MM2020 | 基于对抗学习的个性化标签推荐
嘿,记得给“机器学习与推荐算法”添加星标
本文分享一篇利用对抗学习的思路来进行个性化标签推荐的文章,其已经发表于2020年的ACM Multimedia(MM)会议上,MM会议是CCF推荐国际学术会议中计算机图形学与多媒体类别中的A类会议。

该文宏观的想法就是在为图片进行标签推荐(标签分类)的时候,不仅考虑了图片本身的视觉特征,同时还考虑了用户历史的偏好信息。更具体的,就是利用基于对抗学习的Encoder-Decoder框架来进行端到端的训练。值得注意的是,本文中所提到的两个小的技巧同样引起了我的注意,在此一并向大家进行分享。
动机
传统的多标签推荐问题只关注于图片的视觉特征,但往往不同的人看同一张图片时会有各自倾向的标签,因此本文在进行多标签推荐任务时,将用户的个人偏好信息建模其中。

更直观的说,下文中举了从YFCC100M数据集中提取出的图片,可见a和b图像,c和d图像在视觉观感上是相似的,但其匹配的标签却是不同的。因此,对于图片的标签推荐来说,涉及到用户、图像和标签三者的关系。传统的任务只考虑了图像和标签的关系,这就导致了标签的建模只依赖于图片的视觉特征。往往在为用户进行标签推荐的过程中,除了图像本身的视觉特征外,个人的偏好因素同样应该被建模其中。

贡献
-
本文提出了一个端到端的基于个人偏好和视觉特征的标签推荐框架,其通过无监督的训练方式基于带有残差的Encoder-Decoder来进行用户偏好特征的提取,然后结合视觉特征来共同进行标签推荐任务。 -
在进行标签推荐任务的过程中引入了对抗学习的机制来提高标签预测的性能,通过引入对抗训练,使得模型可以生成更加类似于人类标记的行为,以此学到更加鲁班的特征表示。 -
本文通过在YFCC100M和NUS-WIDE数据集上进行测试显示了其方法的优越性,同时通过消融实验验证了所提出组件的有效性。

相关工作
本文涉及到对抗学习相关的内容,因此大致总结下对抗学习在各个领域的发展。首先,Goodfellow于2014年提出了生成对抗网络(GAN)应用于视觉领域,其对抗博弈的思想成功的用在了样本生成任务上,生成器通过随机噪声来生成符合条件的样本以此来尽可能的骗过判别器,而判别器通过学习尽可能的识别生成器的造假行为,通过这样的对抗迭代训练,最终使得生成器生成与真实样本十分类似的样本,而判别器最后无法区分真假样本只能在0.5的置信度之间徘徊。当然GAN也存在一些有待解决的问题,比如模式塌陷的问题等。
随后,Goodfellow将对抗学习的思想用到了图像分类上,惊人的发现模型在分类的过程中很容易被对抗样本所欺骗,即在输入图像上添加微小但故意设计的噪声后模型就以较大的置信度识别出错误分类。因此,为了缓解模型的鲁棒性问题,其将对抗训练思想引入图像分类任务中,即首先最大化分类损失寻找对抗样本,然后最小化损失来优化普通样本和对抗样本,以此来提高模型的泛化性能与鲁棒性。
再随后,人们将此想法应用到了自然语言处理领域。自然语言处理领域的句子/短语与计算机视觉领域的图像的不同在于,图像的输入空间是1-255的连续数值,而句子或者短语是离散形式存在的,所以人们不再像图像领域那样在输入样本上进行求导获取对抗样本,而是在句子以及短语的替代表示-Embedding上进行添加扰动获取对抗样本,以此来提高短语的鲁棒表示。
推荐系统领域也是如此,其借鉴了自然语言处理领域不在原始离散的词语表示上进行对抗扰动的做法,也在用户/项目的Embedding上进行对抗扰动来提高模型的鲁棒性。

