调戏微软文言文AI翻译:“永不舍汝”、“其母之”是什么鬼???
![]()
来源:量子位
本文约2075字,建议阅读5分钟
本文介绍了百度与微软在翻译文言文方面的"较量"。


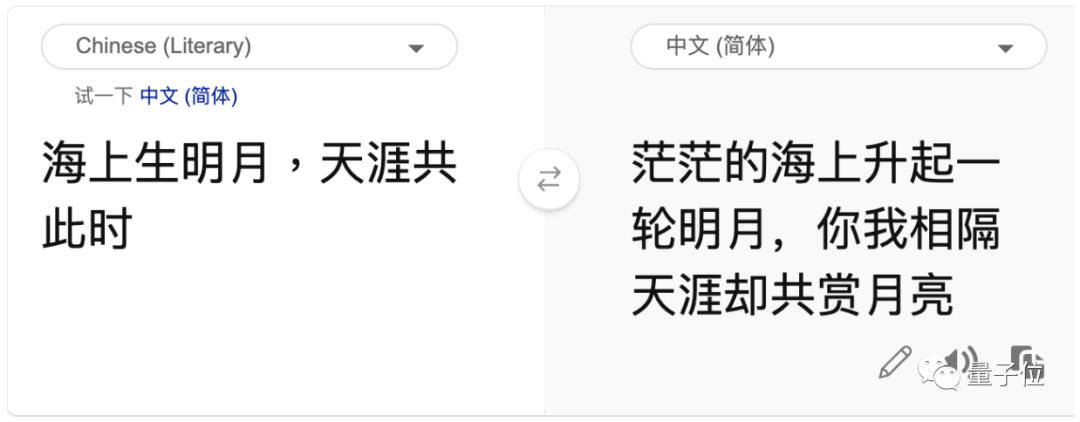
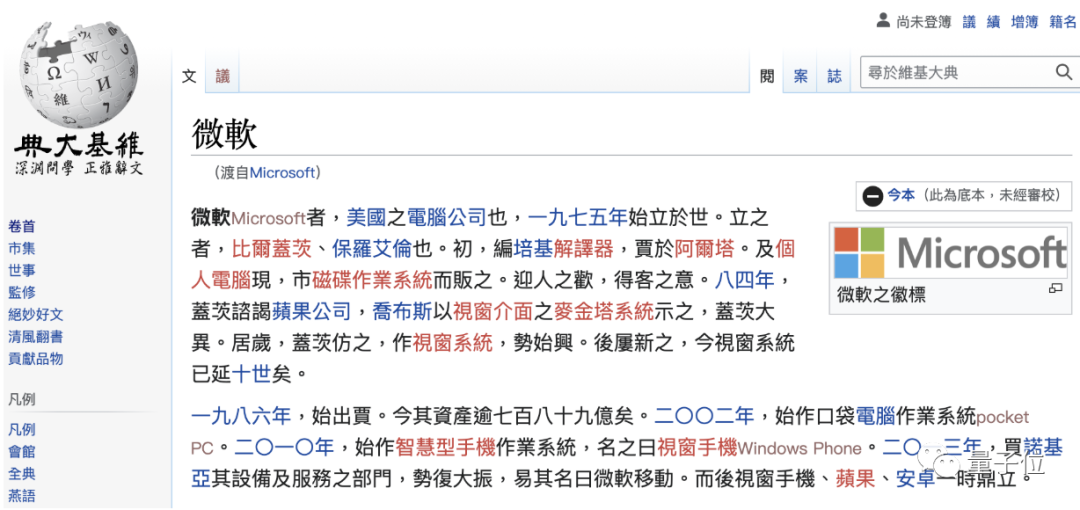
