看文吃瓜:React遭遇V8性能崩溃的故事

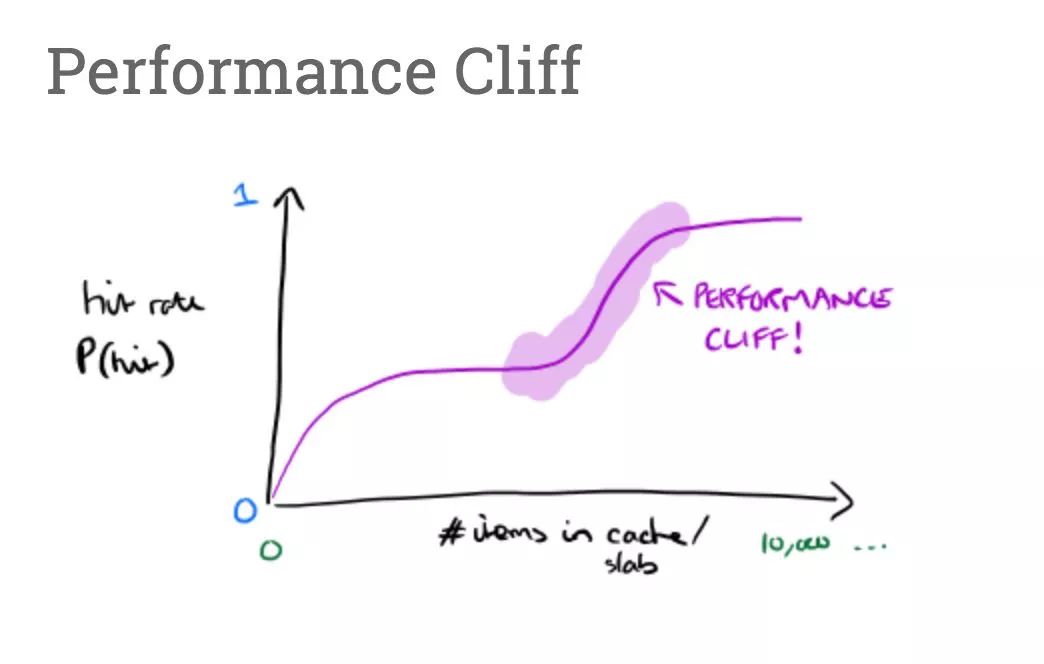
在这之前,我们讨论过 JavaScript 引擎如何通过使用内联缓存 (Inline Caches) 和形状 (Shapes) 优化 object 和数组的访问, 然后我们还特别展开讲解了引擎是如何加快原型属性的访问速度。这篇文章主要讲述 V8 如何选择 JavaScript 值在内存中的表现形式的优化方式, 和这些优化是如何影响 Shape 机制的——这有助于解释近期发生的一个 React core 在 V8 中出现的性能断崖 (performance cliff) 。
每个 JavaScript 值的类型都一定是 8 个不同类型中的一个: Number, String, Symbol, BigInt, Boolean, Undefined, Null, 和 Object。
typeof 42;
// → 'number'
typeof 'foo';
// → 'string'
typeof Symbol('bar');
// → 'symbol'
typeof 42n;
// → 'bigint'
typeof true;
// → 'boolean'
typeof undefined;
// → 'undefined'
typeof null;
// → 'object' 🤔
typeof { x: 42 };
// → 'object'typeof null 返回了'object',并不是 'null', 尽管
Null他自己就是一个类型。为了理解其中的缘由,我们可以先考虑把 Javascript 中的类型分成两组:
-
对象 (i.e. the Object type)。 基本类型 (i.e. 所有非对象的值)。
就此来说,null意味着"不存在的对象"的值, 而undefined代表着"不存在"的值。
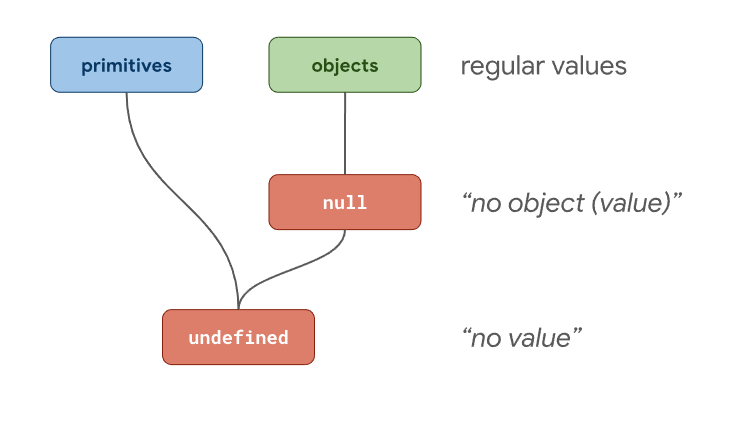
跟着这条思路,Brendan Eich 按照 Java 的精神将 JavaScript 中typeof运算设计为任何值都返回'object',比如所有的对象和null。这就是为何尽管规范中有个单独的Null类型,但是typeof null === 'object'依然成立。

JavaScript 引擎必须能在内存中表达任意的 JavaScript 值。然而,有一点值得注意的地方,那就是 JavaScript 值的类型和值本身在 JavaScript 引擎中是分开表达的。
number类型。
typeof 42;
// → 'number'我们有很多种方法在内存中表达42这个整形数值:

ECMAScript 将number数据标准化位 64 位浮点数,通常叫 双精度浮点数 和 Float64。然而这并不代表 JavaScript 引擎将number类型的数据一直都按照 Float64 的形式存储 -- 这样做的话会非常的低效!引擎可以选择其他的内部表达形式,直到确定需要 Float64 特性的情况出现。
array[0]; // Smallest possible array index.
