BAT机器学习面试题1000题(341~345题)

点击上方蓝字关注


BAT机器学习面试题1000题(341~345题)
341题
说说梯度下降法
解析:
1、什么是梯度下降法
经常在机器学习中的优化问题中看到一个算法,即梯度下降法,那到底什么是梯度下降法呢?
维基百科给出的定义是梯度下降法(Gradient descent)是一个一阶最优化算法,通常也称为最速下降法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法。
额,问题又来了,什么是梯度?为了避免各种复杂的说辞,咱们可以这样简单理解,在单变量的实值函数的情况,梯度就是导数,或者,对于一个线性函数,也就是线的斜率。
1.1 梯度下降法示例
举个形象的例子吧,比如当我们要做一个房屋价值的评估系统,那都有哪些因素决定或影响房屋的价值呢?比如说面积、房子的大小(几室几厅)、地段、朝向等等,这些影响房屋价值的变量被称为特征(feature)。在这里,为了简单,我们假定房屋只由一个变量影响,那就是房屋的面积。
假设有一个房屋销售的数据如下:
面积(m^2) 销售价钱(万元)
123 250
150 320
87 160
102 220
… …
插句题外话,顺便吐下槽,这套房屋价格数据在五年前可能还能买到帝都5环左右的房子,但现在只能买到二线城市的房屋了。
我们可以做出一个图,x轴是房屋的面积。y轴是房屋的售价,如下:

如果来了一个新的房子/面积,假设在房屋销售价格的记录中没有的,我们怎么办呢?
我们可以用一条曲线去尽量准的拟合这些数据,然后如果有新的输入面积,我们可以在将曲线上这个点对应的值返回。如果用一条直线去拟合房屋价格数据,可能如下图这个样子:

而图中绿色的点就是我们想要预测的点。
而图中绿色的点就是我们想要预测的点。
为了数学建模,首先给出一些概念和常用的符号。
房屋销售记录表 – 训练集(training set)或者训练数据(training data), 是我们流程中的输入数据,一般称为x
房屋销售价钱 – 输出数据,一般称为y
拟合的函数(或者称为假设或者模型),一般写做 y = h(x)
训练数据的条目数(#training set), 一条训练数据是由一对输入数据和输出数据组成的
输入数据的维度(特征的个数,#features),n
然后便是一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。
我们用X1,X2..Xn 去描述feature里面的分量,比如x1=房间的面积,x2=房间的朝向等等,我们可以做出一个估计函数:
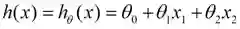
θ在这儿称为参数,在这儿的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。
如果我们令X0 = 1,就可以用向量的方式来表示了:

我们程序也需要一个机制去评估我们θ是否比较好,所以说需要对我们做出的h函数进行评估,一般这个进行评估的函数称为损失函数(loss function),描述h函数不好的程度,这里我们称这个函数为J函数。
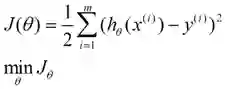
换言之,我们把对x(i)的估计值与真实值y(i)差的平方和作为损失函数,前面乘上的系数1/2是为了方便求导(且在求导的时候,这个系数会消掉)。
如何调整θ以使得J(θ)取得最小值有很多方法,其中有最小二乘法(min square),是一种完全是数学描述的方法,另外一种就是梯度下降法。
1.2 梯度下降算法流程
梯度下降法的算法流程如下:
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
为了描述的更清楚,给出下面的图:

这是一个表示参数θ与误差函数J(θ)的关系图,红色的部分是表示J(θ)有着比较高的取值,我们需要的是,能够让J(θ)的值尽量的低,也就是达到深蓝色的部分(让误差/损失最小嘛)。θ0,θ1表示θ向量的两个维度。
在上面提到梯度下降法的第一步是给θ给一个初值,假设随机给的初值是在图上的十字点。
然后我们将θ按照梯度下降的方向进行调整,就会使得J(θ)往更低的方向进行变化,如下图所示,算法的结束将是在θ下降到无法继续下降为止。
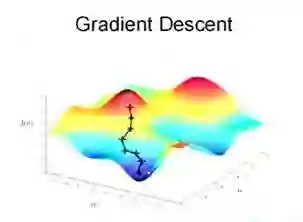
当然,可能梯度下降的最终点并非是全局最小点,即也可能是一个局部最小点,如下图所示:
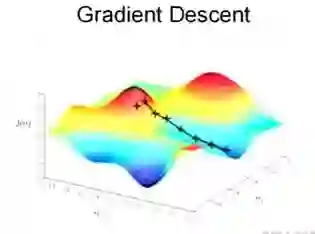
上面这张图就是描述的一个局部最小点,这是我们重新选择了一个初始点得到的,看来我们这个算法将会在很大的程度上被初始点的选择影响而陷入局部最小点。
下面我将用一个例子描述一下梯度减少的过程,对于我们的函数J(θ)求偏导J:
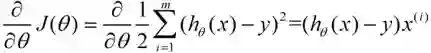
下面是更新的过程,也就是θi会向着梯度最小的方向进行减少。θi表示更新之前的值,-后面的部分表示按梯度方向减少的量,α表示步长,也就是每次按照梯度减少的方向变化多少。
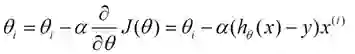
一个很重要的地方值得注意的是,梯度是有方向的,对于一个向量θ,每一维分量θi都可以求出一个梯度的方向,我们就可以找到一个整体的方向,在变化的时候,我们就朝着下降最多的方向进行变化就可以达到一个最小点,不管它是局部的还是全局的。
用更简单的数学语言进行描述步骤2)是这样的:
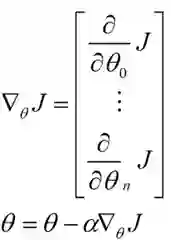
本题解析来源:@LeftNotEasy,链接:http://www.cnblogs.com/LeftNotEasy/archive/2010/12/05/mathmatic_in_machine_learning_1_regression_and_gradient_descent.html
342题
牛顿法和梯度下降法有什么不同?
解析:
牛顿法(Newton's method)
牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。
具体步骤:
首先,选择一个接近函数 f (x)零点的 x0,计算相应的 f (x0) 和切线斜率f ' (x0)(这里f ' 表示函数 f 的导数)。
然后我们计算穿过点(x0,f(x0))并且斜率为f '(x0)的直线和x轴的交点的x坐标,也就是求如下方程的解:
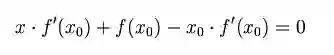
我们将新求得的点的 x 坐标命名为x1,通常x1会比x0更接近方程f (x) = 0的解。
因此我们现在可以利用x1开始下一轮迭代。迭代公式可化简为如下所示:
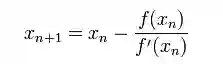
已经证明,如果f'是连续的,并且待求的零点x是孤立的,那么在零点x周围存在一个区域,只要初始值x0位于这个邻近区域内,那么牛顿法必定收敛。 并且,如果f'(x)不为0, 那么牛顿法将具有平方收敛的性能. 粗略的说,这意味着每迭代一次,牛顿法结果的有效数字将增加一倍。
由于牛顿法是基于当前位置的切线来确定下一次的位置,所以牛顿法又被很形象地称为是"切线法"。牛顿法的搜索路径(二维情况)如下图所示:
关于牛顿法和梯度下降法的效率对比:
a)从收敛速度上看 ,牛顿法是二阶收敛,梯度下降是一阶收敛,前者牛顿法收敛速度更快。但牛顿法仍然是局部算法,只是在局部上看的更细致,梯度法仅考虑方向,牛顿法不但考虑了方向还兼顾了步子的大小,其对步长的估计使用的是二阶逼近。
b)根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
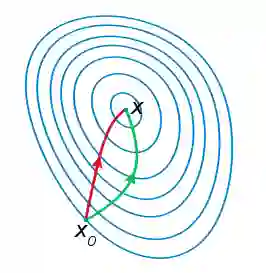
注:红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
本题解析来源:@wtq1993,链接:http://blog.csdn.net/wtq1993/article/details/51607040
343题
熵、联合熵、条件熵、相对熵、互信息的定义
解析:
为了更好的理解,需要了解的概率必备知识有:
大写字母X表示随机变量,小写字母x表示随机变量X的某个具体的取值;
P(X)表示随机变量X的概率分布,P(X,Y)表示随机变量X、Y的联合概率分布,P(Y|X)表示已知随机变量X的情况下随机变量Y的条件概率分布;
p(X = x)表示随机变量X取某个具体值的概率,简记为p(x);
p(X = x, Y = y) 表示联合概率,简记为p(x,y),p(Y = y|X = x)表示条件概率,简记为p(y|x),且有:p(x,y) = p(x) * p(y|x)。
熵:如果一个随机变量X的可能取值为X = {x1, x2,…, xk},其概率分布为P(X = xi) = pi(i = 1,2, ..., n),则随机变量X的熵定义为:
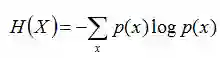
把最前面的负号放到最后,便成了:
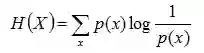
上面两个熵的公式,无论用哪个都行,而且两者等价,一个意思(这两个公式在下文中都会用到)。
联合熵:两个随机变量X,Y的联合分布,可以形成联合熵Joint Entropy,用H(X,Y)表示。
条件熵:在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用H(Y|X)表示,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。
且有此式子成立:H(Y|X) = H(X,Y) – H(X),整个式子表示(X,Y)发生所包含的熵减去X单独发生包含的熵。至于怎么得来的请看推导:
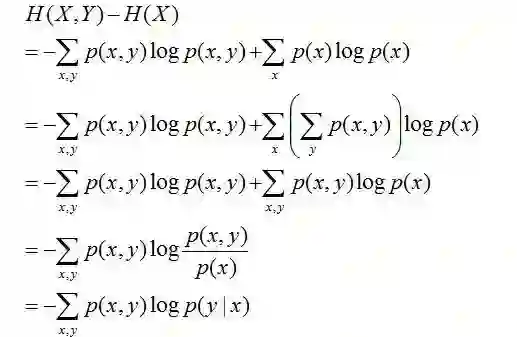
简单解释下上面的推导过程。整个式子共6行,其中
第二行推到第三行的依据是边缘分布p(x)等于联合分布p(x,y)的和;
第三行推到第四行的依据是把公因子logp(x)乘进去,然后把x,y写在一起;
第四行推到第五行的依据是:因为两个sigma都有p(x,y),故提取公因子p(x,y)放到外边,然后把里边的-(log p(x,y) - log p(x))写成- log (p(x,y)/p(x) ) ;
第五行推到第六行的依据是:p(x,y) = p(x) * p(y|x),故p(x,y) / p(x) = p(y|x)。
相对熵:又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度等。设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是:

在一定程度上,相对熵可以度量两个随机变量的“距离”,且有D(p||q) ≠D(q||p)。另外,值得一提的是,D(p||q)是必然大于等于0的。
互信息:两个随机变量X,Y的互信息定义为X,Y的联合分布和各自独立分布乘积的相对熵,用I(X,Y)表示:

且有I(X,Y)=D(P(X,Y) || P(X)P(Y))。下面,咱们来计算下H(Y)-I(X,Y)的结果,如下:
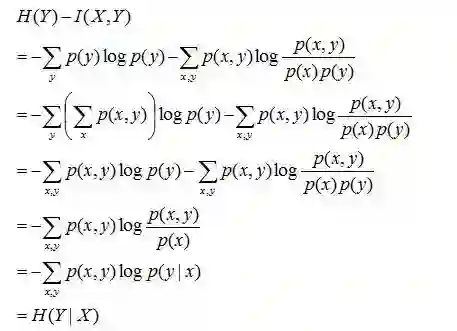
通过上面的计算过程,我们发现竟然有H(Y)-I(X,Y) = H(Y|X)。故通过条件熵的定义,有:H(Y|X) = H(X,Y) - H(X),而根据互信息定义展开得到H(Y|X) = H(Y) - I(X,Y),把前者跟后者结合起来,便有I(X,Y)= H(X) + H(Y) - H(X,Y),此结论被多数文献作为互信息的定义。更多请查看《最大熵模型中的数学推导》(链接:http://blog.csdn.net/v_july_v/article/details/40508465)。
344题
说说你知道的核函数
解析:
通常人们会从一些常用的核函数中选择(根据问题和数据的不同,选择不同的参数,实际上就是得到了不同的核函数),例如:
多项式核
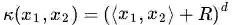
显然刚才我们举的例子是这里多项式核的一个特例(R = 1,d = 2)。虽然比较麻烦,而且没有必要,不过这个核所对应的映射实际上是可以写出来的,该空间的维度是
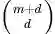
其中 m 是原始空间的维度。
高斯核
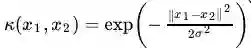
这个核就是最开始提到过的会将原始空间映射为无穷维空间的那个家伙。
不过,如果 σ 选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;
反过来,如果 σ 选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。
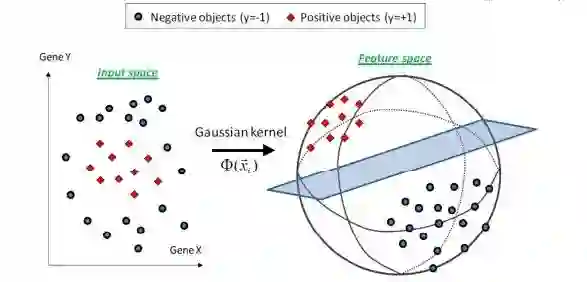
不过,总的来说,通过调控参数 σ ,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。下图所示的例子便是把低维线性不可分的数据通过高斯核函数映射到了高维空间:
线性核
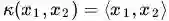
这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
345题
什么是拟牛顿法(Quasi-Newton Methods)?
解析:
拟牛顿法是求解非线性优化问题最有效的方法之一,于20世纪50年代由美国Argonne国家实验室的物理学家W.C.Davidon所提出来。Davidon设计的这种算法在当时看来是非线性优化领域最具创造性的发明之一。不久R. Fletcher和M. J. D. Powell证实了这种新的算法远比其他方法快速和可靠,使得非线性优化这门学科在一夜之间突飞猛进。
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。拟牛顿法和最速下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于最速下降法,尤其对于困难的问题。
另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
具体步骤:
拟牛顿法的基本思想如下。首先构造目标函数在当前迭代xk的二次模型:
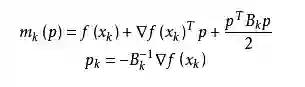
这里Bk是一个对称正定矩阵,于是我们取这个二次模型的最优解作为搜索方向,并且得到新的迭代点:
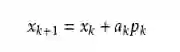
其中我们要求步长ak 满足Wolfe条件。这样的迭代与牛顿法类似,区别就在于用近似的Hessian矩阵Bk 代替真实的Hessian矩阵。所以拟牛顿法最关键的地方就是每一步迭代中矩阵Bk 的更新。现在假设得到一个新的迭代xk+1,并得到一个新的二次模型:
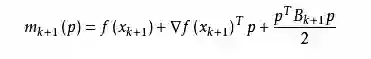
我们尽可能地利用上一步的信息来选取Bk。具体地,我们要求
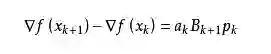
从而得到

这个公式被称为割线方程。常用的拟牛顿法有DFP算法和BFGS算法。
本题解析来源:@wtq1993,链接:http://blog.csdn.net/wtq1993/article/details/51607040
福利时刻:为了帮助大家更加系统地学习机器学习课程的相关知识,我们特意推出了【机器学习集训营 第六期】系列课程。10月22日开课,2人及2人以上组团报名,可各减500元,还没报名的小伙伴们抓紧时间喽~~
(ps:点击下方“阅读原文”可在线报名,详细可添加客服咨询:julyedukefu_02)


更多资讯
请戳一戳


往期精选
Kaggle CTO 力荐 | 从Kaggle历史数据看竞赛趋势
AI面经 | 场场面试均拿下offer,人称“offer收割机”
干货合集 | 教你如何使用Excel 9步实现卷积网络
分享一哈 | 通俗理解kaggle比赛大杀器xgboost

点击“阅读原文”,可在线报名