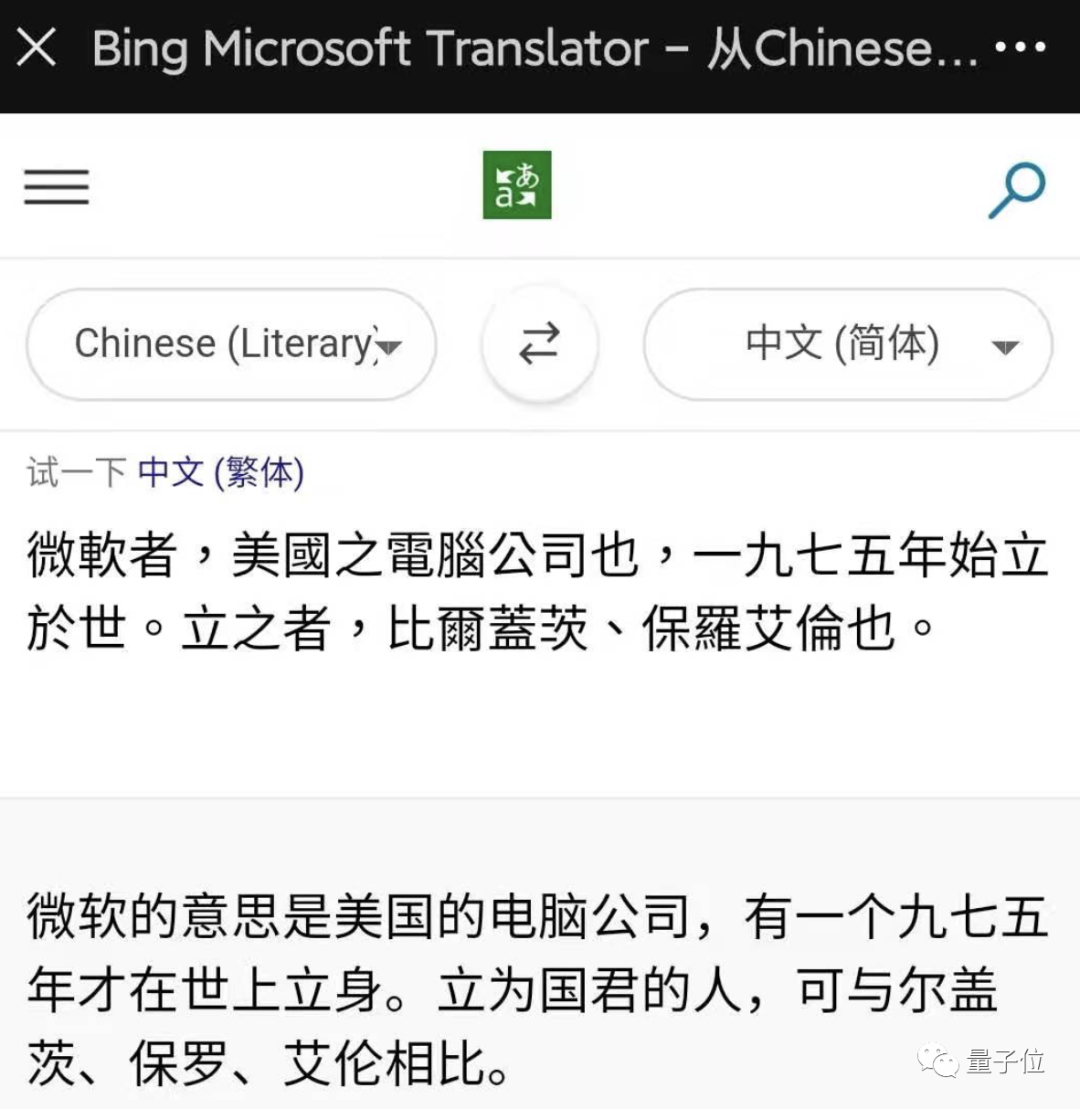
如果百度和微软一起上考场
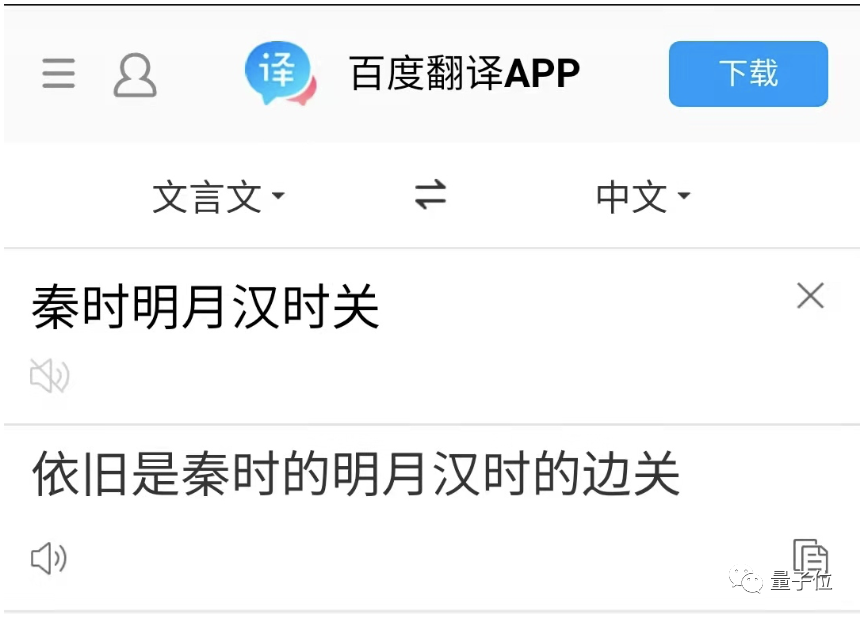
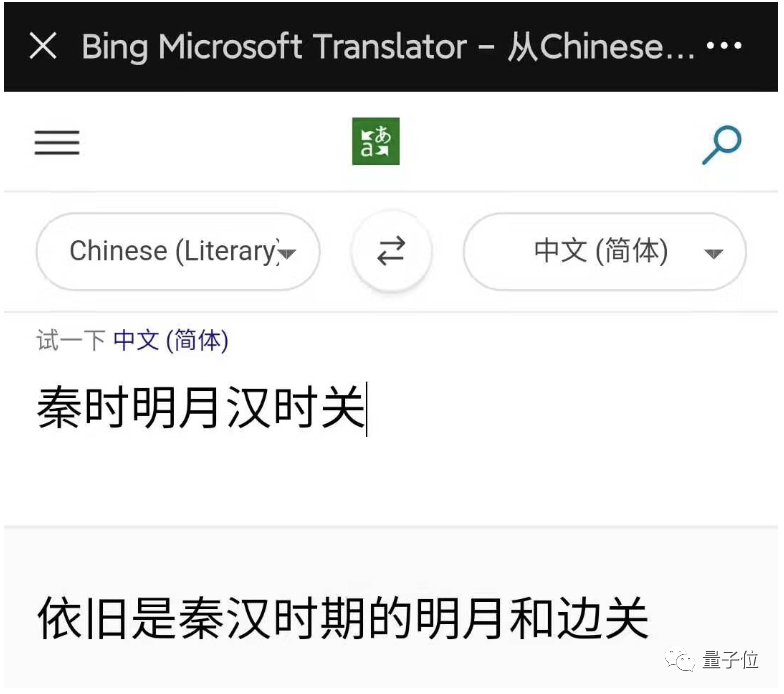
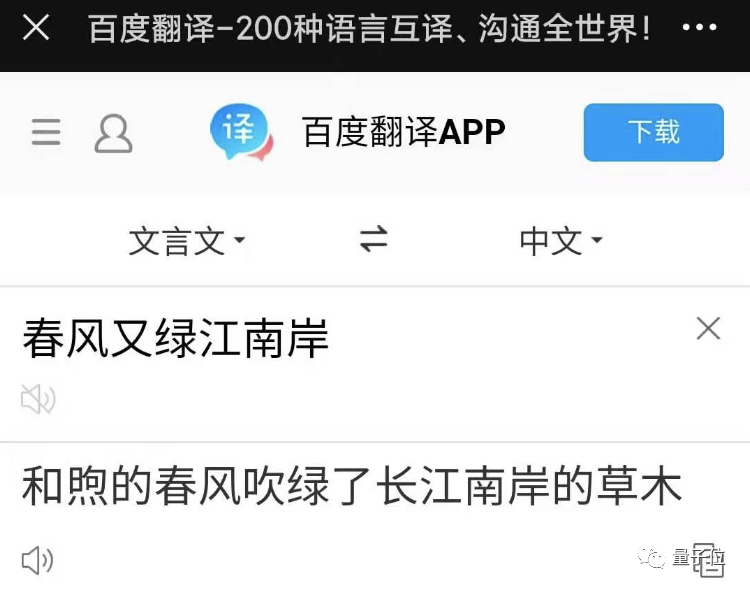
