EMNLP 2018 | 用强化学习做神经机器翻译:中山大学&MSRA填补多项空白
选自arXiv
作者:Lijun Wu、Fei Tian、Tao Qin、Jianhuang Lai、Tie-Yan Liu
机器之心编译
参与:Panda
人工深度学习和神经网络已经为机器翻译带来了突破性的进展,强化学习也已经在游戏等领域取得了里程碑突破。中山大学数据科学与计算机学院和微软研究院的一项研究探索了强化学习在神经机器翻译领域的应用,相关论文已被 EMNLP 2018 接收,相关代码和数据集也已开源。
论文地址:https://arxiv.org/abs/1808.08866
开源项目:https://github.com/apeterswu/RL4NMT
神经机器翻译(NMT)[Bahdanau et al., 2015; Hassan et al., 2018; Wu et al., 2016; He et al., 2017; Xia et al., 2016, 2017; Wu et al., 2018b,a] 近来变得越来越受欢迎了,因为这种方法表现更优,而且无需繁重的人工工程工作。其训练过程通常是:通过取源句子和之前已有的(基本真值)目标 token 作为输入,以最大化目标句子中每个 token 的似然。这样的训练方法被称为最大似然估计(MLE)[Scholz, 1985]。尽管易于实现,但在训练阶段的 token 层面的目标函数与 BLEU [Papineni et al., 2002] 等序列层面的评估指标却并不一致。
为了解决不一致的问题,强化学习(RL)方法已经在序列层面的目标优化上得到了应用。比如,研究者已将 REINFORCE [Ranzato et al., 2016; Wu et al., 2017b] 和 actor-critic [Bahdanau et al., 2017] 等策略优化方法用在了包括 NMT 在内的序列生成任务上。在机器翻译领域,也有相似的方法被提出——被称为「最小风险训练」[Shen et al., 2016]。所有这些研究都表明强化学习技术可以有效地用于 NMT 模型 [Wu et al., 2016].
但是,之前还没有将强化学习有效应用于现实世界 NMT 系统的研究成果。首先,大多数研究(甚至可能全部研究)都是基于浅的循环神经网络(RNN)模型验证他们的方法。但是,为了得到当前最佳的表现,利用近期发展起来的深度模型 [Gehring et al., 2017; Vaswani et al., 2017] 将至关重要,这些模型的能力要强大得多。
其次,强化学习方法存在相当一些众所周知的局限性 [Henderson et al., 2018],比如梯度估计方差高 [Weaver and Tao, 2001] 以及目标不稳定 [Mnih et al., 2013],因此要让强化学习实现有效的实际应用,其实并不容易。因此,之前的研究提出了一些技巧。但是,如何将这些技巧应用于机器翻译?这一点仍还不够明朗,研究者也没有达成共识。举个例子,[Ranzato et al., 2016; Nguyen et al., 2017; Wu et al., 2016] 等研究建议使用的基准奖励方法 [Weaver and Tao, 2001] 并没有得到 [He and Deng, 2012; Shen et al., 2016] 等研究的采纳。
第三,研究已经表明,使用 MLE 训练时,大规模数据(尤其是单语言数据集)能为翻译质量带来显著提升 [Sennrich et al., 2015a; Xia et al., 2016]。但如何在 NMT 中将强化学习与单语言数据结合起来?这方面几乎仍是研究真空。
我们希望能通过这篇论文填补这些空白;我们还研究了可以如何应用强化学习来得到强大的 NMT 系统,使其能取得有竞争力的表现,甚至达到当前最佳。我们对强化学习训练的不同方面执行了几项综合研究,以便了解如何:1)设置有效的奖励;2)以不同的权重结合 MLE 和强化学习,从而实现训练过程的稳定;3)降低梯度估计的方差。
