【领域报告】图像OCR年度进展|VALSE2018之十一
编者按:
“清风不识字,何事乱翻书。”
早在1929年,德国科学家Tausheck提出了OCR的概念,定义为将印刷体的字符从纸质文档中识别出来。而技术发展至今,识字,已不再仅限于识别书本上的文字,而是要识别真实世界开放场景中的文字。因此,也衍生出了一系列问题,例如真实环境中文字角度不可控、语种复杂多样、环境噪声多变等,针对这些问题,学术界开展了OCR领域研究工作。本文中,来自华中科技大学的白翔教授,将为大家介绍过去一年中,OCR领域的研究进展。
文末,大讲堂提供文中提到参考文献的下载链接。


报告从文本检测,文本识别,端到端识别,还有数据集四个方面展开。
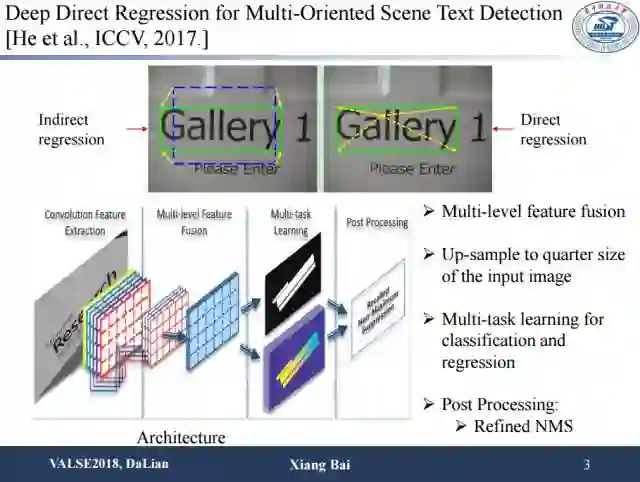
文本检测方面。首先是去年自动化所发表在ICCV的研究成果。之前的回归方法大多为计算给定的default box和待要检测的文本框的offset,而这里采用的是基于一个像素点回归的方法,也就是回归文本框与当前像素点的offset。另一个区别是融合不同层的特征,通过多任务学习进行文本分割以及文本框的回归。整体上,他们的工作在场景文字检测任务上带来了一定性能上的提升。
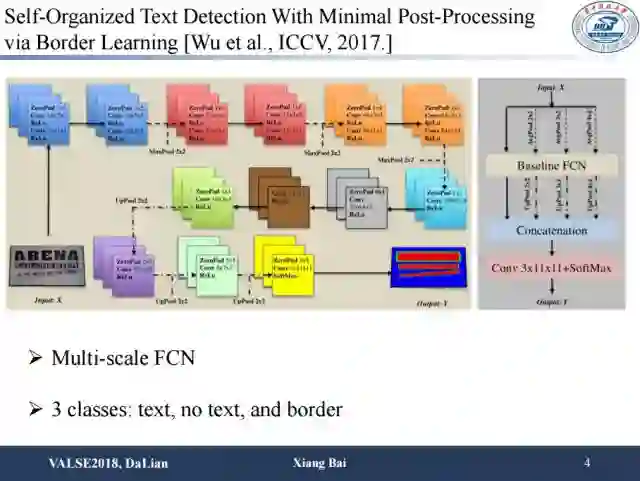
另外一个工作是用全卷积网络将文本区域分成三种类型,第一种类型是文本内部区域,第二种类型是背景区域,第三种类型是文字的边界。这种手段可以较好地应对之前的基于分割的场景文本检测方法难以区分相邻的文本实例的问题,从而带来检测性能的提升。
