加入AI行业拿到高薪仅仅是职业生涯的开始。现阶段AI人才结构在不断升级,这也意味着如果目前仍然停留在调用一些函数库,则在未来1-2年内很大概率上会失去核心竞争力的。
几年前如果熟练使用TensorFlow,同时掌握基本的AI算法就可以很容易找到一份高薪的工作,但现在不一样了,AI岗位的要求越来越高,对知识的深度也提出了更高的要求。
如果现在一个
面试官
让你从零推导SVM的Dual、从零实现CRF、推导LDA、设计一个QP问题、从零编写XLNet、编写GCN/GNN、改造SkipGram模型、用一天时间复现一篇顶级会议....
这些要求一点都不过分。相反,连这些基本内容都有些吃力,就需要重新审视一下自己的核心技术壁垒了。
目前AI人才竞争越来越激烈,“调参侠”的时代已慢慢过去,这些事情其实根本不需要AI工程师来做,未来的研发工程师就可以承担这些了!
从事AI行业多年,但技术上总感觉不够深入,而且很难再有提升;
对每个技术点了解,但不具备体系化的认知,无法把它们串起来;
停留在使用模型/工具上,很难基于业务场景来提出新的模型;
对于机器学习背后的优化理论、前沿的技术不够深入;
计划从事尖端的科研、研究工作、申请AI领域研究生、博士生;
打算进入最顶尖的AI公司比如Google,Facebook,Amazon, 阿里,头条等;
为了迎合时代的需求,贪心学院(国内唯一体系化AI学院)目前推出了两门高端的AI训练营,分别是《机器学习高阶训练营》和《自然语言处理高阶训练营》。
需要一定的AI基础,是为进阶人士量身定做的一套AI进阶课程,
采用
全程直播授课模式,近距离接触顶级讲师。
那这样的训练营到底是怎么样的呢? 下面以《机器学习高阶训练营》为例。 《自然语言处理高阶训练营》的内容可以添加我们专业的AI职业规划师来咨询。
本阶段主要目的是讲解必要的算法理论以及凸优化技术,为后续的课程打下基础。凸优化的重要性不言而喻,如果想具备改造模型的能力,对于凸优化的理解是必不可少的!
- 正则:L1, L2, L-inifity Norm
- Duality,Strong Duality、KKT条件
- 带条件/无条件优化问题、Projected GD
- 平滑函数、Convergence Analysis
本阶段主要目的是深入理解SVM以及核函数部分的知识点。为了理解清楚SVM的Dual转换,需要掌握第一部分里的Duality理论。另外,重点介绍Bagging和Boosting模型,以及所涉及到的几项有趣的理论。
- SVM的Dual、Kernelized SVM
- Kernel Functions, Mercer'定理
- Kernelized LR/KNN/K-Means/PCA
- Bagging, Boosting, Stacking
- 基于Kernal PCA和Linear SVM的人脸识别
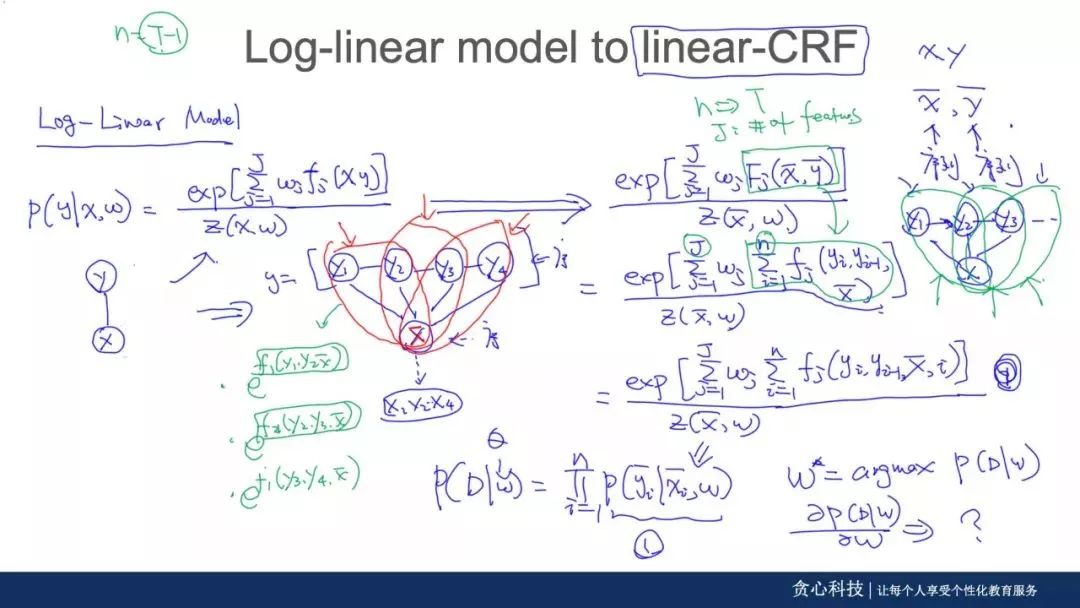
本阶段主要目的是学习无监督算法和经典的序列模型。重点讲解EM算法以及GMM,K-means的关系,同时花几次课程时间来仔细讲解CRF的细节:从无向图模型、Potential函数、Log-Linear Model、逻辑回归、HMM、MEMM、Label Bias、Linear CRF、Inference,最后到Non-Linear CRF。
- 层次聚类,DCSCAN,Spectral聚类算法
- 条件独立、D-Separation、Markov性质
