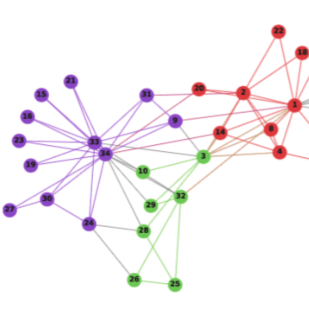
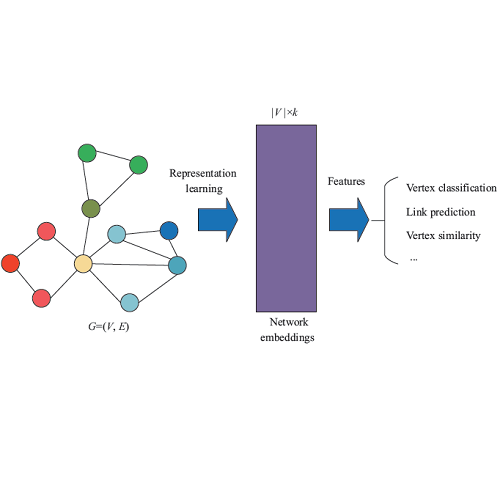
【WWW19论文笔记】Google AI 提出学习捕获多个社交上下文节点的表示(附代码)
【导读】论文提出的Splitter是一种无监督的嵌入方法,允许图中的节点可以嵌入多个向量,以便更好地表示节点在一些重叠社区的参与。直观地说,这是因为图中的每个节点通常会在单个上下文中与给定的邻居节点产生交互。作者也Open了代码,Star 三千多。

1 论文贡献
论文中继承并拓展了persona graph方法。这种方法给定一个图G,创建一个新的图G(p)(叫做G的persona graph),图中的每个节点u由一系列的replicas(副本)表示。这些在G(p)中的复本节点表示节点u在其所属社区中的实例化。Persona graph方法最初是用来获取重叠区域的。
这篇论文的贡献如下:
(1) 提出的Spliter是一种新奇的嵌入方法,可以把图中的每一个节点编码成多个 嵌入向量,这一点依赖于对现实网络中的区域重叠结构的分析。
(2) 我们的方法给优化器添加了图正则化约束,使得所学到的每一个节点的多个表示保持一致。
(3) 该方法可以通过对节点的邻近区域的分析,自动确定每一个节点所拥有的多个嵌入的数量。
(4) 对于链接预测这一重要任务,我们在多个embedding baseline方法的基础上进行了实验验证。
(5) 我们的方法可以可视化如何发现多个节点的社区成员。
2 模型Splitter介绍
G= (V,E)是一个无向图,由节点集V和边集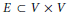
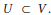
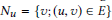
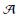
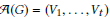
Persona Decomposition
在图Gp中的节点,被称作personas,把在图G中每一个原始节点的交互划分为几个语义上的子图,这些子图可以捕捉网络行为中的不同部分。让我们假设有一个图G和一个聚集算法 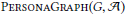
(1) 对于每一个节点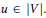
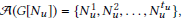
(2) 创建personas的节点集V,V中的每一个节点V0将对应于Vp中的tv0 personas.
(3) 在personas之间添加边。如果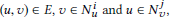
经过上述流程处理之后,所获得的persona graph Gp有许多有趣的属性。首先,Gp中的每个节点是来自原始图的一个结点,划分成了一个或者更多的personas。图Gp中边的数量等于personas 图中边的数量。这意味着需要存储Gp的空间和personas graph一样。第二,原始图中的每个节点可以被隐射到他对应的personas,但是Gp的社区结构与原始图有很大不同。
Graph Embedding
embedding方法的目标是学习一个特征,其能够估计短随机游动子窗口中顶点vi与其他节点相似性。
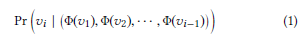
但是要精确的计算条件概率需要增加随机游动的长度,但这会导致巨大的计算代价,DeepWalk使用两种技巧来应对这一挑战:1.忽略相邻节点的顺序。2.逆转整个学习过程:不使用上下文来预测缺失的顶点,而是使用顶点本身来预测其局部结构.
DeepWalk中的这些修改导致在计算每个节点特征时的优化问题:
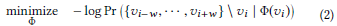
在DeepWalk模型中,节点v(i)和v(j)相似的概率使用softmax计算如下:
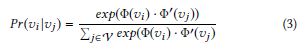

Learning Multiple Node Representations
使用上面介绍的persona 分解,我们把输入的图G转变为角色图(persona graph )Gp。从这里看,这似乎是现有方法的一个直接应用,即去学习每个节点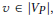
首先,我们建议添加一个约束,即除了在Gp中预测persona周围的persona之外,persona特征还能够预测其原始节点。具体来说,给定一个persona vi,我们获取他的特征包括对原始图G中节点vo的依赖:

为了控制图正则化的强度,我们引入参数 λ,通过结合方程2产生下列的优化问题:

Splitter算法

上述算法中的2-4行初始化数据结构,构造persona graph,学习原图的embedding。我们注意到并不是所有的节点都必须被分割;根据上述中的描述,这取决于每一个ego-net的结构。
第5-8行使用persona graph去初始化persona的特征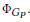
第9-17行详细的描述了persona 特征是如何被学习的。其中第12行生成随机游动来采样每个顶点的上下文。第十五行计算persona graph中节点造成的损失(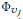
Optimization
我们使用分层的softmax来计算概率更加有效。使用噪声对比评估这一优化策略。我们的模型参数集包括 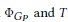
最后,简要的介绍一下论文中多次提到的Deepwalk.
DeepWalk的思想类似word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。那么关键的问题就是如何来描述节点与节点的共现关系,DeepWalk给出的方法是使用随机游走(RandomWalk)的方式在图中进行节点采样。
RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。
获取足够数量的节点访问序列后,使用skip-gram model 进行向量学习

构建同构网络,从网络中的每个节点开始分别进行Random Walk采样,得到局部相关联的训练数据;
对采样数据进行Skip-Gram训练,将离散的网络节点表示成向量化,最大化节点共现,使用Hierarchical Softmax来做超大规模分类的分类器。
论文链接:
https://arxiv.org/abs/1905.02138
代码链接:
https://github.com/google-research/google-research/tree/master/graph_embedding/persona
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程