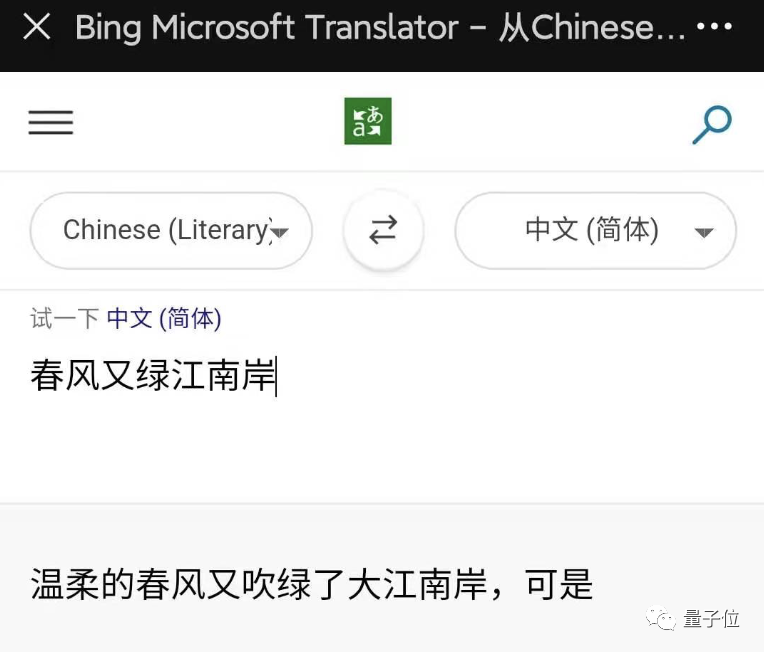
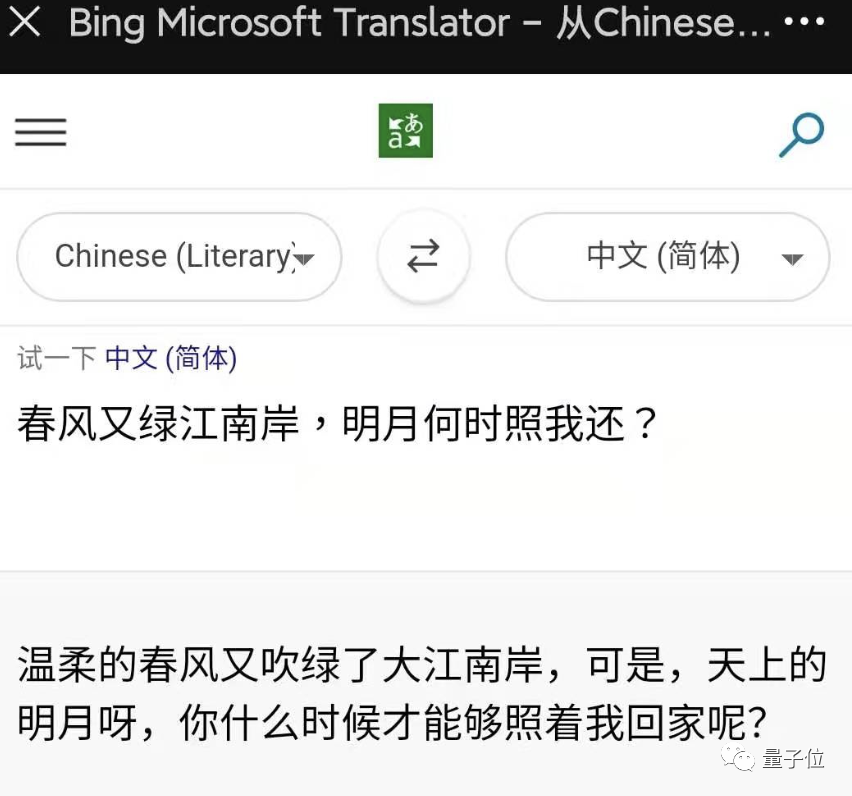

Transformer加成,专攻训练数据
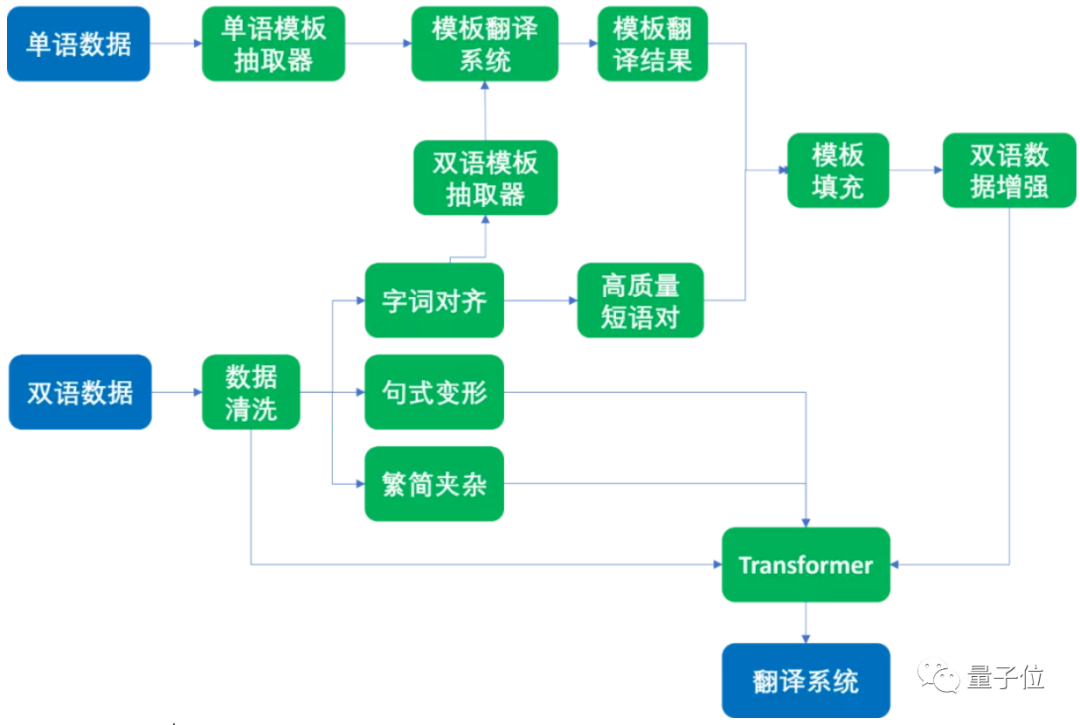
图源:微软研究院AI头条
-
其一,针对 数据量不足 ,利用相同字词进行数据合成和增强。