- HMM以及基于Viterbi的Decoding
- Log-Linear Model,逻辑回归,特征函数
本阶段主要讲解深度学习理论以及常见的模型。这里包括BP算法、卷积神经网络、RNN/LSTM、BERT、XLNet、ALBERT以及各类深度学习图模型。另外,也会涉及到深度相关的优化以及调参技术。
- Dropout与Batch Normalization
- Word2Vec, Elmo, Bert, XLNet
- 深度学习与图嵌入(Graph Embedding)
- Translating Embedding (TransE)
- Node2Vec- Graph Convolutional Network
- Dynamic Graph Embedding
推荐系统一直是机器学习领域的核心,所以在本阶段重点来学习推荐系统领域主流的算法以及在线学习的技术、包括如何使用增强学习来做推荐系统。 在线学习算法很深具有很漂亮的理论基础,在本阶段你都会一一体会到!
- Exploration vs Exploitation
- UCB1 algorithm,EXP3 algorithm
- Adversarial Bandit model
- Contexulalized Bandit、LinUCB
- 使用GB Tree做基于 interaction 与 content的广告推荐
- 使用深度神经网络做基于interaction 与 content的推荐
- LinUCB做新闻推荐, 最大化rewards
本阶段重点讲解贝叶斯模型。贝叶斯派区别于频率派,主要的任务是估计后验概率的方式来做预测。我们重点讲解主题模型以及不同的算法包括吉布采样、变分法、SGLD等,以及如何把贝叶斯的框架结合在深度学习模型里使用,这就会衍生出Bayesian LSTM的模型。贝叶斯部分的学习需要一定的门槛,但我们会让每个人听懂所有细节!
- Dirichlet/Multinomial Distribution
- Metropolis Hasting与Gibbs Sampling
- 使用Collapsed Gibbs Sampler求解LDA
- Mean-field variational Inference
- Stochastic Optimization与贝叶斯估计
- 随机过程与无参模型(non-parametric)
- Chinese Retarant Process
- Stochastic Block Model与MMSB
- Bayesian Deep Learning模型
本阶段重点讲解增强学习以及前沿的内容,包括增强学习在文本领域的应用,GAN, VAE,图片和文本的Disentangling,深度学习领域可解释性问题、Adversial Learning, Fair Learning等最前沿的主题。 这一阶段的安排也会根据学员的兴趣点做局部的调整。
- Policy Learning、Deep RL
- Variational Autoencoder(VAE)与求解
- Generative Adversial Network(GAN)
- Adversial Machine Learning
对课程有意向的同学
添加课程顾问小姐姐微信
报名、课程咨询
👇👇👇
![]()
区别于劣质的PPT讲解,导师全程现场推导,
让你在学习中有清晰的思路,深刻的理解算法模型背后推导的每个细节。更重要的是可以清晰地看到各种模型之间的关系!帮助你打通六脉!