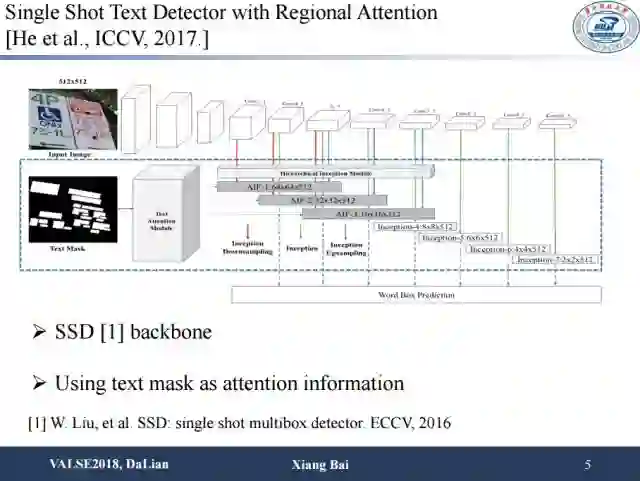
上面这项工作的思路相对比较简单,就是在SSD基础上加了一个模块,这个模块引入了attention的机制即预测text mask,通过文本和非文本的判别让检测更加关注到文本区域上。
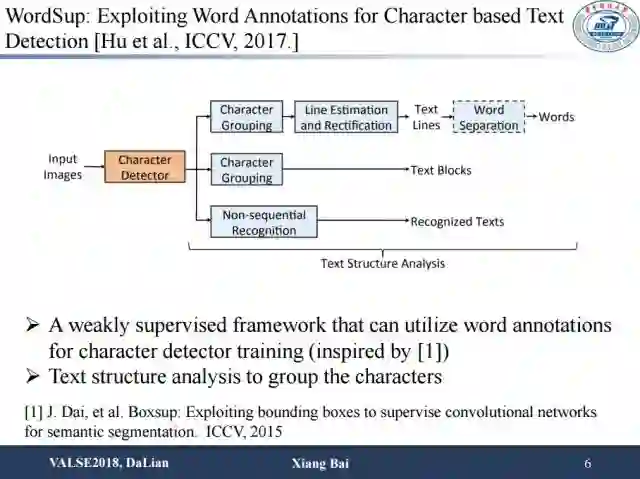
这是百度的工作,做法也比较直接:通过一个弱监督的框架使用单词级别的标注来训练字符检测器,然后通过结构分析将检测到的字符组合成单词。
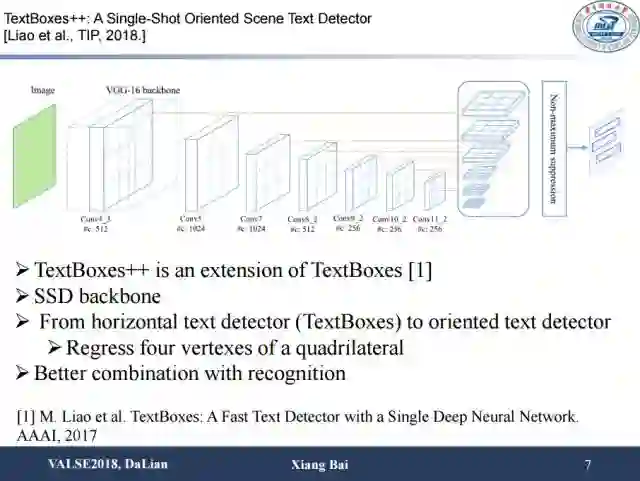
这篇是我们今年发表在TIP上面的一篇工作。其主要改进点为在去年TextBoxes基础上增加了额外的两个分支,其中一个分支被用来回归文字水平包围盒,另外一个分支被用来回归四边形(表示为4个顶点)。此外,我们还用识别信息来过滤检测到的候选框,进一步提升检测结果。
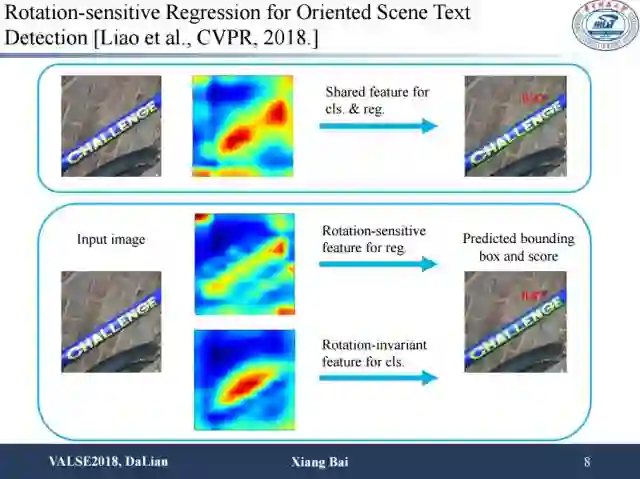
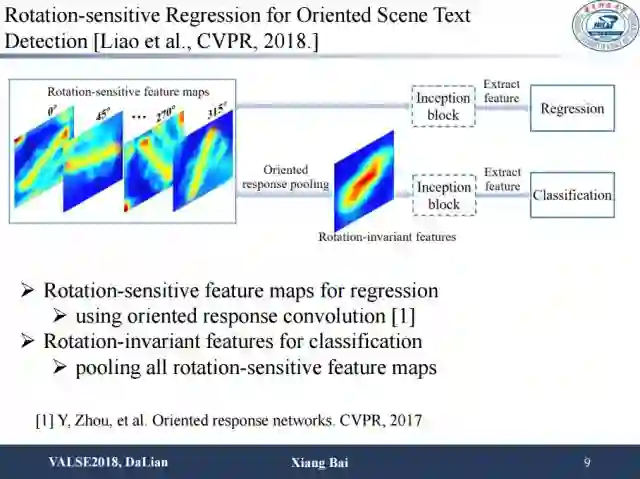
这是我们今年被CVPR接收的一篇文章。其主要思路是:对于文本来说,无论是回归还是分类,特征往往是共享的。然而对于场景文本检测问题来说,特征共享对于这两个任务其实是不利的。首先对于文本与背景的分类问题,一般要求特征具有方向不变性。但是对于回归出文本的包围框这个任务,又要求特征对方向信息是敏感的。因此直接对这两个任务做特征分享可能会带来性能损失。