array[42];
array[2**32-2]; // Greatest possible array index.JavaScript 引擎可以为这类 number 选择一个在内存中最佳的表达方式来优化根据下标访问数组元素操作的性能。对于处理器的访问内存操作来说,数组下标必须是一个能用补码形式表达的数字。用 Float64 的方式来表达数组下标是非常浪费的,因为引擎在每次访问数组元素时不得不在 Float64 和补码之间反复转换。
for (let i = 0; i < 1000; ++i) {
// fast 🚀
}
for (let i = 0.1; i < 1000.1; ++i) {
// slow 🐌
}const remainder = value % divisor;
// Fast 🚀 if `value` and `divisor` are represented as integers,
// slow 🐌 otherwise.如果所有的操作数都是整型,CPU 可以非常高效地计算出结果。当除数为 2 的指数时,V8 还有个额外的优化。如果操作数是浮点类型,这个计算将会复杂很多并且花费更长时间。
// Float64 的安全整型范围为 53 位,
// 超过这个范围你将丢失精度。
2**53 === 2**53+1;
// → true
// Float64 支持表达 -0,所以 -1 * 0 必须等于 -0
// 但在补码形式中 -0 是没办法表达的。
-1*0 === -0;
// → true
// Float64 可以表达因为除 0 而产生的 Infinity。
1/0 === Infinity;
// → true
-1/0 === -Infinity;
// → true
// Float64 还能表达 NaN。
0/0 === NaN;虽然等号左边的值都是整数,但等号右边的全是浮点数。这就是使用 32 位二进制补码无法正确执行上述操作的原因。JavaScript 引擎不得不特殊处理以确保整型计算能适当地回落到复杂的浮点结果。
HeapObject,即一些在内存中的实体的地址。对于 number 来说,我们使用一个特殊的 HeapObject,或者叫
HeapNumber,来表达不在
Smi范围内的
number数据。
-Infinity // HeapNumber
-(2**30)-1 // HeapNumber
-(2**30) // Smi
-42 // Smi
-0 // HeapNumber
0 // Smi
4.2 // HeapNumber
42 // Smi
2**30-1 // Smi
2**30 // HeapNumber
Infinity // HeapNumber
NaN // HeapNumber正如上面例子所展示,一些 JavaScriptnumber被表达为Smi,而其他的表达为HeapNumber。V8 对 Smi 做了特殊的优化,因为在现实的 JavaScript 程序中小整型数据实在是太常用了。Smi不需要在内存中为其分配专门的实体,而且通常可以使用快速的整型运算。
这里最重要的一点是,作为一个优化点,即便是一样的 JavaScript 类型但是在内存中表达形式可以完全不一样。
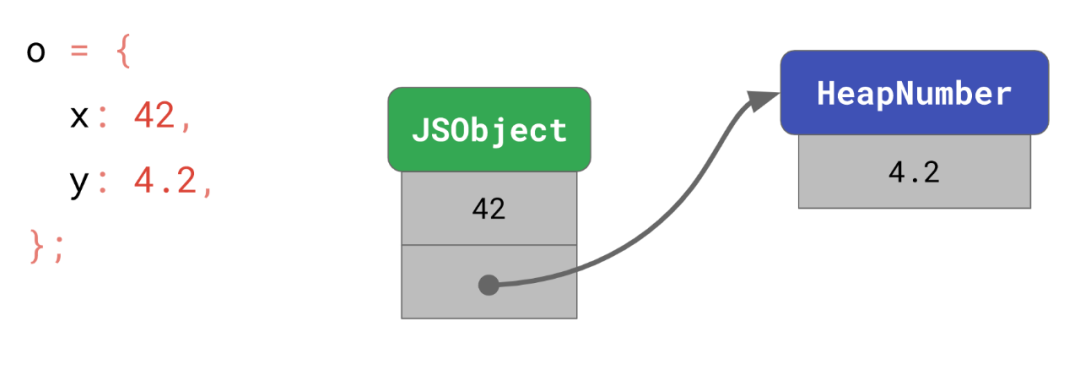
const o = {
x: 42, // Smi
y: 4.2, // HeapNumber
};x 的值 42 可以被编码为 Smi,所以它可以被存储在对象自身中。而y的4.2需要一个分开的实体来保存这个值,然后这个对象指向那个实体。
o.x += 10;
// → o.x is now 52
o.y += 1;
// → o.y is now 5.2在这个例子中,由于新值 52 也是 Smi,所以 x 的值可以直接被替换。
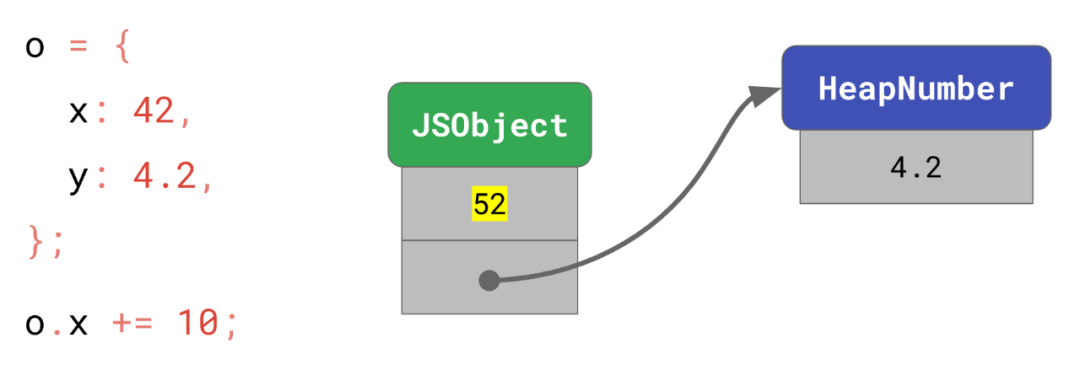
另一方面,y=5.2的新值不属于Smi,而且和之前的4.2也不同,所以 V8 分配了一个新的HeapNumber实体并将地址赋值给y。
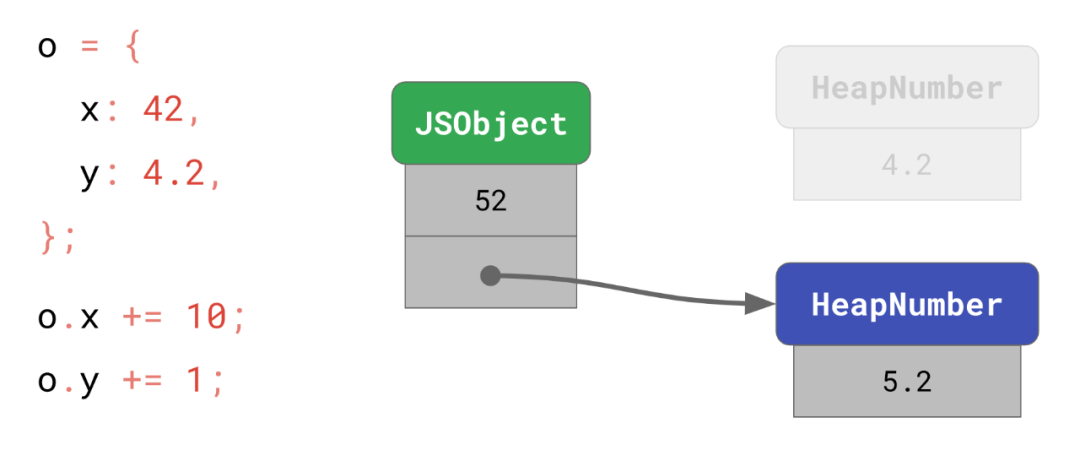
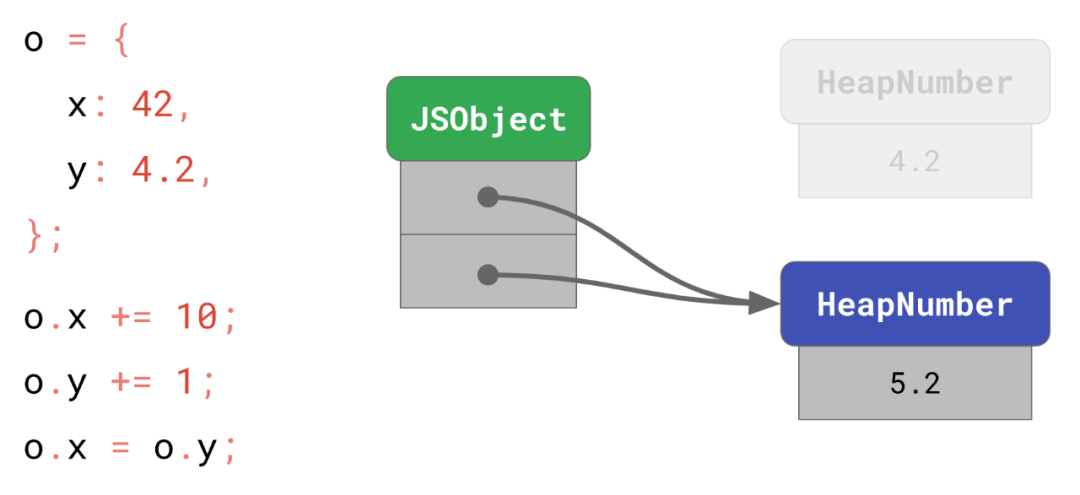
HeapNumber是无法被修改的,因为这样可以进行某些优化。举个例子,如果我们把 y 赋值给 x:
o.x = o.y;
// → o.x is now 5.2那么我们现在只需要指向相同的 HeapNumber 而不必为相同的值分配一个新的对象。
HeapNumber不可变机制不好的一面是频繁修改非
Smi范围内的属性将会变得缓慢。就像下面这个例子:
// Create a `HeapNumber` instance.