▲源自:Convex Optimization 讲解
▲源自:Convergence Analysis 讲解
不管你在学习过程中遇到多少阻碍,你都可以通过以下4种方式解决:
4、共同的问题在Review Session里面做讲解
注:每次答疑,班主任都会进行记录,以便学员实时查阅。
采用直播的授课方式,每周3-4次直播教学,包含核心理论课、实战课、复习巩固课以及论文讲解课。教学模式上也参考了美国顶级院校的教学体系。以下为其中一周的课程安排,供参考。
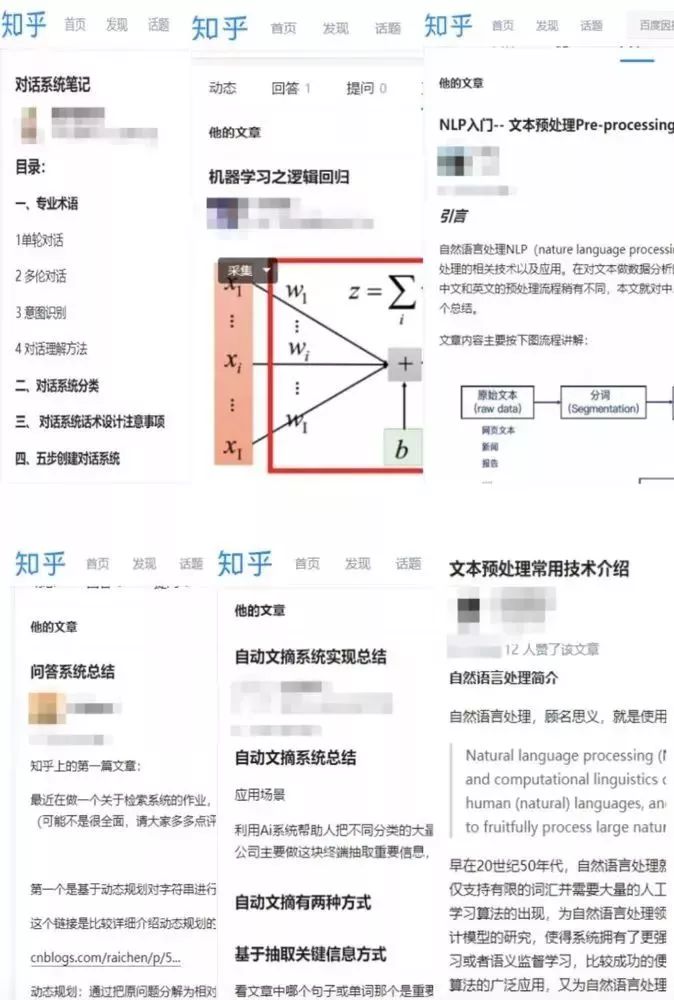
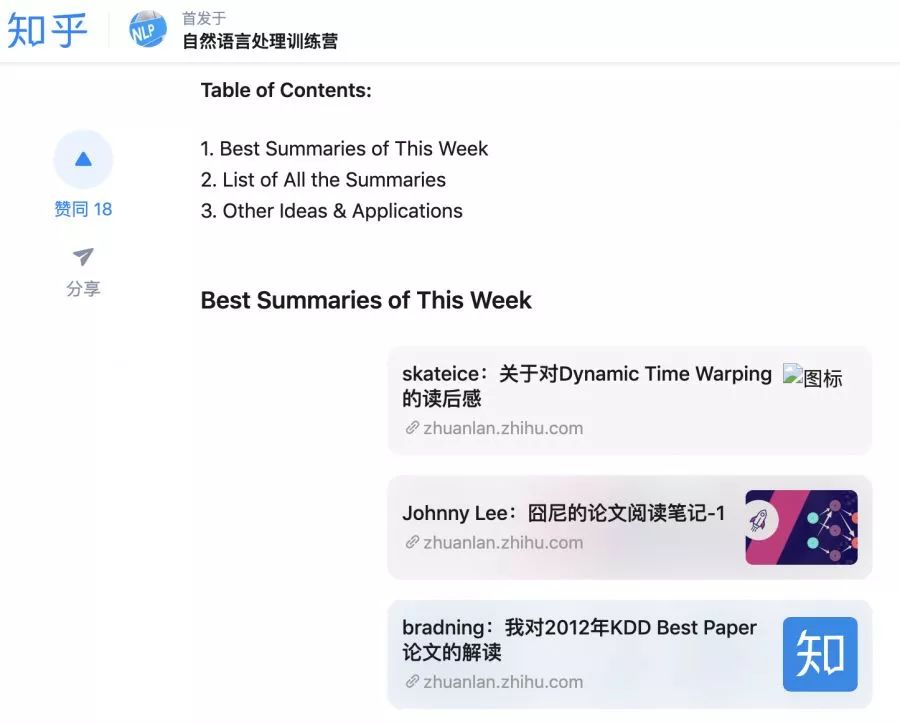
通过在知乎上发表相关技术文章进行自我成果检验,同时也是一种思想碰撞的方式,导师会对发表的每一篇文章写一个详细的评语。万一不小心成为一个大V了呢?虽然写文章的过程万分痛苦,学习群里半夜哀嚎遍野,但看一看抓着头发写出来的文章结果还是非常喜人的!看着自己收获的点赞数,大家都默默地感谢起导师们的无情!