这里我们采用非常简单的方法来解决这个问题,就是在应对回归和分类两个不同任务时,在回归部分跟原来一样,在分类部分中加入oriented response pooling。这个做法可以让分类特征具有旋转不变性,可以更好地关注它是文本还是非文本的问题,方向不带来额外影响。最后对两个任务进行多任务学习,可以提高性能,在应对长文本和方向变化比较剧烈的情况,提升尤为显著。
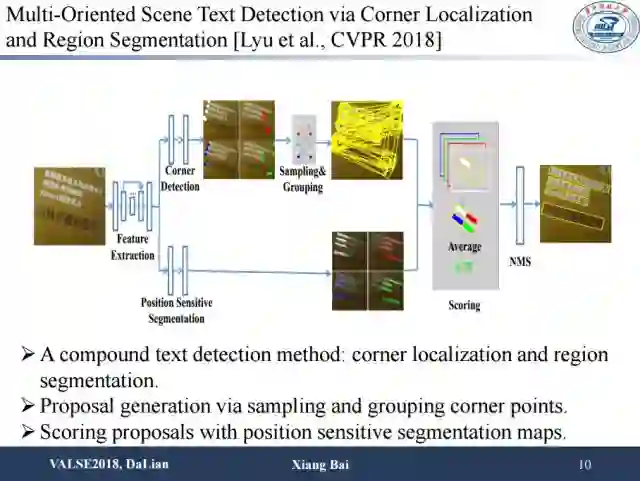
这篇同样是我们今年被CVPR接收的一篇场景文本检测的文章。这项工作主要是为了解决场景文本多方向,长宽比变化较大等场景文本检测中的难点问题。之前的方法大多采用包围盒回归的方法或者文本区域分割的方法去解决上述问题,但是效果并不是特别好。本篇文章用了一个新的思路来解决这个问题,即检测文本区域的角点,然后通过组合角点的方式得到文本框。因此,我们设计了corner detection,思路是直接检测文本区域的四个顶点。由于我们是检测角点,所以首先我们的方法不会受到感受野的影响,其次我们的方法对方向比较鲁棒。此外我们还结合了position sensitive segmentation来提供文本区域的位置信息以及文本的实例信息,并使用segmentation map信息为角点组合成的包围盒进行打分,这比直接计算包围盒得分更加鲁棒。
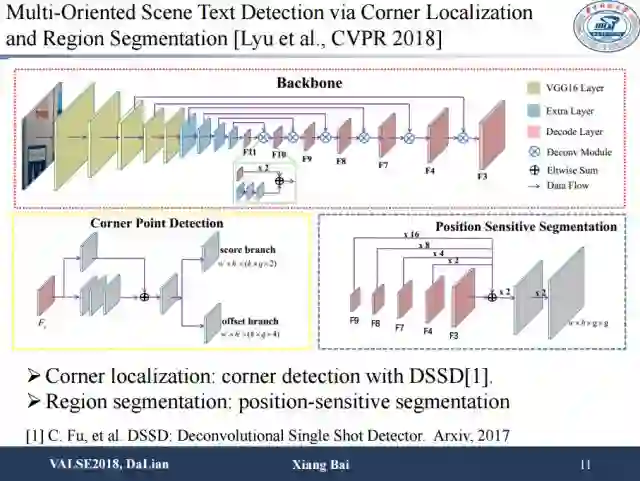
角点检测使用的是基于DSSD的方法,此外我们将角点检测和文本区域的分割在同一个网络框架内实现。
从实验结果中可以看出用了角点以后检测性能提升比较明显。