模型结构
本文的模型结构主要分为三个组件,①用户偏好建模;②视觉特征建模;③个性化标签推荐建模。通过三个组件联合优化最终达到端到端优化的目的,输入一张图像以及该用户的历史标签记录,通过用户偏好组件抽取的用户特征以及视觉编码组件抽取的视觉特征进行拼接,然后送入个性化标签分类器,最终依靠Cross-entropy loss、Adversarial loss、Discriminator loss以及Personalized loss来进行模型的参数学习。接下来将对三个组件一一进行介绍。
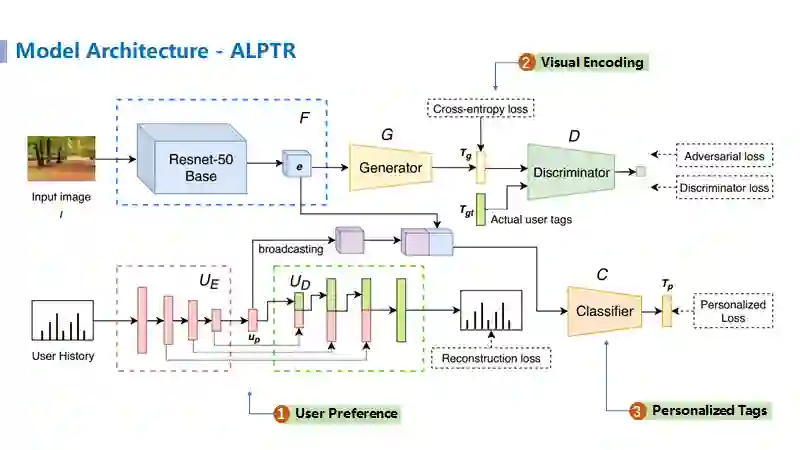
1. 用户偏好建模
用户偏好建模方面(标黄部分)是采用的无监督学习的方式来重构用户的历史标签记录,利用Encoder-Decoder框架来进行表示学习。在此主要有2个创新点供我们学习和借鉴,其一是在Encoder-Decoder框架基础上引入了残差模型;其二是采用了HUber loss。这两个创新点都是为了学到更好的用户特征表示。