const o = { x: 0.1 };
for (let i = 0; i < 5; ++i) {
// Create an additional `HeapNumber` instance.
o.x += 1;
}第一行代码将会创建一个HeapNumber实例并初始化其值为0.1。循环体将其改为1.1,2.1,3.1,4.1直到5.1,总共创建了 6 个HeapNumber实例,其中 5 将会在循环结束后成为内存垃圾。
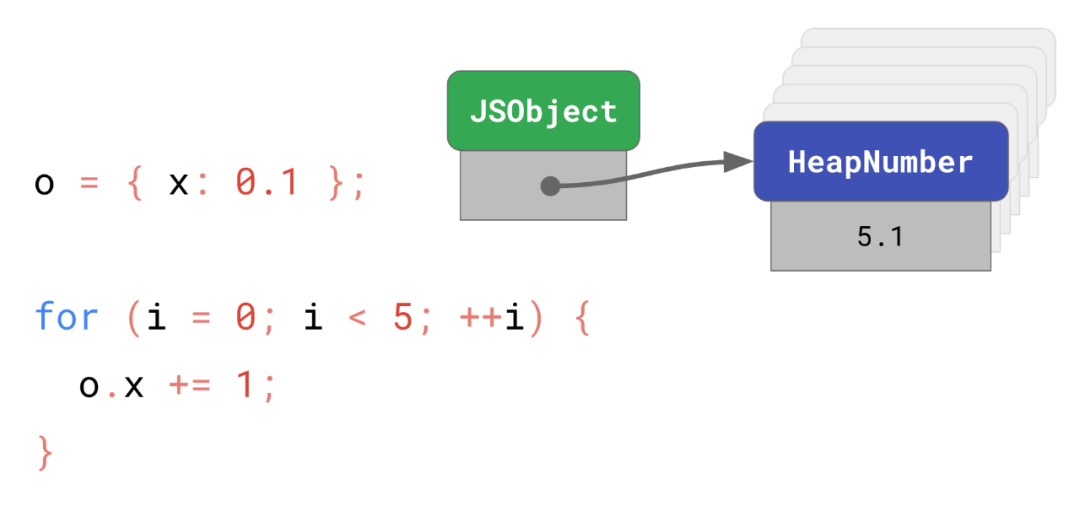
为了避免这个问题,V8 提供了一个优化更新非Smi的 number 字段的方法。当一个 number 字段保存了一个不再 Smi 范围内的值时,V8 在该对象的 shape 中将其标记为Double字段,并且分配一个被称为MutableHeapNumber的对象以 Float64 编码形式保存其值。
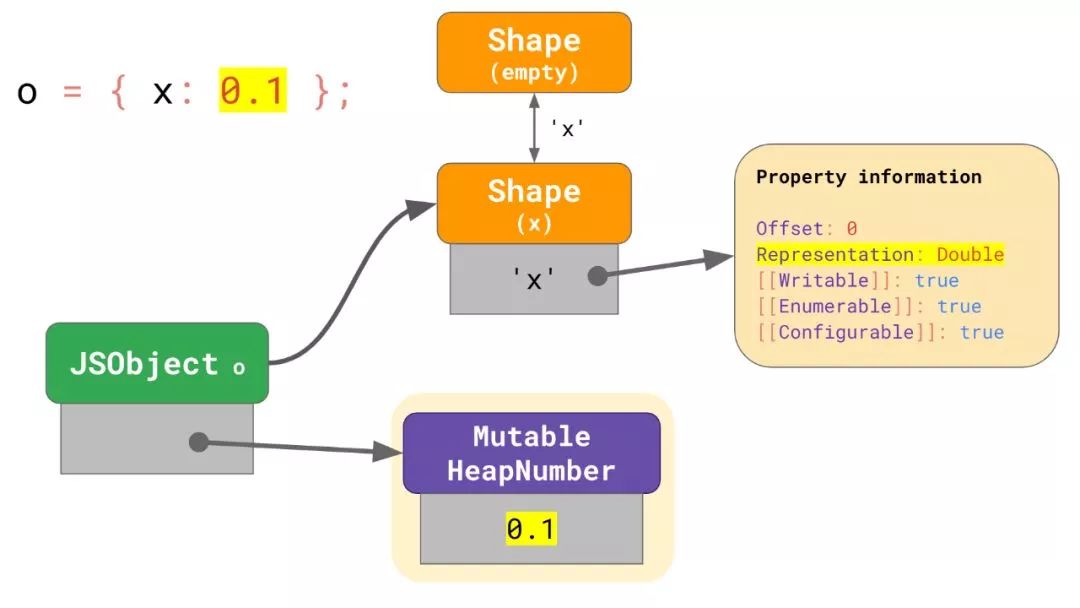
当该字段变化时,V8 不再需要去重新分配一个新的HeapNumber,而是只需要更新MutableHeapNumber中的值即可。
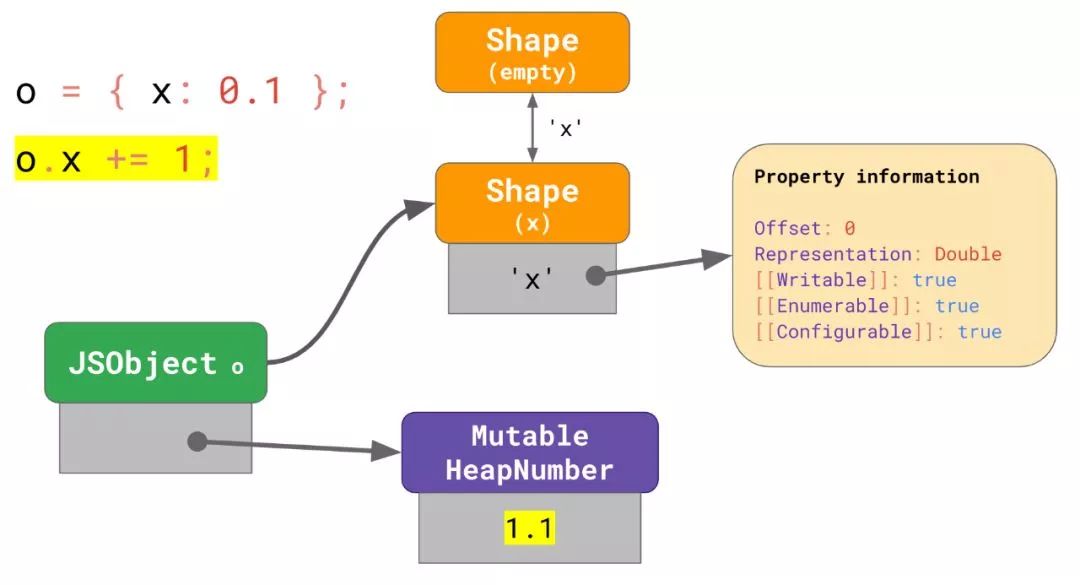
但是,这种方法也有个问题。因为MutableHeapNumber的值可以修改,所以它们不应该被传递出去。
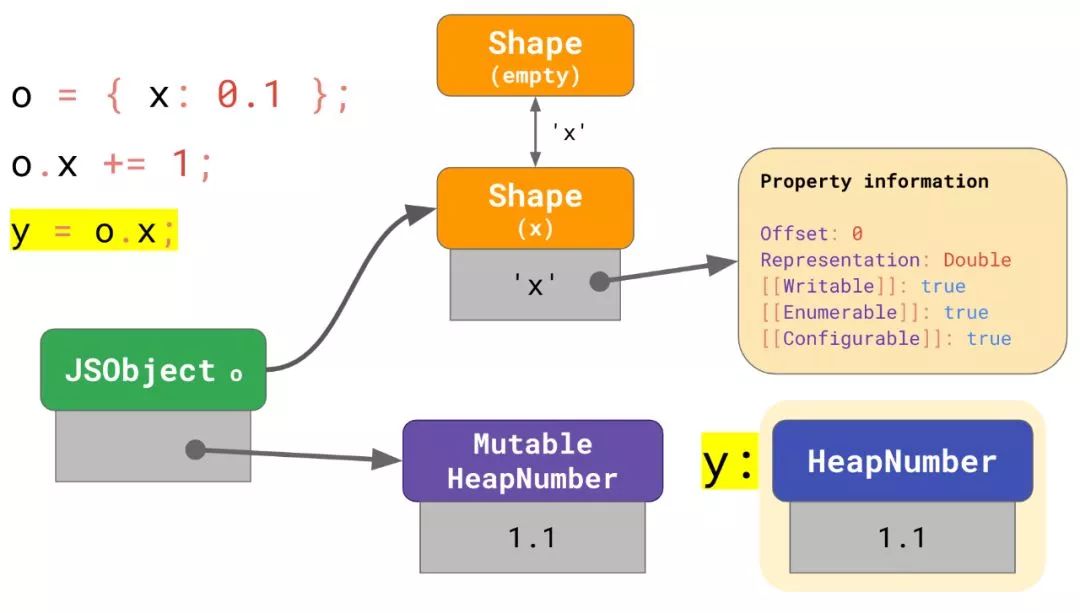
举个例子,如果你将o.x赋值给另外一个变量y,你不会希望y值的改变也带来x.o的改变 -- 这是违反 JavaScript 规范的!所以当o.x被访问时,这个数字必须得重新装箱成一个正常的HeapNumber,然后再赋值给y。
MutableHeapNumber机制是非常浪费的,因此
Smi是一个更加有效的表达方式。
const object = { x: 1 };
// → no “boxing” for `x` in object
object.x += 1;
// → update the value of `x` inside object为了避免低效,我们为了小整型数字所要做的事情就是将 shape 上的字段标记为 Smi 表达,然后只要满足小整型范围的更新就只执行数值替换。
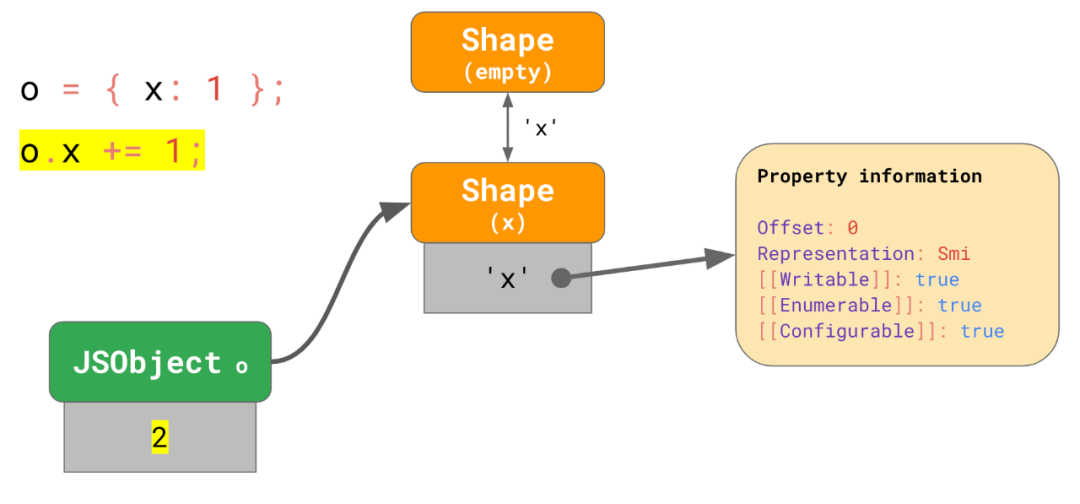