第二个方面是关于文本识别的进展,进展稍微小一点,因为目前的识别性能已经比较好。
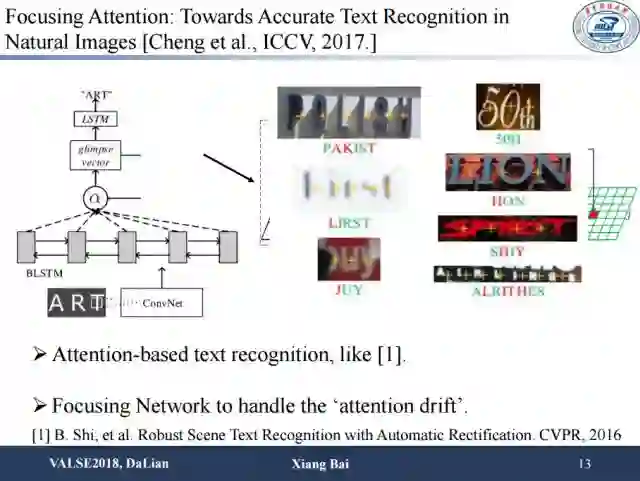
利用attention model去做序列文字识别,可能会因为图像分辨率较低、遮挡、文字间间隔较大等问题而导致attention位置并不是很准,从而造成字符的错误识别。海康威视在ICCV2017上提出使用字符像素级别的监督信息使attention更加准确地聚焦在文字区域,从而使识别变得更精准。他们用了部分像素级别的标注,有了类别信息以后做多任务,结果较为精准。并且只要部分字符的标注就可以带来网络性能的一定提升。
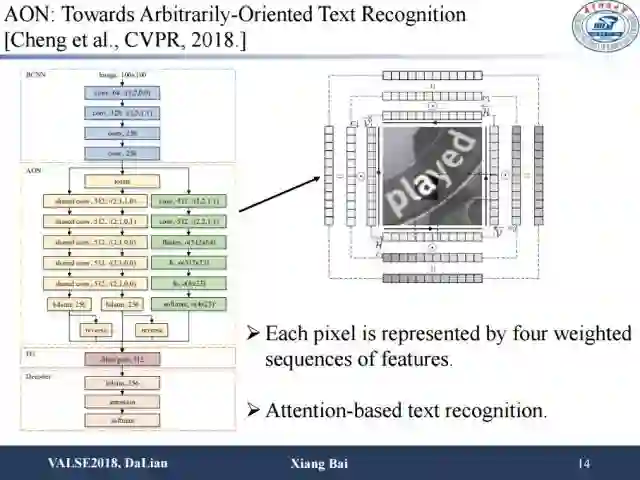
针对有形变或者任意方向文字的识别问题,Cheng等人在CVPR2018上提出了该模型。他们在水平方向之外加了一个竖直方向的双向LSTM,这样的话就有从上到下,从下到上,从左到右,从右到左四个方向序列的特征建模。接下来引入一个权重,该权重用来表示来自不同方向的特征在识别任务中发挥作用的重要性。这对性能有一定提升,尤其是对任意排列的文字识别。

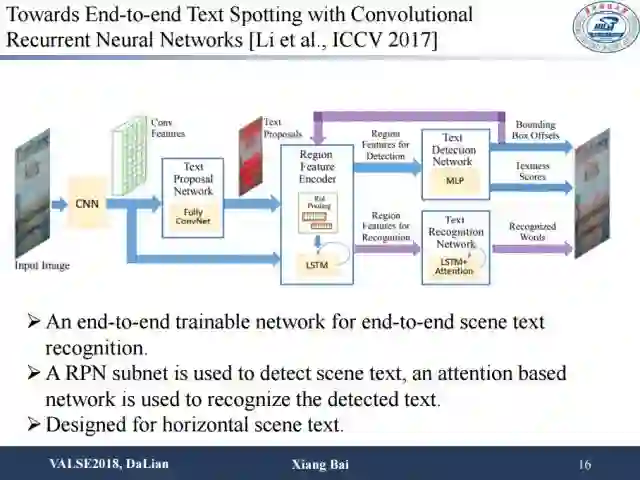
端到端识别从ICCV2017开始出现了将检测和识别统一在一个网络框架下的思路。目前来说这种做法训练起来较为困难。它的主要思路是通过RPN产生一些proposal,然后在后面接上序列识别网络。为了使网络有效,往往需要对检测和识别模块分别进行预训练,预训练完后再把两个模块一起进行进一步训练。这种方法较为复杂。
