobileNetV2的建议在第二个Ghost模块之后不使用ReLU外,每一层之后都使用batch归一化(BN)和ReLU进行非线性激活。下图是针对步长为1和2时的结构。当步长为2时,shortcut通过下采样实现,且在两个Ghost模块间插入步长为2的深度卷积。
有了Ghost bottlenecks,接下来开始构建GhostNets。作者参考了MobileNetV3的基本架构,利用Ghost bottlenecks代替了MobileNetV3中的bottlenecks。在GhostNets中,第一层是有16个卷积核的普通卷积,然后是一系列通道数逐渐增加的Ghost bottlenecks。这些Ghost bottlenecks根据其输入特征图的大小被分组到不同的阶段。所有的bottlenecks步长均为1,除了最后一个为2。最后利用全局平均池化和卷积层将特征图转化为一个1280维的特征向量进行最终分类。SENet中的挤压激励模块(SE)也适用于某些bottlenecks层。与MobileNetsV3不同,GhostNets并没用应用hard-swish激活函数,因为它的延时性很高。
宽度系数
尽管给定架构已经可以提供低延迟和保证精度,但在某些场景中,我们可能需要更小、更快的模型或更高的特定任务的精度。定制所需的网络需求,可以在每一层简单地乘以一个系数α来加宽网络。这个因子α称为宽度乘数,因为它可以改变整个网络的宽度。宽度乘数可以控制模型大小和计算成本大约α平方。

实验
数据集:CIFAR10,ImageNet,MS COCO
Ghost模块有效性实验
我们已经知道在卷积过程中生成的特征图中有一些相似的特征映射对,它们可以通过一些线性操作来有效地生成。作者首先进行实验来观察原始特征图和生成的Ghost特征图之间的重构误差。
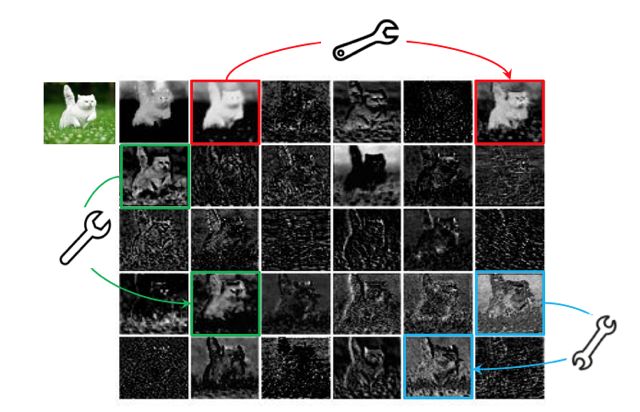
以上图中的的三对特征映射为例,将左边的特征作为输入,另一个作为输出,利用一个小的深度卷积滤波器来学习映射,代表它们之间的线性操作。利用均方差MSE作为评价标准,结果如下图所示,可以看到,MSE值非常小,表在深度神经网络中,特征图之间存在很强的相关性,这些冗余特征图可以由多个固有特征图生成。
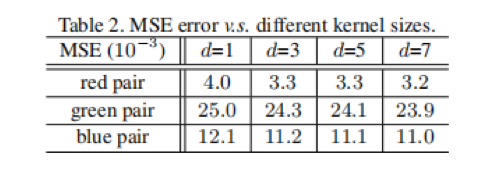
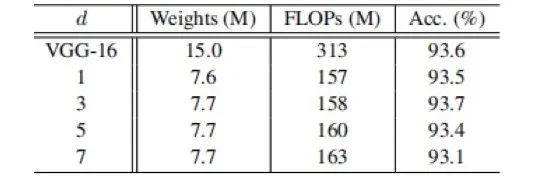
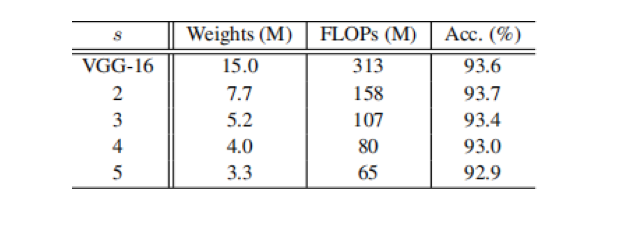
除了上述实验中用到的卷积,我们还可以探索其他一些低成本的线性操作来构造Ghost模块,如仿射变换和小波变换。然而,卷积是一种高效的运算,已经得到了当前硬件的良好支持,它可以涵盖许多广泛使用的线性运算,如平滑、模糊、运动等。在Ghost有两个超参数,分别是线性转换中的卷积核大小d和步长s,结果如下所示,可以看到,提出的d=3的Ghost模块比较小或较大的Ghost模块性能更好。这是因为尺寸为1×1的卷积核不能在feature maps上引入空间信息,而尺寸较大的卷积核如d = 5或d = 7会导致过拟合和计算量增加。
因此,我们在接下来的实验中采用d = 3进行实验。s与得到的网络的计算代价直接相关,s越大,压缩比越大。当我们增加s的时候,FLOPs明显减小,准确率逐渐降低,这与预期一致。特别是当s = 2表示将VGG-16压缩2倍时,本文方法的性能甚至比原模型稍好一些,说明了所提出的Ghost模块的优越性。
CIFAR-10实验结果
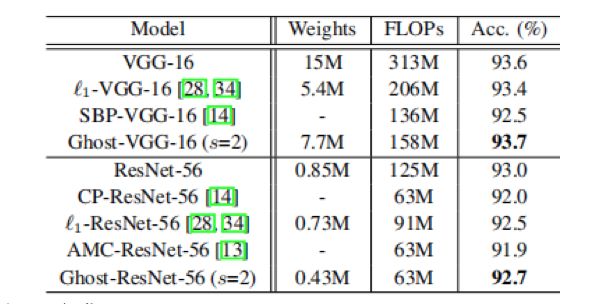
作者将Ghost模块嵌入VGG-16和ResNet-56中,得到新的网络结构,称为Ghost-VGG-16和Ghost-ResNet-56,利用CIFAR-10数据集评估Ghost模块。结构如下图所示,我们将GhostNet与VGG-16和ResNet-56架构中具有代表性的最新模型进行了比较,对于VGG-16,本文模型得到的精度略高于原始的模型且速度快2倍以上,说明VGG模型存在较大的冗余
特征图可视化
如下图所示,通过ghost模块得到的特征图,虽然生成的feature maps来自于固有的feature maps,但是它们确实有显著的差异,这意味着生成的feature足够灵活,可以满足特定任务的需要。左上角的图像为输入,左边红色框中的feature maps来自于固有卷积,右边绿色框中的feature maps来自于经过Ghost模块后的特征输出。