Smi数据,但是后面又被更新成了一个小整数范围之外的数据该怎么办?比如下面这个例子,2 个结构相同的对象,其中
x都为
Smi表达的初始值:
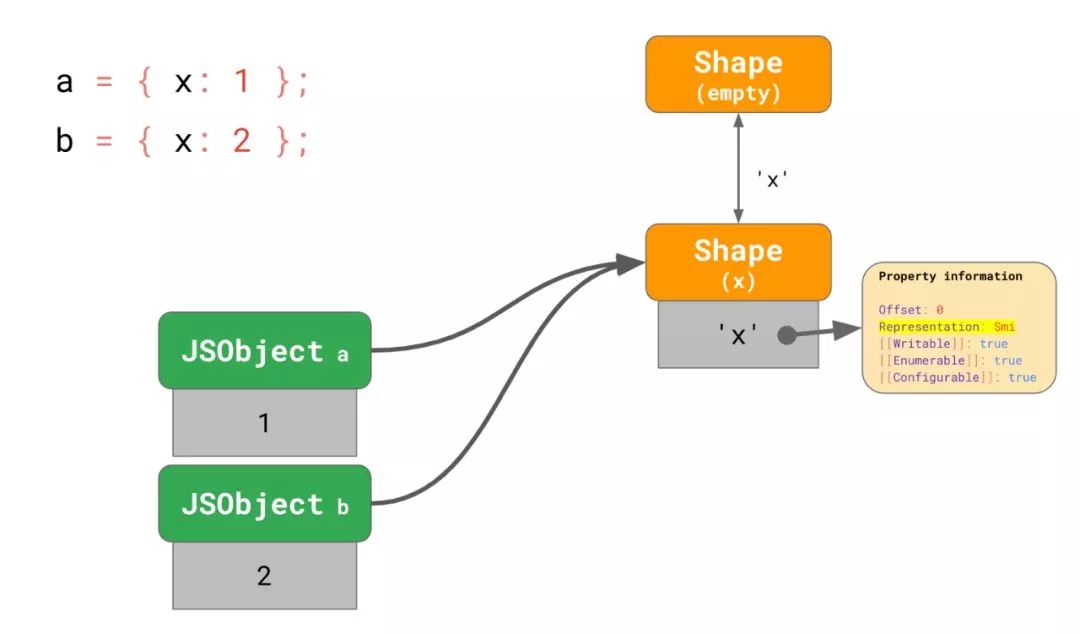
const a = { x: 1 };
const b = { x: 2 };
// → objects have `x` as `Smi` field now
b.x = 0.2;
// → `b.x` is now represented as a `Double`
y = a.x;那么一开始这两个对象都指向同一个 shape,其中x被标记为Smi表达。
当b.x修改为 Double 表达时,V8 分配了一个新的 shape 而且其中的x被指定为 Double 表达,并指向空 shape。V8 也会为属性 x 分配一个MutableHeapNumber来保存这个新的值0.2。然后当再更新对象b指向这个新的 shape,并更改对象中的槽以指向偏移 0 处的先前分配的MutableHeapNumber。最后,我们将旧的 shape 标记为废弃的并且将其从转变树 (transition tree) 中摘除。这是通过'x'从空 shape 到新创建的 shape 的转变 (transition) 来完成的。
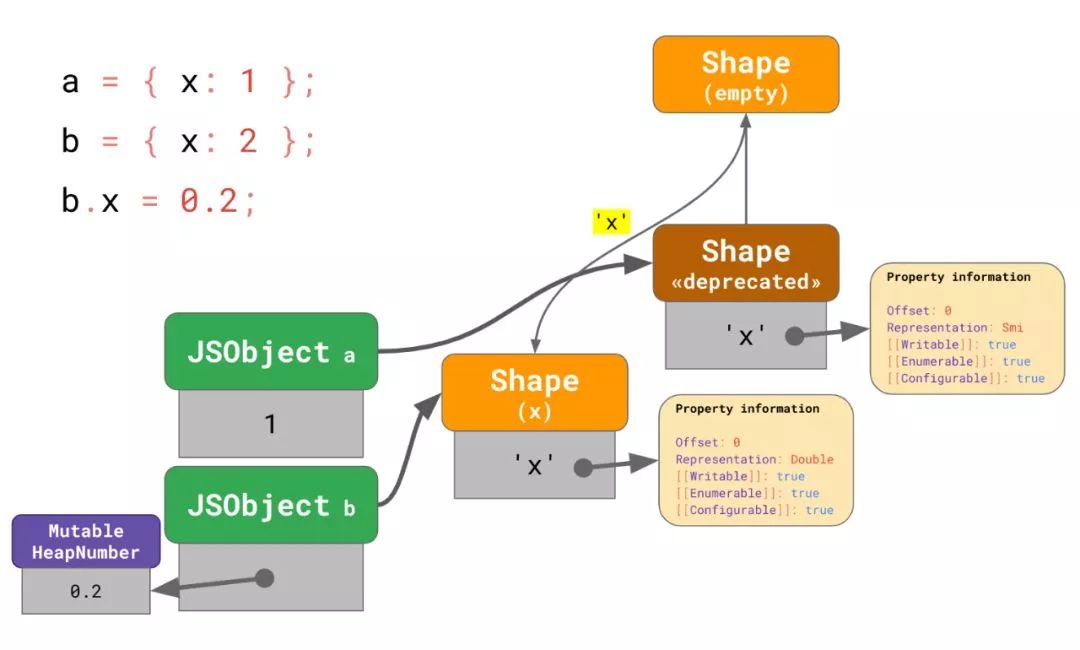
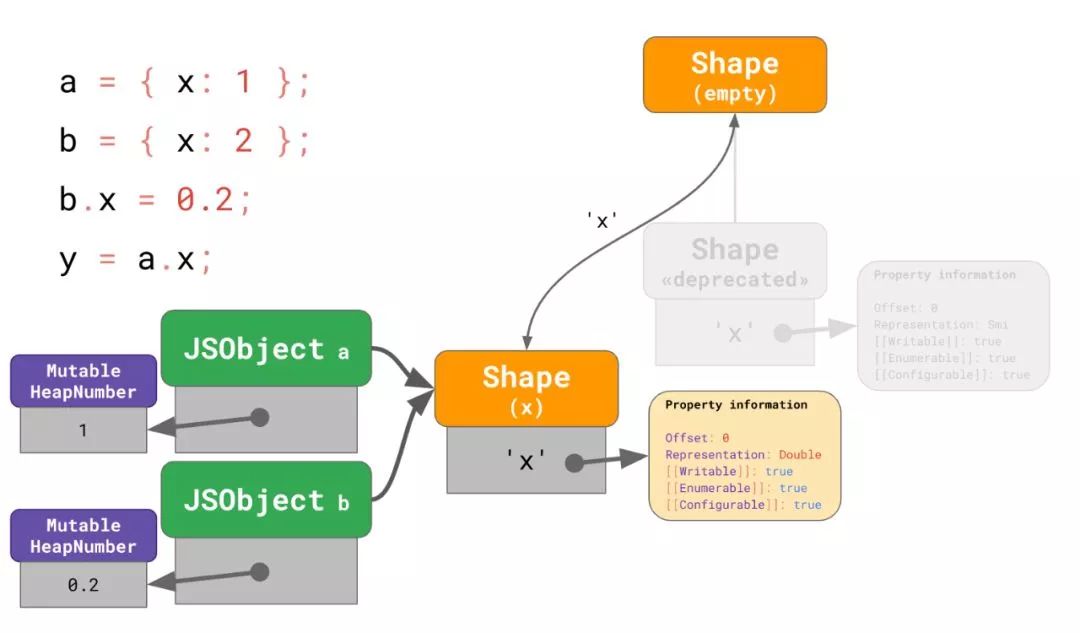
此时我们还不能完全移除旧的 shape,因为它还在被 a 所使用,而且遍历内存去寻找所有指向了旧 shape 的对线并立刻更新他们的将是非常昂贵的。相反,V8 使用了一个偷懒的办法:任何对a的属性访问或者赋值都会先将其迁移到新的 shape 上。这个思路最终将使得废弃的 shape 变得不可抵达然后被垃圾回收器删除。
const o = {
x: 1,
y: 2,
z: 3,
};
o.y = 0.1;在这个例子中,V8 需要去寻找一个被称为 分离 shape(split shape) 的 shape,即指相关属性引入之前链中的最后一个 shape。在这里我们修改了y,所以我们需要找到最后一个没有包含y的 shape,在我们这个例子中就是引入了x的那个 shape。
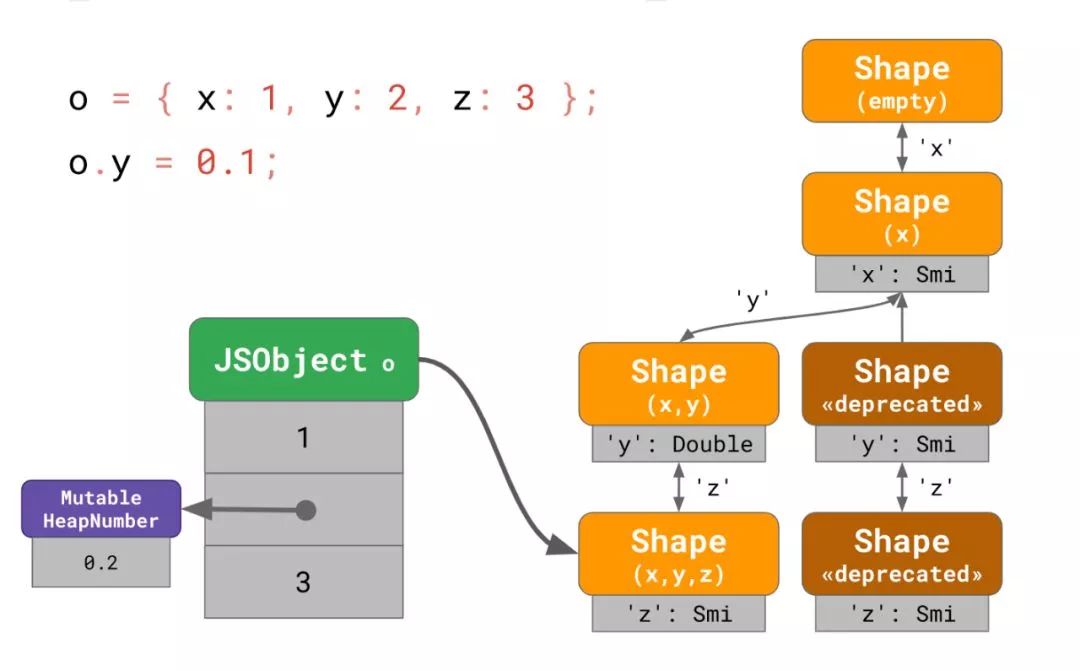