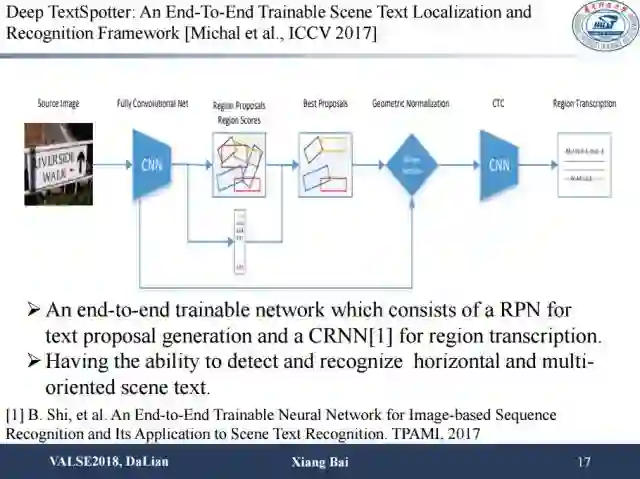
其它方法也采用了大同小异的思路,比如去年ICCV的这篇文章,在RPN的基础上,加入能产生任意方向文字框的proposal,可以做任意方向文字的端到端识别。
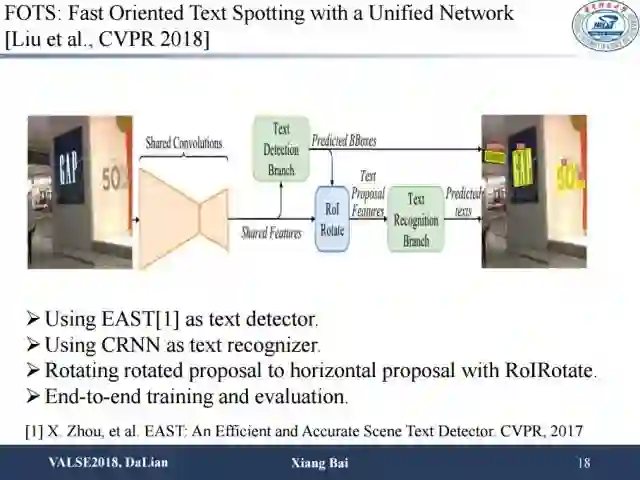
这篇CVPR的工作也是大同小异,使用了更好的检测器EAST,识别部分和训练过程基本和之前端到端的识别工作类似。

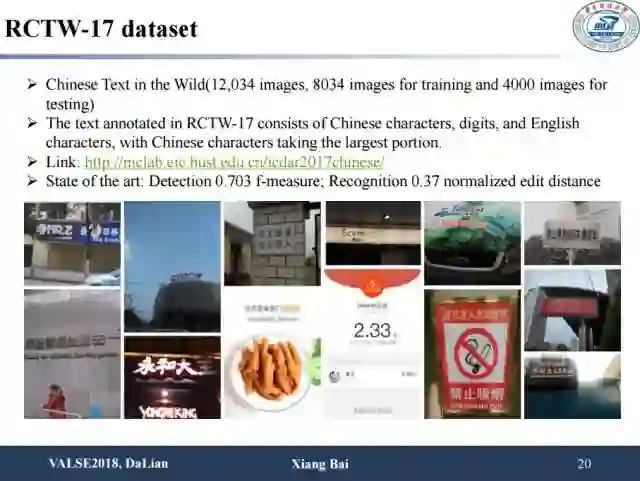

最后我们介绍一些新的数据集。比如说去年icdar比赛中的中文数据集RCTW,以及多语言检测数据集MLT,同时包含了语种识别和检测任务。RCTW数据集主要由场景中文文字构成,总共包含了12,034张图片,其中训练集8034张,测试集4000张。比赛分为文字检测和端到端文字识别两部分。MLT数据集由6个文种共9种语言的文字图片构成,共18,00张图片。该比赛包括了文字检测、语种识别以及文字检测加语种识别三个任务。
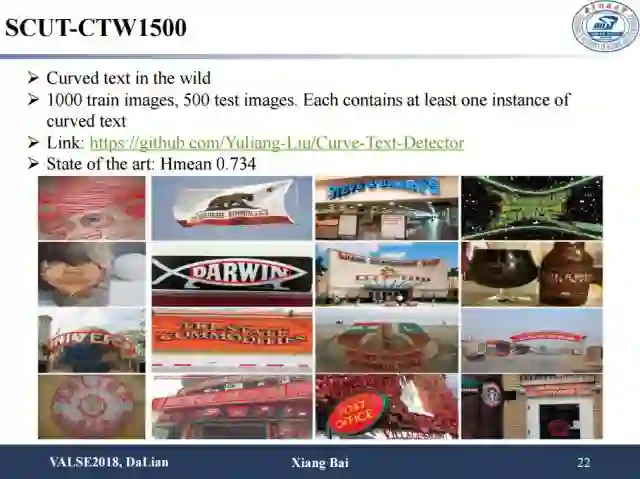
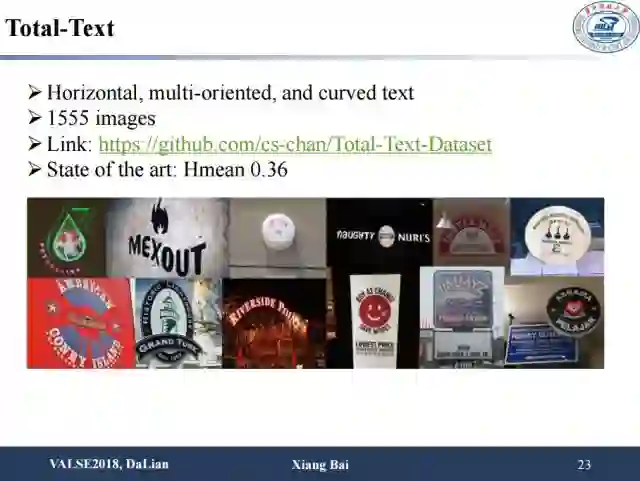
另外是今年华南理工金连文老师提出的比较有意思的数据集,用来探讨异常排列、有形变的文字的检测和识别问题。该数据集共1000张训练图片和500张测试图片,每张图片包含了至少一个曲行文字样本。另外,ICDAR2017上也有一个类似的数据集Total-Text,包括了水平方向、多方向以及曲形文字共1555张图片。