ImageNet实验结果
将Ghost模块嵌入到标准的ResNet- 50中,并在ImageNet数据集上进行实验。结果如下表所示,在两倍多加速的情况下,本文的方法可以获得明显更好的性能。当s增加到4时,模型精度下降了0.3%,计算速度提高了4倍左右。相比之下,采用相似权重或FLOPs的比较方法的性能要差得多。
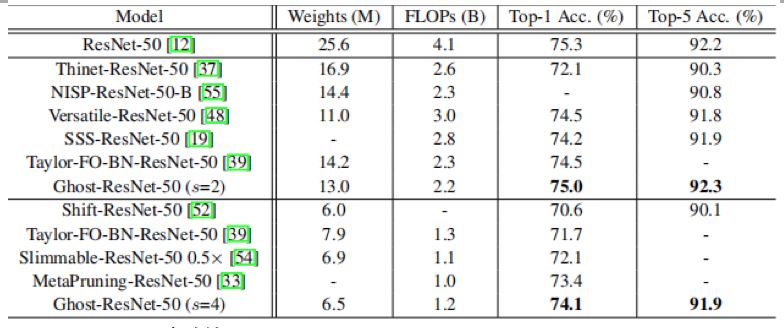
GhostNet实验结果
下表是最先进的小网络在ImageNet上的实验结果,可以看到,GhostNet超越了SOTA,兼顾了速度和准确率。
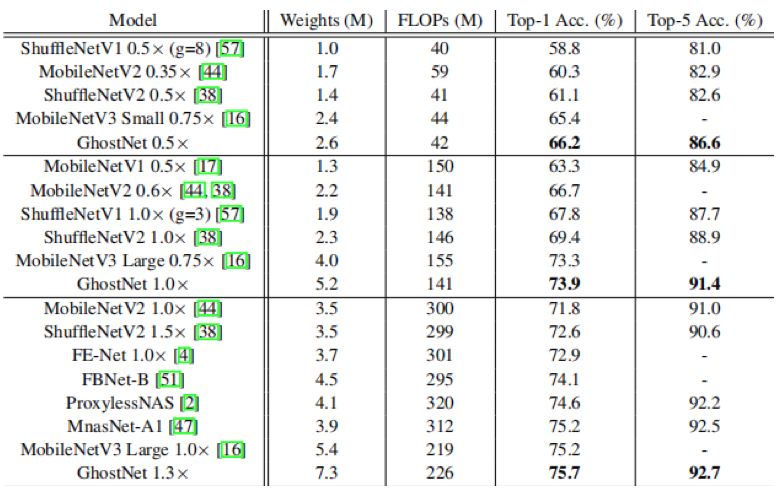

结论
为了降低当前深度神经网络的计算成本,适应移动计算的需求。本文提出了一种新的Ghost模块,用于构建高效的神经网络结构。基本的Ghost模块将原始的卷积分为两部分,首先利用较少的卷积核生成几个固有特征图,在此基础上,进一步应用一定数量的线性变换操作,有效地生成丰富的特征图。
在基准模型和数据集上的实验表明,该方法是一种即插即用的模型压缩方法,可以将原始模型转换为紧凑模型,同时保持可比较的性能。此外,使用新的Ghost模块构建的GhostNet在效率和准确性方面都优于最先进的轻量级神经网络架构。