从分离 shape 开始,我们为 y 创建了一个可以重放所有之前的转变的新转变链 (transition chain),但是其中'y'被标记成 Double 表达。然后我们使用这个新的转变链并将旧的子树标记为废弃的。在最后一步我们把实例o迁移到了新的 shape,并使用了MutableHeapNumber来保存 y 的值。这样,新的对象就不会使用老的路径,而且一旦旧 shape 的引用小时,树中废弃的 shape 的那部分就会消失。
const object = { x: 1 };
Object.preventExtensions(object);
object.y = 2;
// TypeError: Cannot add property y;
// object is not extensibleObject.seal和
Object.preventExtensions作用相同,但是它还会将所有属性标记为不可配置,意味着你不能删除它们,或者改变它们的可枚举性,可以配置性或者可写性。
const object = { x: 1 };
Object.seal(object);
object.y = 2;
// TypeError: Cannot add property y;
// object is not extensible
delete object.x;
// TypeError: Cannot delete property xObject.freeze也和
Object.seal作用相同,但是它还会通过将属性标记为不可写来阻止现有属性被修改。
const object = { x: 1 };
Object.freeze(object);
object.y = 2;
// TypeError: Cannot add property y;
// object is not extensible
delete object.x;
// TypeError: Cannot delete property x
object.x = 3;
// TypeError: Cannot assign to read-only property xx,然后我们阻止任何对第二个对象进一步的扩展。
const a = { x: 1 };
const b = { x: 2 };
Object.preventExtensions(b);如我们之前所知,一切从空 shape 转变到一个包含属性'x'(以Smi形式表达) 的新 shape 开始。当我们阻止了对b的扩展,我们对新的 shape 进行了一个特殊的转变 -- 将其标记为不可扩展。这个特殊的转变没有引入任何新的属性 -- 它实际上只是个标记。
