乔宇:深度模型让机器理解场景|VALSE2017之十一
点击上方“深度学习大讲堂”可订阅哦!
编者按:所谓场景,无论是“万家灯火”亦或是“巴山夜雨”,于人是一种直观自然的感受;然而,对于机器而言,再多的温情脉脉,都也只是计算机世界冰冷的二进制符号。这区别的背后,其实是人在成长过程中形成的对世界的认知与理解。因此,让机器学会去准确地理解场景、理解世界,是视觉智能的一个重要标志。在本文中,来自中科院的乔宇研究员,将为大家介绍面向大规模场景分类的深度学习模型,通过三部分详尽的工作介绍,为我们揭开场景分类问题神秘的面纱。大讲堂在文末特别提供文中提及所有文章和代码的下载链接。

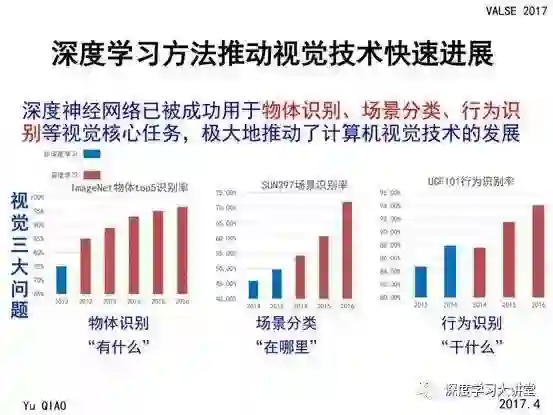
计算机视觉领域有几个基本问题:
图像中有什么,即物体的识别和检测;
图像是在哪里拍摄的,即环境的识别,通常将其定义为场景分类问题,这也是今天要讲的主题;
在图像或者视频中发生着什么样的行为和事件,即行为识别问题。
为什么用深度学习方法?
在过去的五年时间中,深度学习方法极大地推动了计算机视觉技术的发展。在这里我列出了物体识别、场景分类和行为识别领域三个广泛使用数据集的效果,其中蓝色的柱状图表示非深度学习方法的结果,红色的柱状图表示深度学习方法的结果,可以看到在这三个问题中深度学习方法都取得了比传统方法更好的结果。
另一方面,随着深度学习自身的发展,其在各个问题上的性能也有非常快速的增长。这也是为什么在深度学习领域会吸引很多工业界的人士参与,因为当我们的技术好到一定程度时,可以在工业界进行大规模的应用,可以很好地解决实际的问题。
其中最有名的一个例子就是 ImageNet 竞赛,其包含100多万张图片共1000个类别。这个竞赛是由李飞飞在2010年开启的,可以看到在2010年和2011年的 top-5错误率还是相当高的。到了2012年,Hinton 的研究组第一次使用深度卷积神经网络来解决这一问题,将 top-5错误率降低到十几个百分点,之后每年也会有明显的降低,到2015年其 top-5错误率已经达到了3.5%,甚至超越了人类的识别能力。

场景识别
图像识别和理解的另一个问题就是场景识别。场景识别和物体识别的确具有很大的相关性,场景中包含的物体对于场景的类别具有很大的影响;但是场景的类别不仅仅取决于物体,它实际上是由各个语义区域及其层级结构和空间布局决定的。所以场景识别与物体识别既有相关性又有不同点,之后我会讲到如何利用这些不同点针对场景识别的特点来设计新的深度模型以提高其识别率。
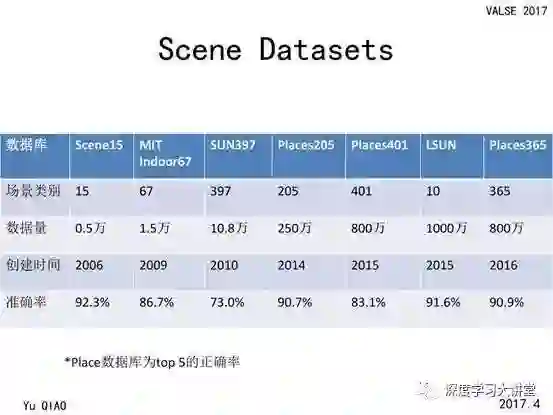
场景识别领域的数据集一览
很多计算机视觉的问题都是与数据集紧密联系的,在过去的十年中场景领域出现了很多数据集,这里我列出了较为有名的一些数据集。
较早的是2006年的 Scene15,只有几千张图片和15个类别,之后其被扩展为 MIT Indoor 和 MIT Outdoor 这两个数据集。随着时间的发展,新的数据集也变得越来越完善,数据量可以达到千万的级别。可以看到各个大数据集的识别率还不是很高,与物体识别如ImageNet的识别率相比还存在着比较大的差距。从这个意义上讲,场景识别要比物体识别更难,其识别率还有很大的提升空间。