总结一下,通过数据集的演变过程,关于场景文字的研究方法有这样几个趋势:第一,以后检测和识别端到端进行可能是一个趋势,但是未必一定把这两个任务接在一起;第二,处理更难的文字,例如不规则文字,可能也是一个有意思的方向;第三,方法的泛化能力,英文上结果比较好的模型在中文中不一定有效,中英文差别很大,应设计适应多语种的方法来解决这些问题。
参考文献链接:
https://pan.baidu.com/s/10LT47XsUpzBjHu8S9mcy7Q 密码: k2iv

主编:袁基睿,编辑:程一
整理:曲英男、杨茹茵、高科、高黎明
--end--
该文章属于“深度学习大讲堂”原创,如需要转载,请联系 Emily_0167。
作者简介:

白翔,华中科技大学电子信息与通信学院教授,博导,国家防伪工程中心副主任。先后于华中科技大学获得学士、硕士、博士学位。他的主要研究领域为计算机视觉与模式识别、深度学习。尤其在形状的匹配与检索、相似性度量与融合、场景OCR取得了一系列重要研究成果,入选2014-17年Elsevier中国高被引学者。他的研究工作曾获微软学者,国家自然科学基金优秀青年基金的资助。他担任VALSE指导委员,IEEE信号处理协会(SPS)武汉Chapter主席;曾担任VALSE在线委员会(VOOC)主席, VALSE 2016大会主席。
往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站