文言文和现代文有一些相同含义的字词,如果对这些词语进行召回、对齐,再扩展到短词短句,就能合成大量可用的训练数据。 -
其二,针对 句式变换不灵活 ,对数据格式进行变形,提升鲁棒性。文言文断句和现代文不太一样,为此研究人员通过数据格式变形,来扩大训练数据量,让模型也学会翻译类似语句。 -
其三,针对 字体识别不力 ,用简繁混合数据训练,提升模型识别能力。为了让机器学习能同时识别简繁混合的文言文,研究人员在训练模型时会将简体中文和繁体中文数据混合在一起进行训练,确保翻译模型不出错。 -
其四,针对 现代文的“新词” ,专门建立相关数据集和识别模型,确保不“乱翻译”。为了避免模型在遇到现代文中的“高铁、电脑、互联网”这种词时出现混乱(例如将高铁翻译成高处的铁块),研究人员建了一个模型,专门用来识别这些新词。除了新词,也针对博客、论坛、微博等新文体进行训练。
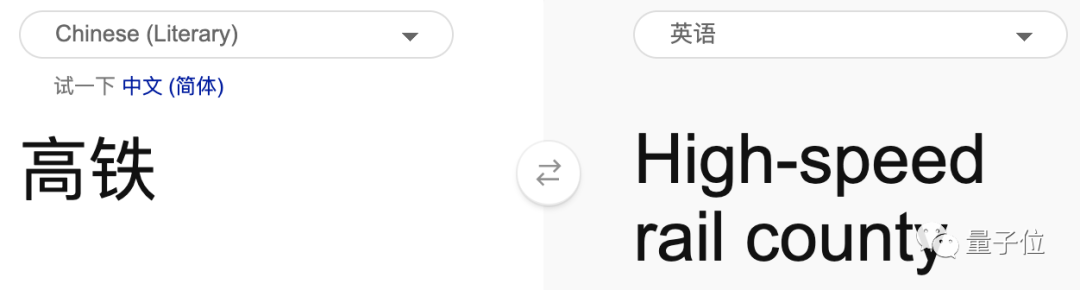
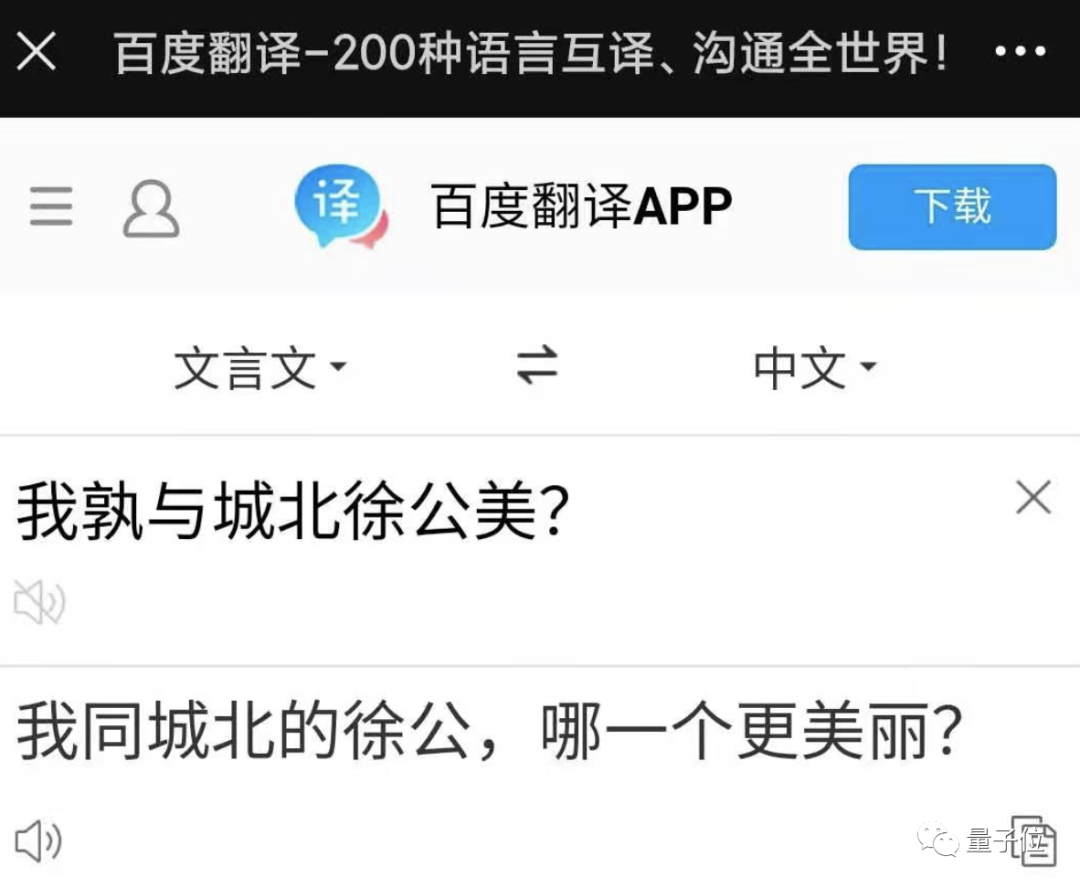
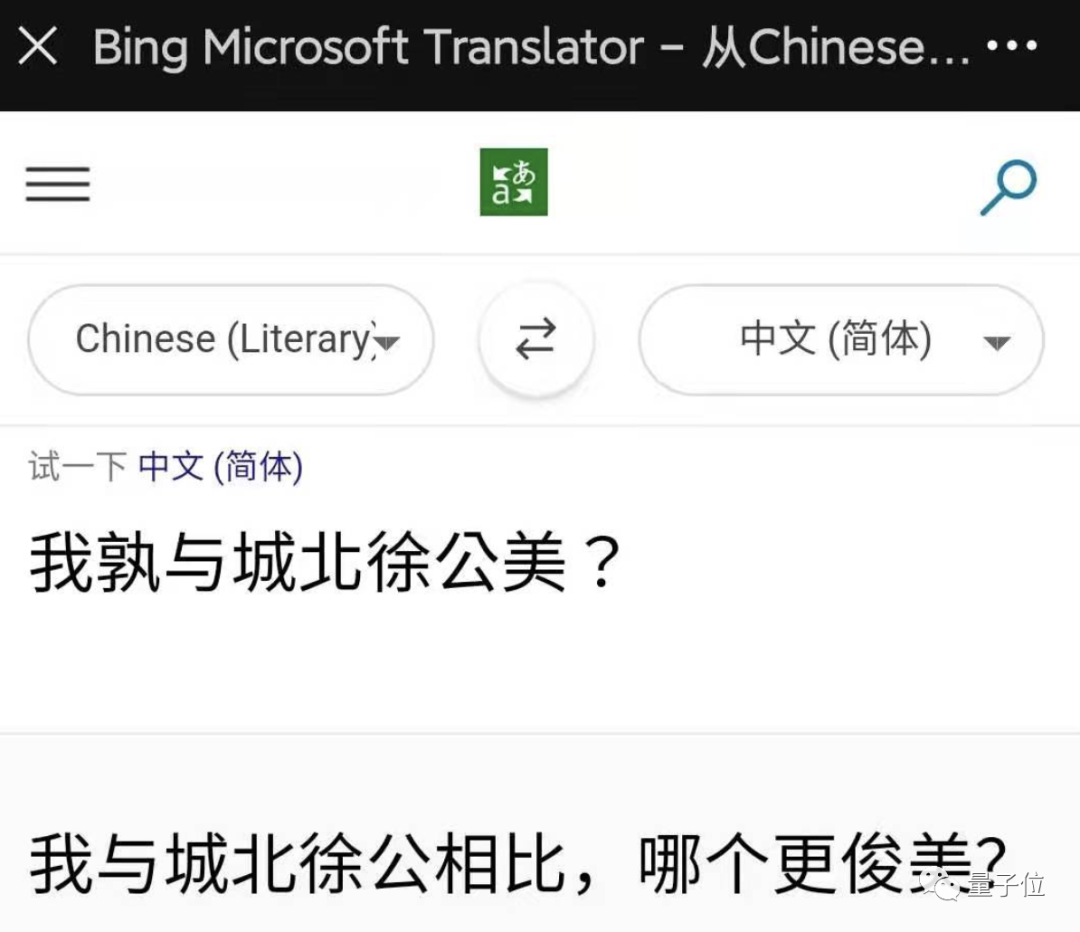
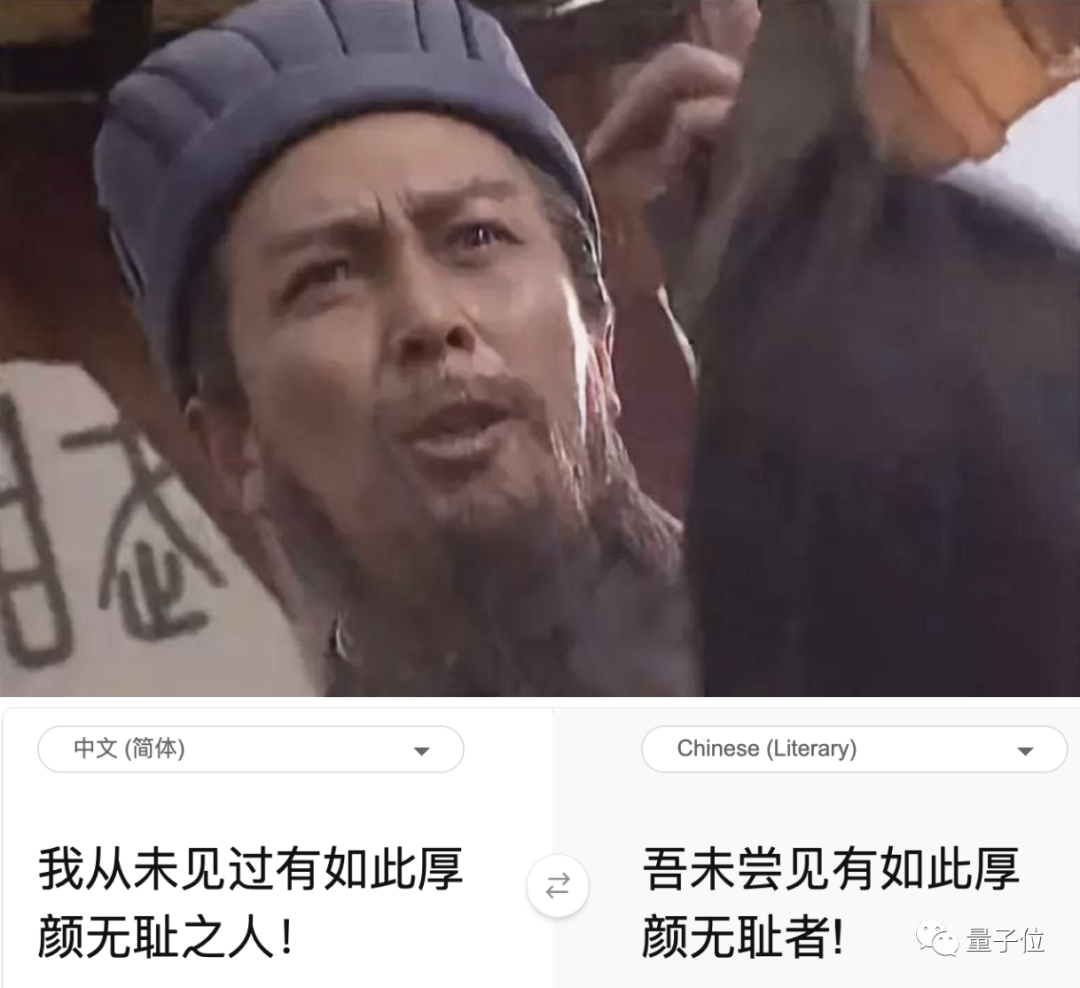
英译中,bug藏不住了