Place2 Scene Dataset
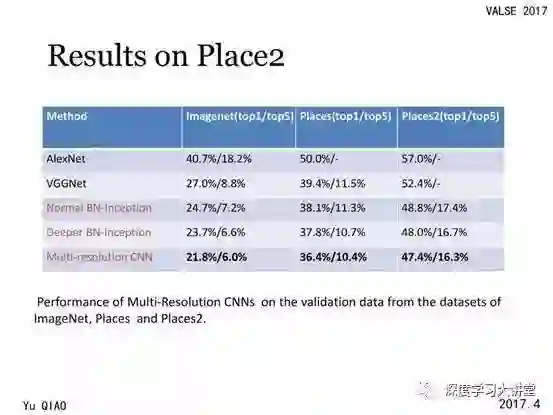
现在用的比较多的场景识别数据集是 Place,由麻省理工学院的研究组创立,并且在2015年和2016年都举行了相应的竞赛,我们团队也参加这些竞赛,并取得了较好的名次。这个数据库含有365个类别,但是每个类别具有的图片数目相差很大,共800多万张训练图片和30多万张测试图片,其数据规模是大于 ImageNet 数据集的。根据对这个数据集训练得到的模型,我们发现其与 ImageNet 数据集具有很大的差异,同时也具有很强的互补性。


场景识别的难点
场景识别的难点在于类内的差异性和类间的相似性。比如图中的“厨房”这个场景就具有很多不同的表现形式,同一个场景中出现的物体会非常多样,这就是类内的差异性。还有一些非常相似的来自不同类别的场景,比如图中的“cubicle office”和”office cubicles“却几乎无法分辨,这就是类间的相似性。
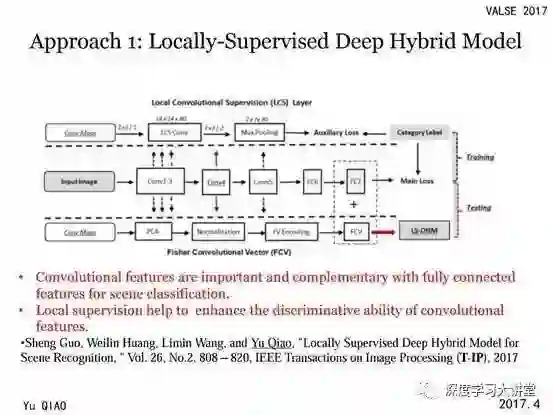
第一部分工作:更好地利用卷积层特征
我们用深度学习方法在场景识别这个任务上做了一些工作,下面分别介绍。我们发现对于场景分类这个任务而言其卷积层特征提供了很多有用的信息,这些卷积层特征可以看作是很多语义区域的检测器,提供了很丰富的图像信息,而且其空间布局也非常有用。
在我们使用全连接层对其进行处理时这些信息会丢失,因为卷积层特征的维度比全连接层的维度高很多。我们希望能更好的使用这些卷积层信息,所以设计了一种卷积特征编码的方法,并将其与全连接特征进行组合,这样组合得到的结果在几乎所有的数据集上都能提升识别性能。
既然卷积层特征很有用,那么我们是否能进一步增强卷积特征呢?在卷积神经网络的训练中,这些特征与监督loss函数比较远,在进行反向传播时需要经过很多层才能将梯度传播到这些卷积层中。这有可能会影响卷积特征的判别能力。为解决这些问题,我们设计了特殊结构使得监督信息能够更为直接作用于卷积层,这样可以进一步提高场景识别的准确率。这是我们在 TIP2017上的一个工作。
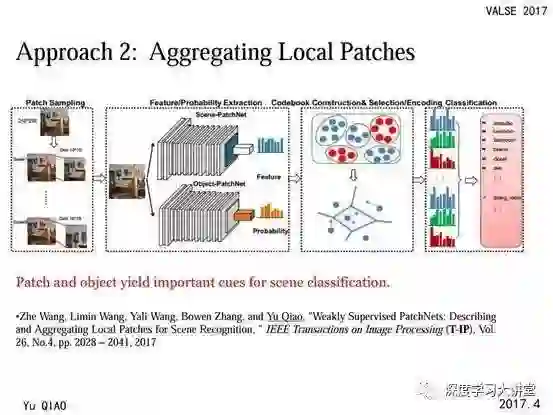
第二部分工作:使用一个卷积网络直接对图像块处理
每个卷积特征都会有一定的感受野对应原图中的一个图像块,那么既然卷积特征有用,我们能不能直接使用这些图像块来训练网络呢?
这就启发我们做了第二个工作。我们使用一个卷积网络直接对图像块进行处理,这里一个问题是如何给定图像块的标签。因为场景的类别更加抽象,如果直接赋予图像块相同的标签是不合理的。
所以我们使用了一些折中的方法:
一方面,使用 ImageNet dataset 预训练的网络来在图像块上进行训练;
另一方面,把场景类别和物体类别使用弱监督方法进行训练。
最后,再将这些图像块得到的特征编码后进行组合得到最终的特征。

