用手机检测皮肤癌
【导读】任何类型的癌症,即使不致命,也是非常严重的。分析癌症从来就不是一件简单事,而需要深入研究。该项目基于TF2.0 的tflite框架,开发了一个检测皮肤癌的工程。
Github地址:
https://github.com/AakashKumarNain/skin_cancer_detection
简介
超过50%的癌变是通过组织病理学(组织病理学)确认的,其余病例是随访检查(follow_up),专家共识(共识),或通过体内共聚焦显微镜确认(共聚焦) 。缺乏专家(放射科医生)一直是瓶颈。现在我们需要考虑三件事:
鉴于专家数量有限,我们如何才能提高效率呢?我们可以使用最先进的机器学习技术来帮助他们吗?如果有,怎么做?
用于自动诊断色素性皮肤病变的神经网络的训练受到皮肤镜图像的可用数据集的小尺寸和缺乏多样性的阻碍。医疗保健中的标签数据是另一个瓶颈。有了可用的有限数据,我们可以做多少?
作为机器学习工程师,如果我们无法帮助医生并最终帮助社会,那么我们擅长什么?医疗保健是一个复杂的领域,在这个领域使用机器学习有其自身的优点和缺点。
数据集
数据集是Kaggle数据集(https://www.kaggle.com/kmader/skin-cancer-mnist-ham10000)的一部分,它由存放在两个文件夹中的10000张图片组成,数据格式如下所示:
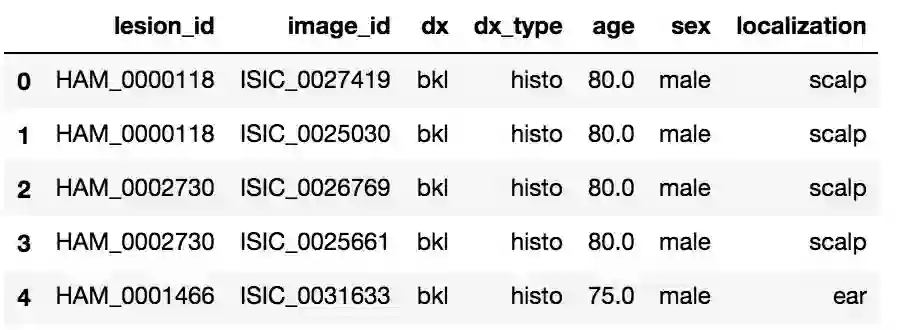
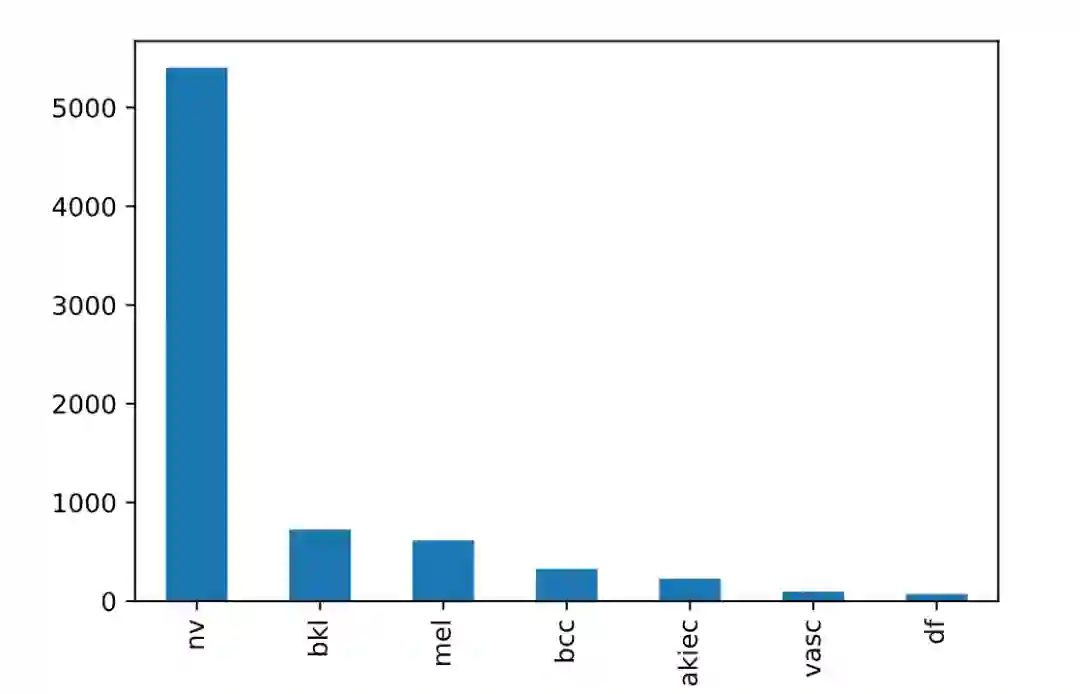
数据集中总共有7个类型的皮肤癌,除去重复的图片,共有约8k张图片,数据集非常不均衡,这也带来一定的难度,数据集的分布如下图所示。
模型结构
项目的最终目的是学到一个能在手机上运行的模型,考虑到这点,我能能用的架构只有Mobilenet_v1, MobileNet_v2, M-Nasnet, 和Shufflenet这几个,我们最终选取mobilenets ,因为他们在keras model zoo中有,我们最终选取了MobileNetv2 因为它比Mobilenet_v1快。模型的架构如下所示:
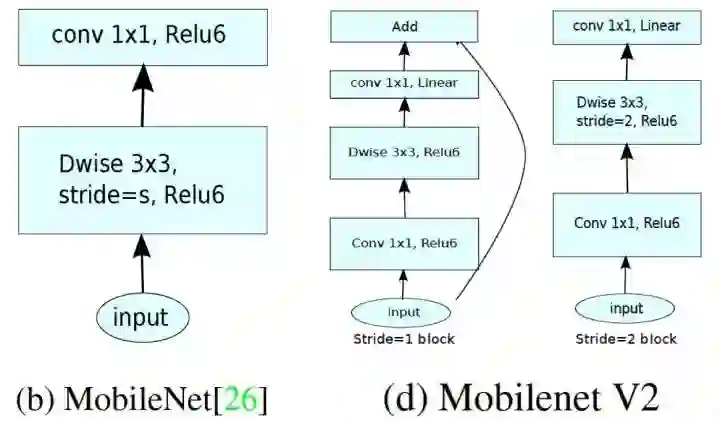
基础的网络用语特征提取,而最高几层用于分类,我们丢弃mobilenet 最后一个特征提取层 global average pooling以上层,训练模型可以分成以下两个阶段:
迁移学习:在基础网络的基础上增加用于分类的层,训练的时候固定基础网络的参数。
微调:不固定基础网络某些层的参数,微调来提升效果。
Demo
最终的模型可以在安卓app上用CPU运行。
如下为正确运行的demo:
实验效果
最终训练误差:0.4029
最终验证误差:0.6417
训练类别准确度(top-1): 0.8627
验证类别准确度(top-1): 0.7897
训练类别准确度(top-2): 0.9612
验证类别准确度(top-2): 0.9123
混淆矩阵
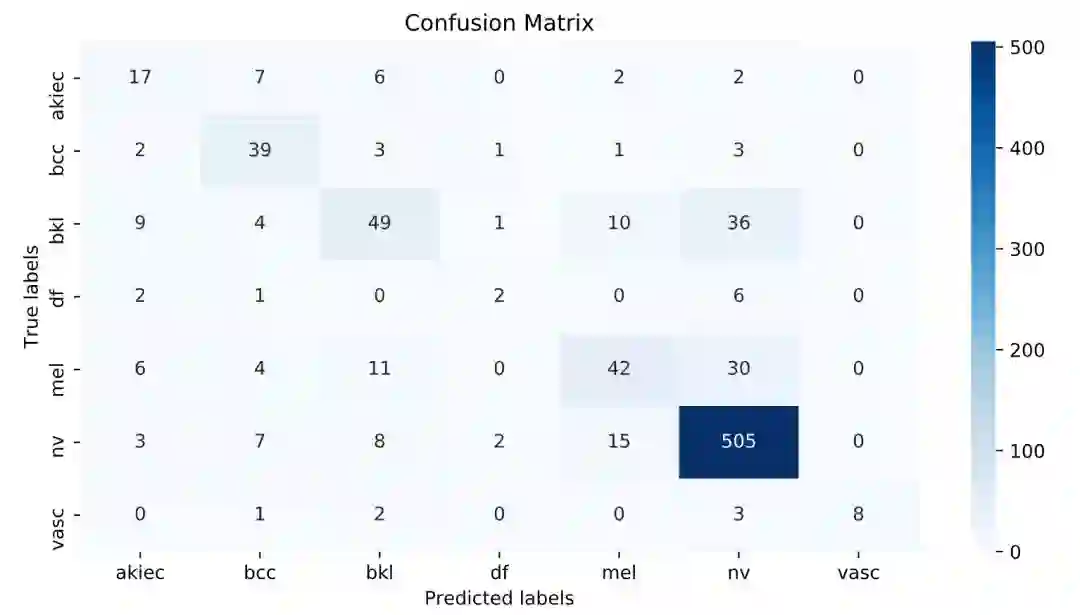
每个类别的分类精度
precision recall f1-score supportakiec 0.44 0.50 0.47 34bcc 0.62 0.80 0.70 49bkl 0.62 0.45 0.52 109df 0.33 0.18 0.24 11mel 0.60 0.45 0.52 93nv 0.86 0.94 0.90 540vasc 1.00 0.57 0.73 14micro avg 0.78 0.78 0.78 850macro avg 0.64 0.56 0.58 850weighted avg 0.77 0.78 0.77 850
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!540+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程