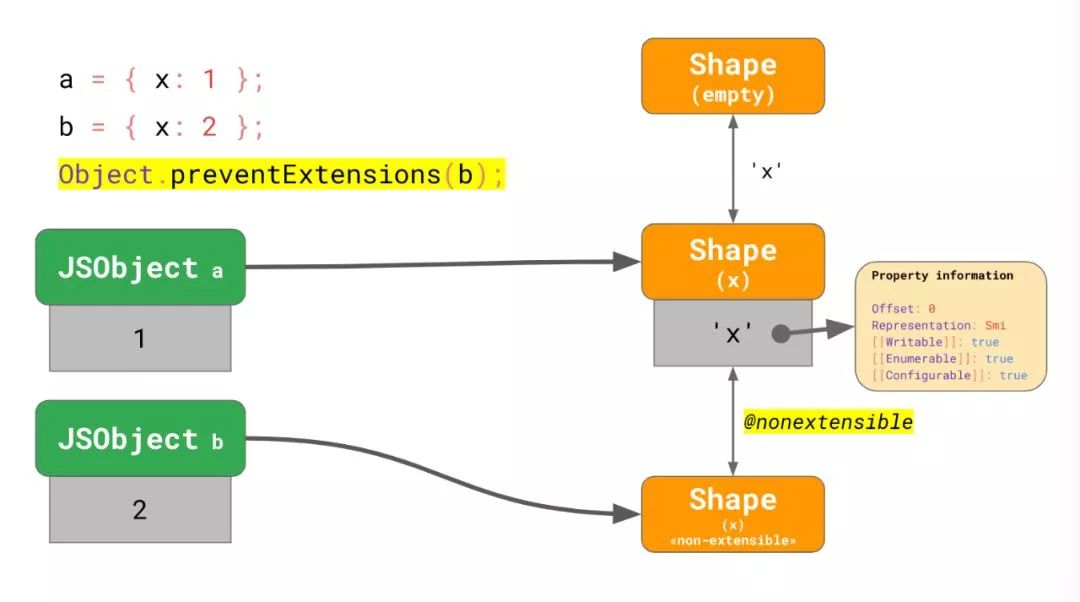
注意我们为何不能直接更新包含 x 的 shape,因为它被另外一个对象 a 所引用,而且依然是可扩展的。
const o = { x: 1, y: 2 };
Object.preventExtensions(o);
o.y = 0.2;我们有个包含了 2 个Smi表达的字段。我们阻止了所有其他对这个对象的扩展,然后最终强制第二个字段变成 Double 表达。
如我们之前所学,它大致创造了以下配置:
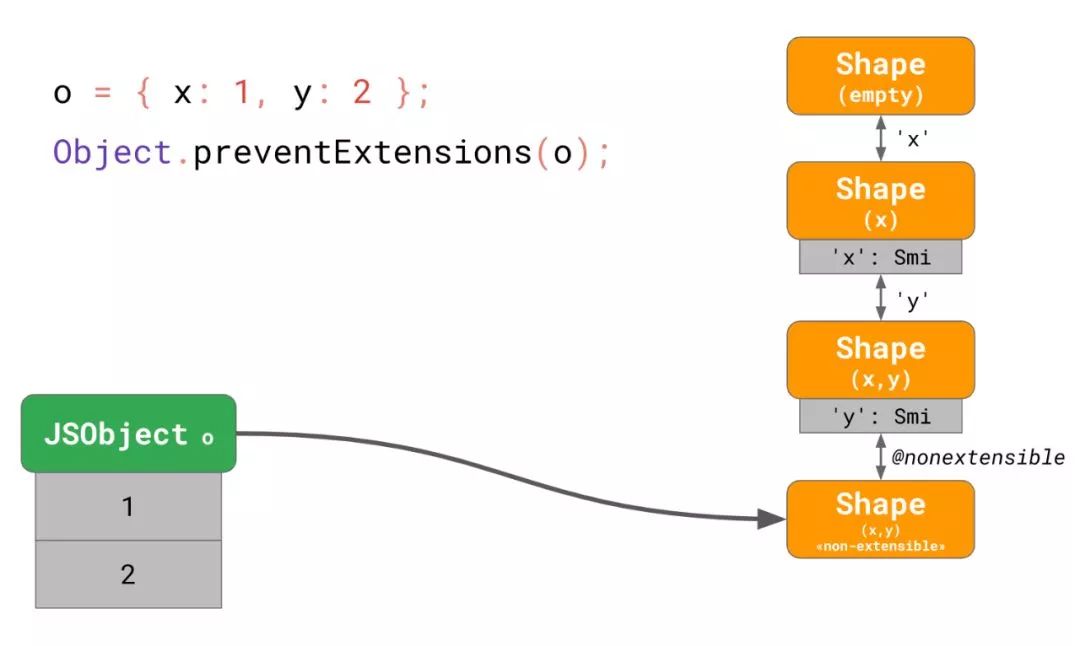
所有属性都被表达为Smi形式,而且最终的转变是将这个属性标记为不可扩展的扩展性转变。
现在我们需要将 y 修改为 Double 表达,意味着我们需要重新开始找到分离 shape。在本例中,这是引入了x的那个 shape。但是现在 V8 有点困惑,因为分离 shape 是可扩展的但当前 shape 是被标记成了不可扩展的,而且 V8 不能确切地知道如何正确地重放转变。所以 V8 实际上直接放弃理解这件事,与此相反地创建了一个和现有的 shape 树没有任何关联的独立 shape,也不会共享给任何其他对象。把它想象成孤立的 shape:
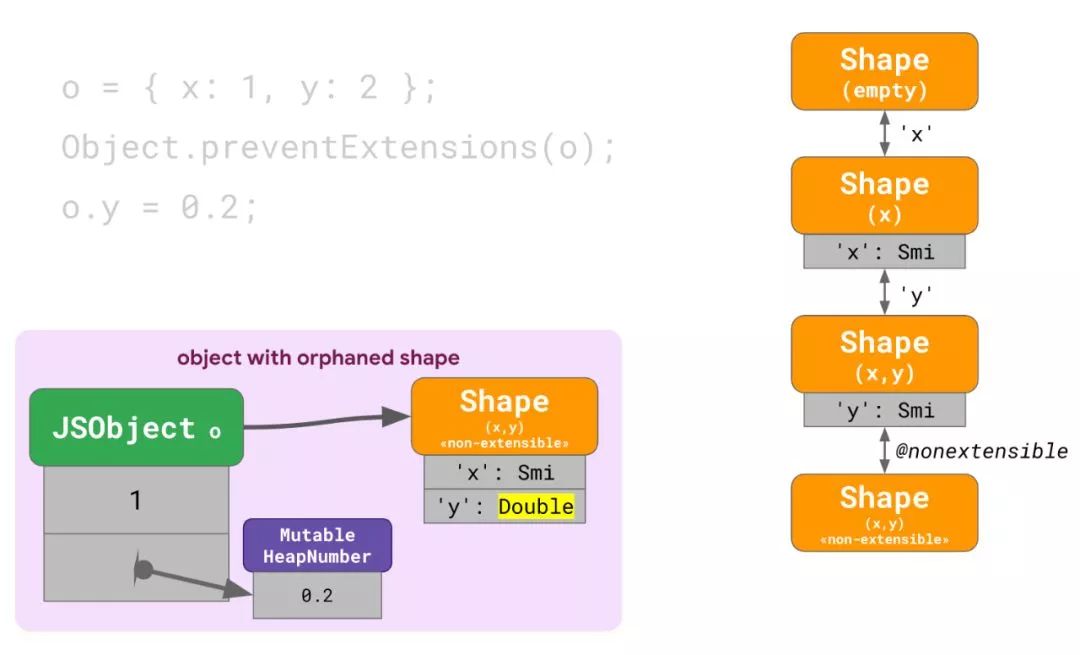
你可以想象到如果有大量的这样的对象出现这种情况将是非常糟糕的,因为这会使整个 shape 系统变得无用。
FiberNode有几个字段,用来在统计性能时保存一些时间戳。
class FiberNode {
constructor() {
this.actualStartTime = 0;
Object.preventExtensions(this);
}
}
const node1 = new FiberNode();
const node2 = new FiberNode();这些字段(比如说actualStartTime) 被初始化为0或者-1,因此一开始按照Smi表达。但是后面实际上存进来的是从performance.now()返回的浮点型时间戳,导致这些字段变成 Double 表达,因为这些数据不满足Smi表达的要求。最重要的是,React 还阻止了对FiberNode实例的扩展。
将上面的例子简化如下:
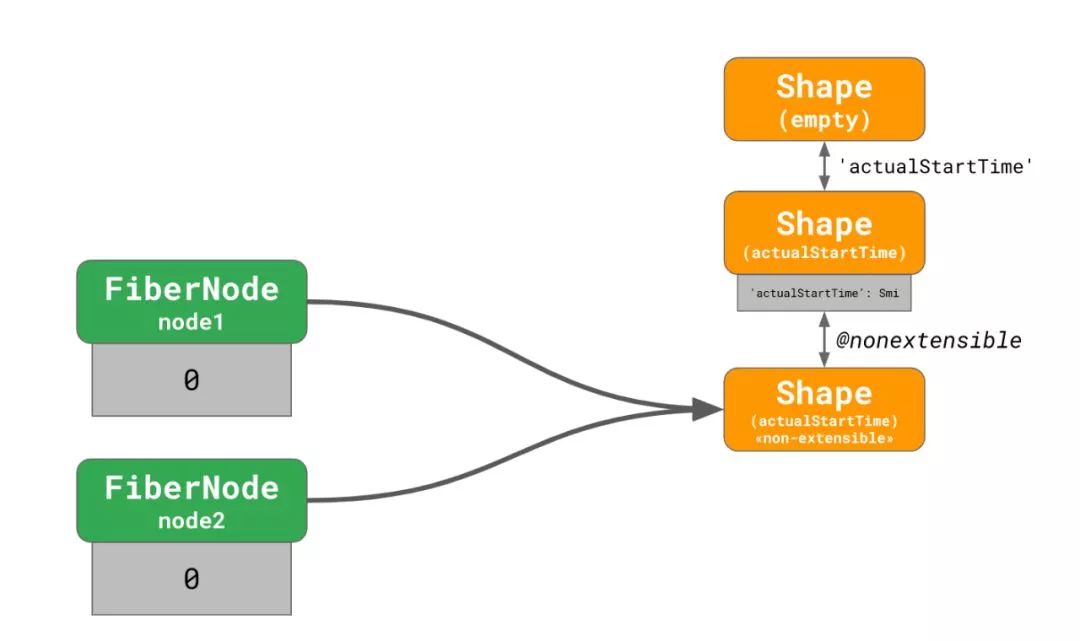
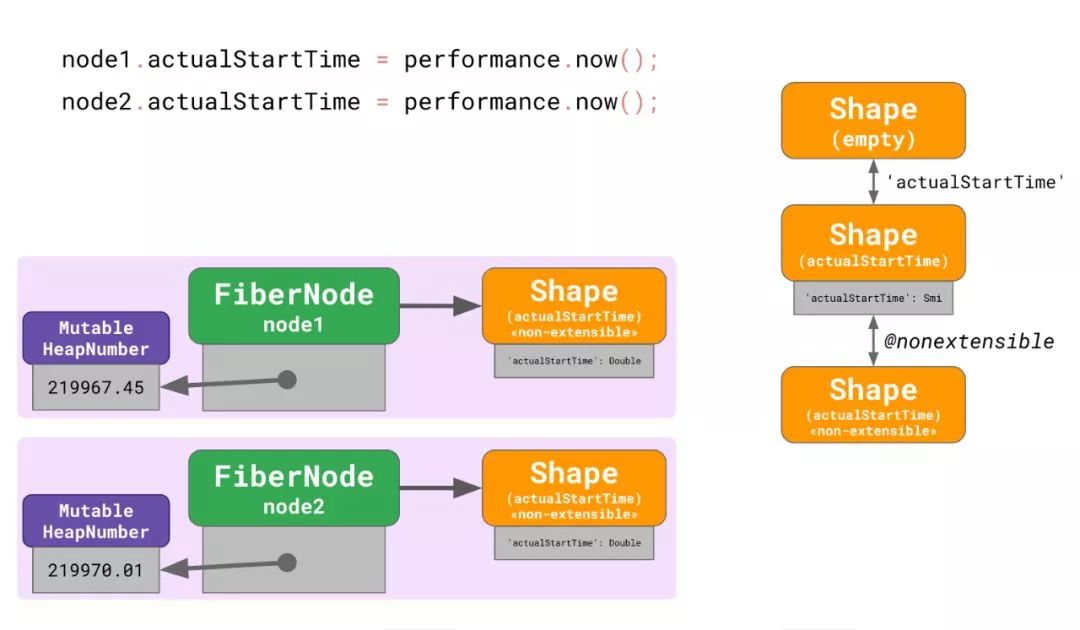
V8 指派了一个新的孤立 shape 给node1,然后稍后node2也发生了同样的情况,导致了两个孤岛,每个孤岛都有着自己不相交的 shape。很多真实的 React 应用不止有 2 个,而是有超过成千上万个FiberNodes。如你所想,这种情况对 V8 的性能来说不是什么好事。
幸运的是,我们已经在 V8 v7.4 中修复了这个性能悬崖,而且我们正在想办法让字段表达的改变更加高效来消除任何潜在的性能悬崖。在这个 fix 后,V8 现在做了正确的事:
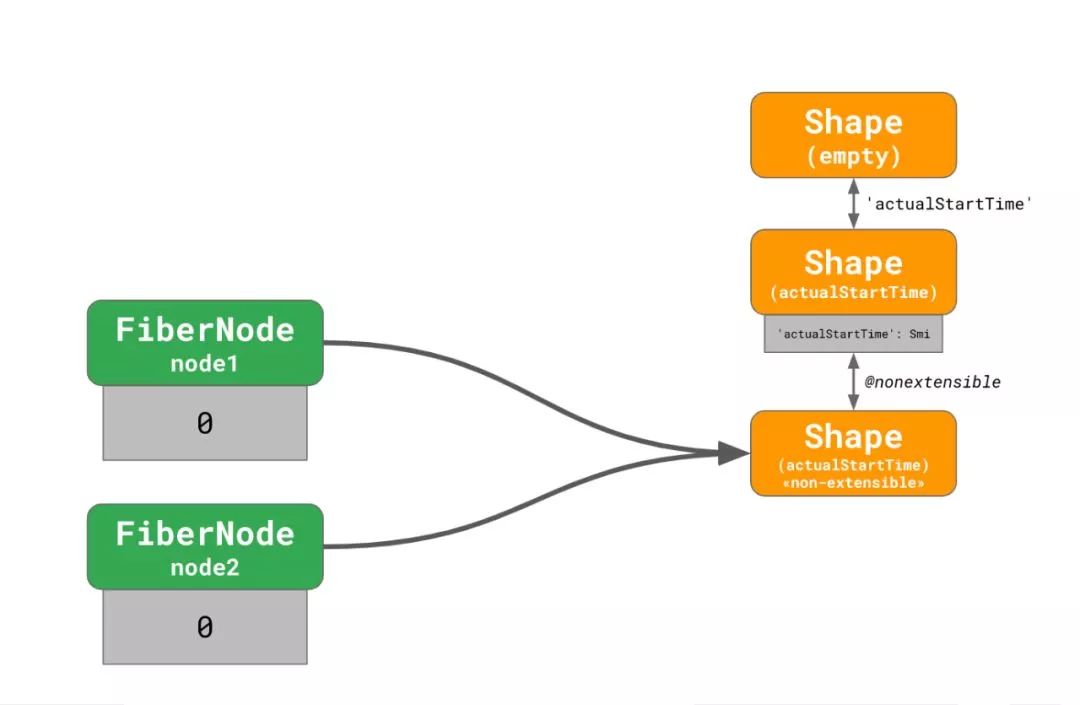
这两个FiberNode实例指向了不可扩展且actualStartTime为Smi表达的 shape。当第一个对node1.actualStartTime的赋值发生时,一个新的转变链被创建并且之前的转变链被标记为废弃的:
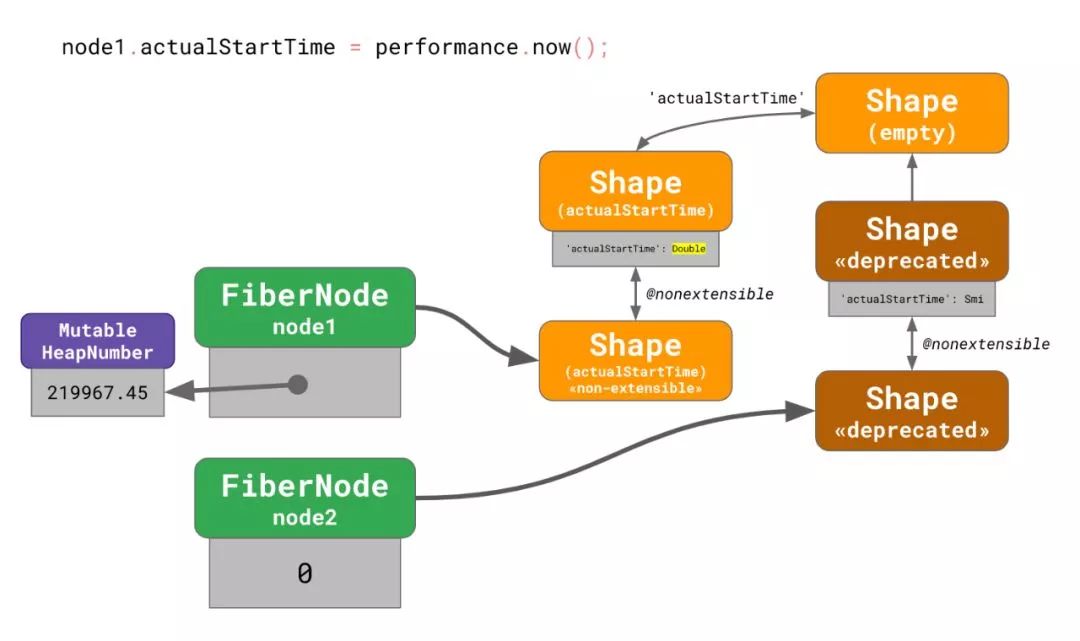
注意为何扩展性转变现在会正确的在新链中重放。

在对node2.actualStartTime赋值后,所有的节点引用了新的 shape,而且转变树中废弃的部分可以被垃圾回收器清理。
注意:也许你会认为 shape 的废弃 / 迁移很复杂,那你是对的。实际上,我们怀疑这个机制导致的问题(在性能,内存占用和复杂度上)比它带来的帮助要多,尤其是因为使用指针压缩,我们将无法再使用它来把 double-valued(双精度?) 字段内联到对象中。所以,我们希望完全移除掉 V8 的 shape 废弃机制。You could say it’s puts on sunglasses being deprecated. YEEEAAAHHH…(不知道该怎么翻译了 - -)
FiberNode的所有的时间和持续时间字段都被初始化为 Double 表达来规避这个问题。
class FiberNode {
constructor() {
// 从一开始就强制 w 诶 `Double` 表达
this.actualStartTime = Number.NaN;
// 然后你依然 k 恶意将这个值初始化为任何你想要的值
this.actualStartTime = 0;
Object.preventExtensions(this);
