CE-Net:用于2D医学图像分割的上下文编码器网络,已开源!
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:摸鱼家
https://zhuanlan.zhihu.com/p/68953780
本文已授权,未经允许,不得二次转载
CE-Net: Context Encoder Network for 2D MedicalImage Segmentation

作者团队:上海大学&中科院&上海科技大学等
arXiv:https://arxiv.org/abs/1903.02740
github:https://github.com/Guzaiwang/CE-Net
1. Abstract
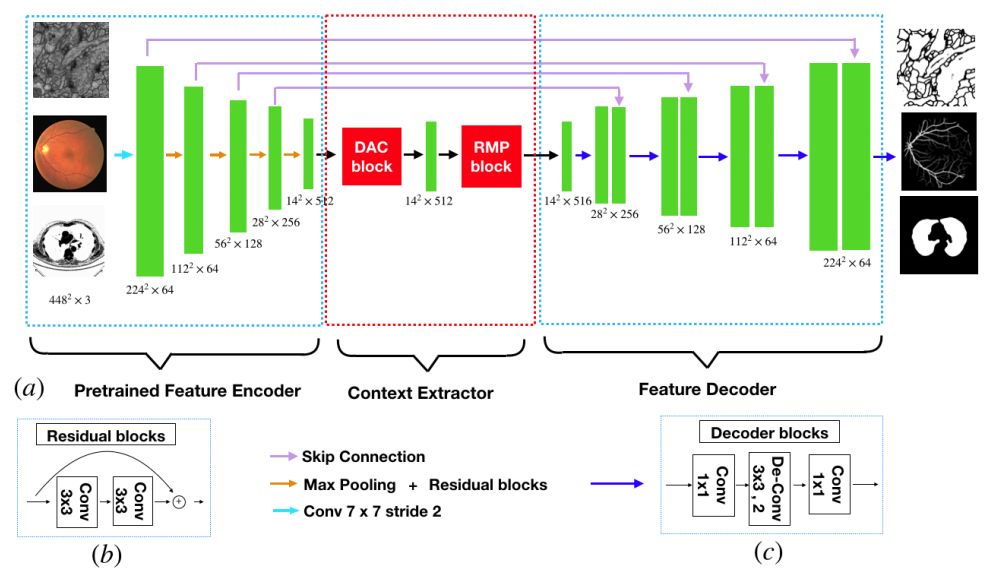
提出了一种用于医学图像分割的网络结构,创新点在于在传统的encoder-decoder结构中间加入了context extractor,用来减少由于池化和卷积导致的信息损失。
2. Introduction
传统的医学图像分割方法,深度学习的方法,主要是U-Net,然后是一些其他修改方法,如CRF,使用了多尺度的M-Net,BRU-net,InfiNet
使用了residual connectio来避免梯度消失。
提出了DAC block(dense atrous convolution )提取更多的去全局语义信息。the DACblock is proposed to extract enriched feature representationswith multi-scale atrous convolutions
提出了residual multi-kernel pooling (RMP) ,它是受空间金字塔池化的启发,对DAC的输出进行多尺度的信息编码??RMPblock for further context information with multi-scale poolingoperations 大概的意思就是,DAC进行多尺度特征提取,RMP进行池化。
总结来说,本文的主要贡献就是提出了DAC和RMP block,并将其整合到基于encoder-decoder框架中,来进行医学图像的分割。
3. Conclusion
提出了end-to-end的网络,能够提升多个医学图像分割的表现,相信后续也可能扩展到其他医学图像的分割上,或者扩展到3D。
4. Methed
· Feature Encoder Module
· 基于ResNet-34
· Context Extractor Module
· 本文提出的,由DAC和MRP组成,作者的说法是提取语义信息,产生更高层次的feature map
· 这个模块输入输出尺寸是一样的,也就是说,这个模块可以用在其他任何结构中。
· Dense Atrous Convolution
· 在这篇论文里,空洞卷积组成的模块是加在encoder之后的,另一篇论文(MULTI-SCALE CONTEXT AGGREGATION BYDILATED CONVOLUTIONS)也使用了类似的结构,不过它的模块是由串联的空洞卷积组成的。这篇文章里的dense atrous convolution (DAC)模块是用了并联,和GoogLe Net的inception模块类似。
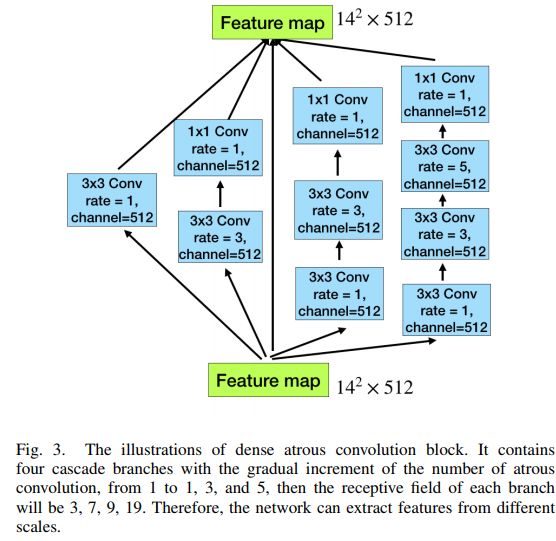
· 具体来说,每个并联分支使用了不同尺寸的空洞卷积,便于提供不同的感受野,能够针对不同大小的目标。
· Residual multi-kernel pooling (RMP )
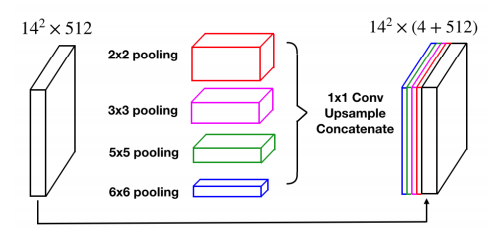
· 这个模块连接在DAC之后,使用不同的池化方式并联,作者的说法是为了提供不同的感受野
· 为了减少参数,在每一层之后加入了1*1的卷积
· Feature Decoder Module
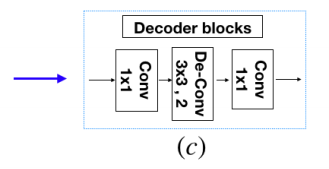
· decoder部分使用了转置卷积进行上采样,每个部分如下:卷积—转置卷积-卷积,这里没有采用和encoder的对称结构。
· Loss Function
· Dice coefficient loss function ,因为医学图像目标都比较小
5. 实验
· 在不同的医学图像进行了比较,如视杯视盘,血管等
· 血管分割的评价使用了3种方式,相关论文如何评价还可以再看看

Reference
CE-Net: Context Encoder Network for 2D Medical Image Segmentation
CVer-医疗影像交流群
扫码添加CVer助手,可申请加入CVer-医疗影像群。一定要备注:研究方向+地点+学校/公司+昵称(如医疗影像+上海+上交+卡卡)

▲长按加群
这么硬的论文分享,麻烦给我一个在在看

▲长按关注我们
麻烦给我一个在看!