此外,因为利用单语言数据在提升翻译质量上是有效的,所以我们进一步提出了一种将强化学习训练的能力和源/目标单语言数据结合起来的新方法。就我们所知,这是在使用强化学习方法训练 NMT 模型方面探索单语言数据的效果的首个研究尝试。
我们在 WMT17 汉英翻译(Zh-En)、WMT17 英汉翻译(En-Zh)和 WMT14 英德翻译(En-De)任务上执行了实验,并得到了一些有用的发现。比如,多项式采样在奖励计算方面优于波束搜索,强化学习和单语言数据的结合能显著提升 NMT 模型的表现。我们的主要贡献总结如下。
我们立足于相当有竞争力的 NMT 模型,提供了首个对强化学习训练不同方面的全面研究,比如如何设置奖励和基准奖励。
我们提出了一种能有效利用大规模单语言数据的新方法,可在使用强化学习训练 NMT 模型时使用,并且这些单语言数据来自源语言和目标语言都可以。
将我们的这些研究发现和新方法结合到一起,我们在 WMT17 汉英翻译人上取得了当前最佳的表现,超越了强基准(Transformer 大模型+反向翻译)近 1.5 BLEU。此外,我们在 WMT14 英德翻译和 WMT17 英汉翻译任务上也得到了足以媲美最佳的结果。
我们希望我们的研究和发现将有助于社区更好地理解和利用强化学习来开发强大的 NMT 模型,尤其是在面临着深度模型和大量训练的现实世界场景中(包括有双语对应的数据和单语言数据)。
为此,我们开源了所有的代码和数据集以帮助其他人再现这一研究成果:https://github.com/apeterswu/RL4NMT。
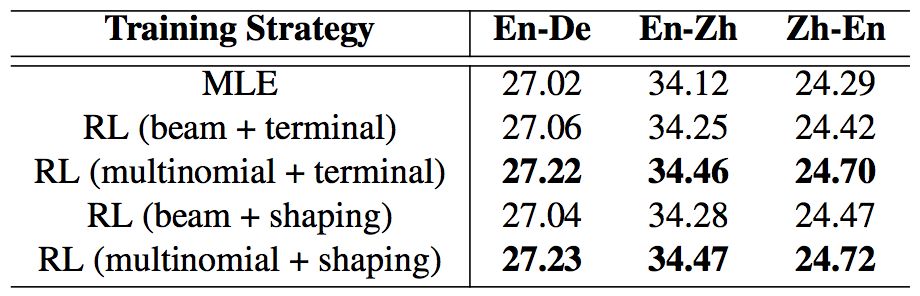
表 1:不同的奖励计算策略的结果。beam 表示波束搜索,multinomial 表示多项式采样。在通过波束搜索生成 yˆ 时,我们所用的宽度为 4。shaping 是指使用了奖励塑造(reward shaping),而 terminal 表示没有使用。
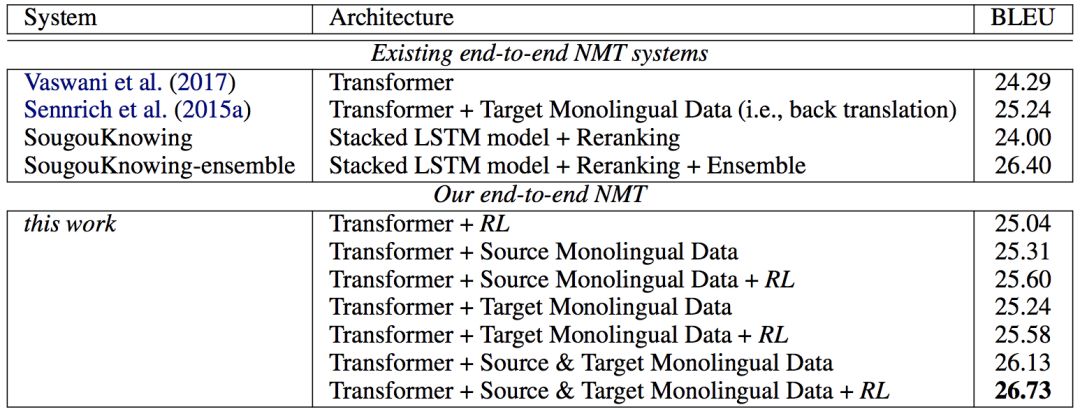
表 7:表现差不多的不同端到端 NMT 系统的结果比较。SougouKnowing 的结果来自 http://matrix.statmt.org/matrix/systems_list/1878.
最后,作为对我们的实验结果的总结,我们将几种有代表性的端到端 NMT 系统与我们的研究成果进行了比较,如表 7 所示,其中包含 Transformer [Vaswani et al., 2017] 模型,使用以及没使用反向翻译的方法 [Sennrich et al., 2015a],以及在 WMT17 汉英翻译挑战赛上表现最好的 NMT 系统(SougouKnowing-ensemble)。结果清楚地表明,在将源侧和目标侧的单语言数据与强化学习训练结合到一起之后,我们能得到当前最佳的 BLEU 分数 26.73,甚至超过了在 WMT17 汉英翻译挑战赛上最佳的集成模型。
论文:一项将强化学习用于神经机器翻译的研究

论文链接:https://arxiv.org/abs/1808.08866
摘要:近期的研究已经表明,强化学习(RL)方法可以有效提升神经机器翻译(NMT)系统的表现。但是,由于不稳定,成功完成强化学习训练是很困难的,尤其是在使用了深度模型和大型数据集的现实世界系统中。在这篇论文中,我们使用了几个大规模翻译任务作为测试平台,系统性地研究了使用强化学习训练更好的 NMT 模型的方法。我们对强化学习训练领域的几个重要因素(比如基准奖励、奖励塑造)进行了全面的比较。此外,之前我们也不清楚强化学习能否助益仅使用单语言数据的情况。为了填补这一空白,我们提出了一种利用强化学习通过使用源/目标单语言数据来进一步提升 NMT 系统的表现的新方法。通过整合我们所有的发现,我们在 WMT14 英德翻译、WMT17 英汉翻译和 WMT17 汉英翻译任务上取了媲美最佳的结果,尤其是在 WMT17 汉英翻译上确实实现了当前最佳。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