Never gonna give you up





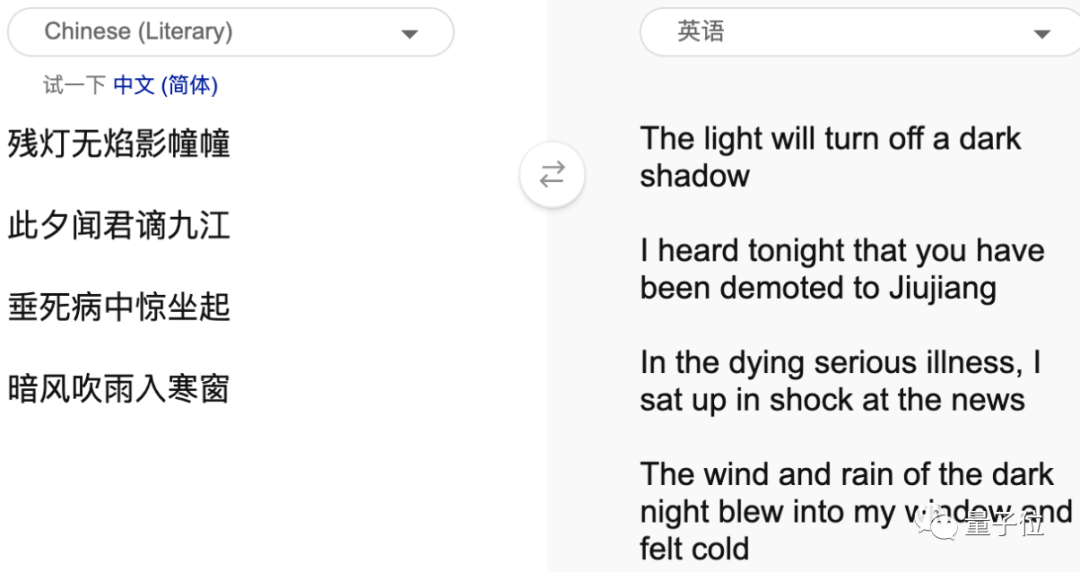

微软文言文翻译地址:
https://cn.bing.com/translator
参考链接:
[1]https://weibo.com/msra?profile_ftype=1&is_all=1#1630370728811
[2]https://mp.weixin.qq.com/s/5cpBuUXfeb0r13JSyNuS_Q

登录查看更多
相关内容

专知会员服务
37+阅读 · 2020年4月10日
Arxiv
0+阅读 · 2022年4月15日
Arxiv
17+阅读 · 2021年6月18日





相关VIP内容
专知会员服务
37+阅读 · 2020年4月10日
相关资讯