第三部分工作:改进监督信息
我们的第三个工作是对监督信息进行改进。我们发现相同的场景之间的差别非常大,而不同的场景之间也会具有很大的相似性,这些会对深度网络的监督学习产生干扰。但是对于人来说识别场景非常简单,这是因为人具有很多先验知识,这些知识体现在对物体的识别上。受到这种启发,我们将从其他数据集中学习到的知识迁移到场景识别这个任务中,并且得到了很好的实验结果。我们认为对于知识的使用将会对计算机视觉任务产生很有益的影响。
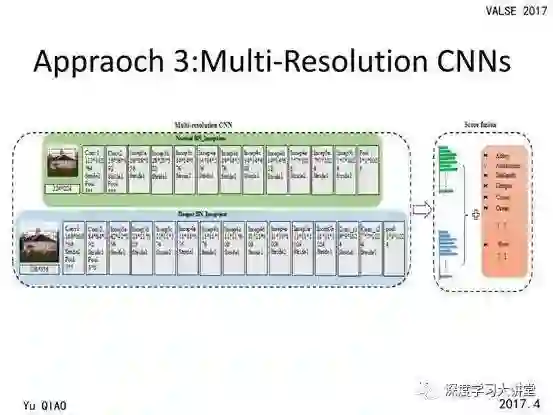

锦囊妙计:图像多尺度变换
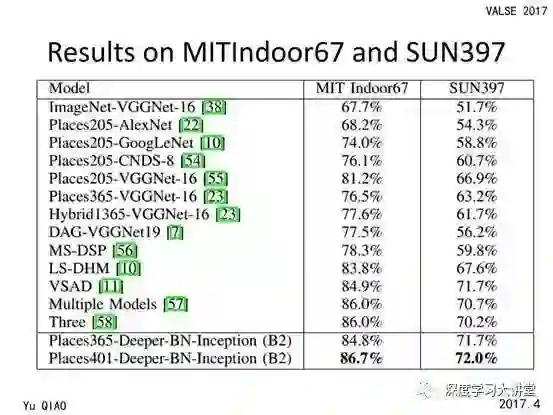
除此之外,我们发现多尺度对于场景识别是很重要的。我们对同一张图像的不同尺寸训练不同的网络,提升图像的多尺度网络之间的互补性,以进一步提高场景识别的准确率。我们在多个数据库上都取得了最好的结果。

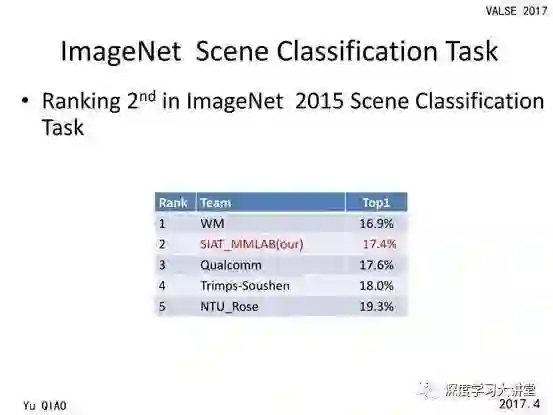
竞赛大舞台
我们参加了很多场景识别领域的国际竞赛,都取得了很好的结果,这也部分验证所提出方法的有效性。

结论
场景分类是一个很具有挑战性的开放性问题,如果单从识别率看,相比物体分类还具有很大的发展空间。如果想要获得更好的性能,场景的全局信息和局部信息都非常重要,如何使用局部的物体语义区域信息和对全局结构进行建模,以及对知识等的运用将是场景识别任务发展的重点。


文中引用文章的下载链接为: http://pan.baidu.com/s/1i5pBxZZ
致谢:

本文主编袁基睿,诚挚感谢志愿者杨茹茵、范琦、李珊如对本文进行了细致的整理工作

该文章属于“深度学习大讲堂”原创,如需要转载,请联系 astaryst。
作者信息:
作者简介:

乔宇,中科院深圳先进技术研究院研究员,集成所所长副所长,博士生导师。入选中国科学院“百人计划”,深圳市“孔雀计划”海外高层次人才,广东省引进创新团队的核心成员。研究兴趣包括计算机视觉、深度学习、机器人等。已在包括IEEE T-PAMI,IJCV,IEEE Trans. on Image Processing,IEEE Trans. on Signal Processing,CVPR,ICCV,ECCV,AAAI等会议和期刊上发表学术论文110余篇。获卢嘉锡人才奖。带领团队多次在ChaLearn,LSun,THUMOUS,ACTIVITYNet等国际评测中取得第一,获ImageNet 2016场景分类任务第二名。主持国家重大研究计划子课题,国家自然科学基金重点、中国科学院国际合作重点,粤港合作,深圳市基金研究“杰青”、日本学术振兴会等资助的多个项目。
VALSE是视觉与学习青年学者研讨会的缩写,该研讨会致力于为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。2017年4月底,VALSE2017在厦门圆满落幕,近期大讲堂将连续推出VALSE2017特刊。VALSE公众号为:VALSE,欢迎关注。

往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站