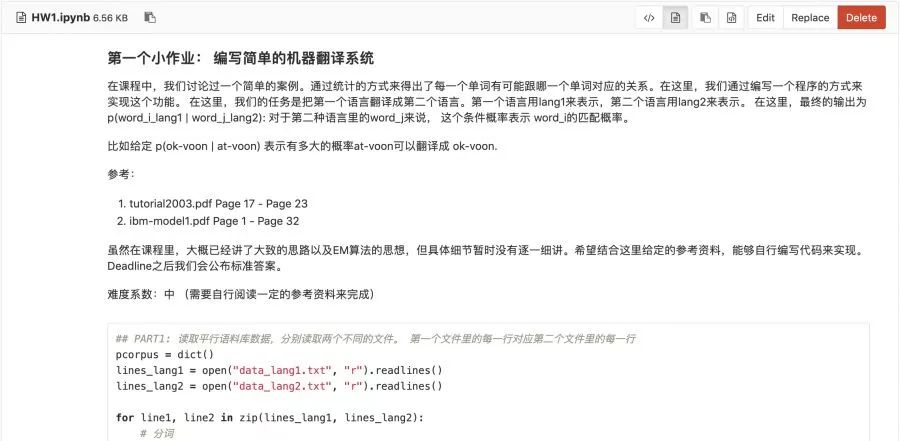
除了文章,算法工程师的立命根本--项目代码,
导师更是不会放过的。每次在Gitlab上布置的作业,导师们都会带领助教团队会予以详细的批改和反馈。并逼着你不断的优化!
![]() 。
。
3、品质保障!正式
开课后7天内,无条件全额退款。
对课程有意向的同学
添加课程顾问小姐姐微信
报名、课程咨询
👇👇👇
![]()






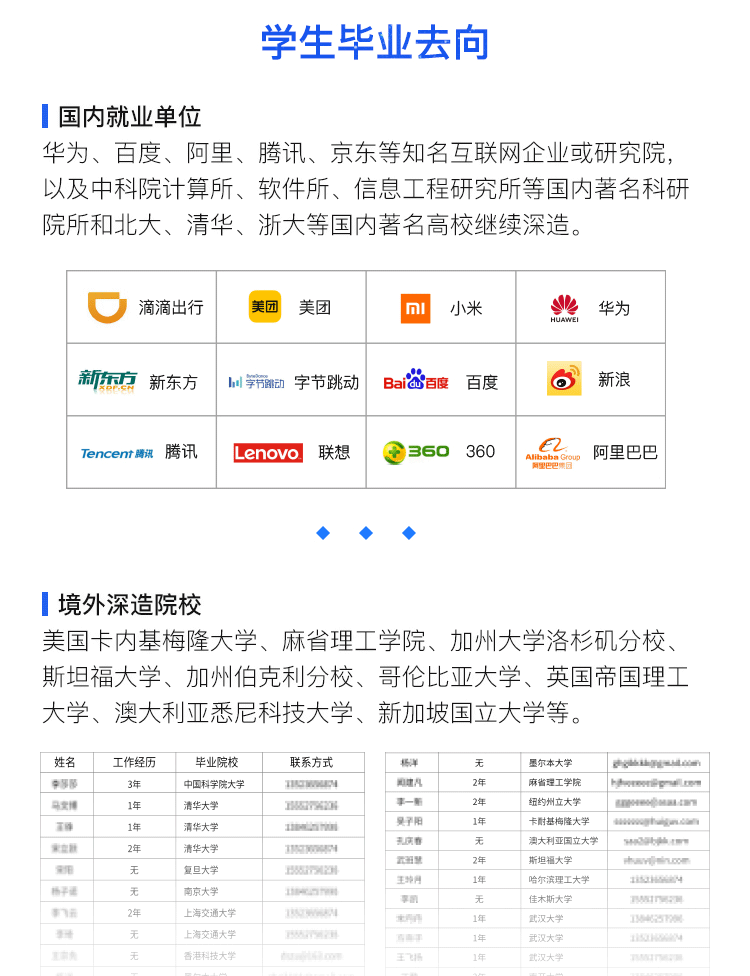 。
。