}
}
const node1 = new FiberNode();
const node2 = new FiberNode();不只是Number.NaN,任何不在 Smi 范围的浮点值都可以使用。比如说0.000001,Number.MIN_VALUE,-0,Infinity。
值得指出的的是这个 React 的 Bug 是 V8 规范导致的,开发者不应该为一个特定的 JavaScript 引擎做优化。尽管如此,当事情运转不正常时有个解决方案还是挺不错的。
null来初始化
number类型的字段,这不仅能避免使得所有字段表达跟踪带来收益全部失效,还能让你的代码变得更可读:
// Don’t do this!
class Point {
x = null;
y = null;
}
const p = new Point();
p.x = 0.1;
p.y = 402;换句话说,写可读的代码,然后性能自然就会提升。
-
JavaScript 对“基本类型”和“对象”的区分,而且 typeof 是个骗子。 -
即使具有相同 JavaScript 类型的值也可以在幕后具有不同的表示。 -
在你的 JavaScript 程序中,V8 会尝试为每个属性寻找最佳的表达方式。 我们讨论了 V8 如何处理 shape 废弃和迁移,包含了扩展性和转变的一些内容。
-
永远用同样的方式初始化你的对象,这样 shape 机制可以更有效。 使用合理的值来初始化你的字段,这样可以帮助 JavaScript 引擎更好地选择表达方式。
// 翻译得很渣,全程被 Google 机翻吊打 :(
英文原文: https://v8.dev/blog/react-cliff
IJKPlayer 是 BiliBIli 开源的一款基于 ffmpeg 的优秀的播放器,它支持 Android 和 iOS 双平台, API 易于集成,编译配置可裁剪,方便控制安装包大小,还支持硬件加速解码更省电......
最重要的一点是 IJKPlayer 还可以实现跨平台。这次 GMTC 全球大前端技术大会,我们专门请到了 B 站移动技术部负责移动端 IJKPlayer 相关工作的资深开发工程师郑翰超,做这次技术分享,从 B 站内部视角看看 IJKPlayer 的前世今生,全面了解这款播放器的演进之路。扫描下方二维码或点击阅读原文,查看详情。
目前 GMTC 深圳站 8 折售票通道已经开启,详细请咨询:13269078023(同微信)。