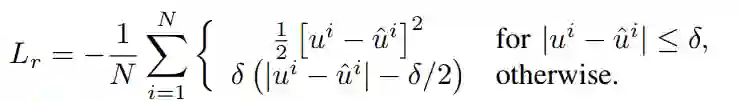
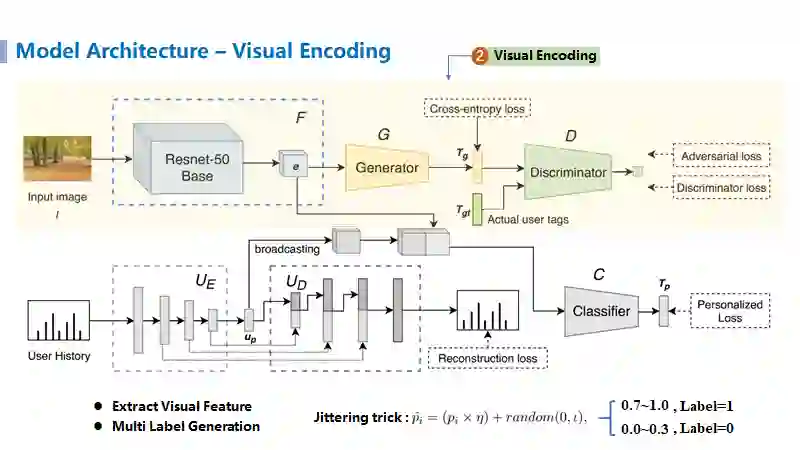
2. 视觉特征建模
视觉特征建模方面(下图标黄部分)主要采用了视觉主流模型Resnet来进行特征抽取,随后将得到的视觉特征
与用户低维表示
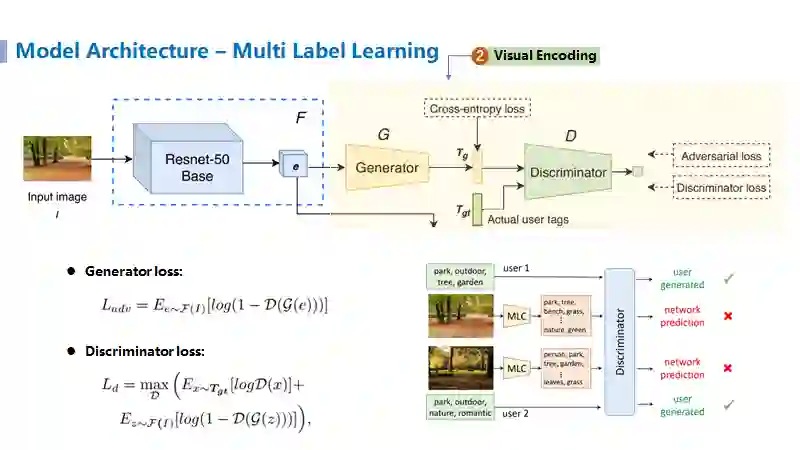
拼接后送给个性化推荐分类器进行最终的分类任务。其中视觉特征建模部分为了学到更类似于人类打标签行为的模式,提出了基于对抗学习的标签分类方法,即将生成器
生成的标签
与人工标注的标签
送给判别器
来进行区分以此学到更强大的判别器,随后生成器
通过模拟人工标签的习惯来尽可能的骗过判别器以此来学习更强大的生成器,最终使得学到的特征更加符合人工的行为习惯,同时可利用生成器来生成近似于人打标签行为的数据。在此,由于生成器生成的标签是0到1之间连续的数值,而人工真实标注的标签是非0即1的离散值,因此判别器很容易将其区分开。为了缓解这样的情况,作者利用了Jittering trick,即对人工的标签进行随机化,使得原来是1的标签现在变为0.7到1之间的实数,原来是0的标签现在变为0到0.3的实数,这样使得判别器尽可能的学习真实的用户行为还是机器行为,而不是简单的通过判断数据的形式来进行分类了。
视觉特征建模部分的对抗学习方式主要是由generator loss和discriminator loss组成,即generator loss尽可能使得生成器骗过判别器(即将生成器生成的标签尽可能的识别为真正的用户标签),而discriminator loss则尽可能的识别出该标签是机器生成的还是用户真实标注的,最终达到生成器能够生成类似于人工标注的图片,而判别器无法正确做出区分。
3. 个性化标签推荐建模
个性化标签推荐建模方面(下图标黄部分)主要采用了交叉熵损失来进行训练。

实验部分
下图列举了文中所对比的方法,以及所用数据集和评价指标。

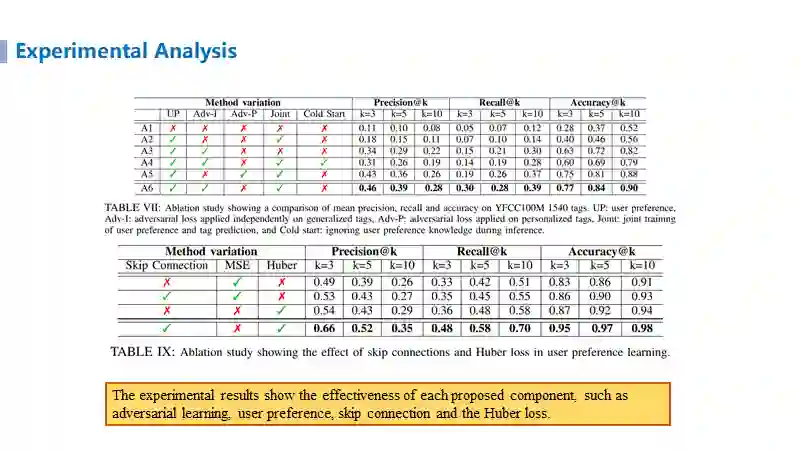
可见,本文所提出的方法在多个数据集上以及评价指标上都是最优的性能。

文中做了消融实验,证明了所提出的Skip Connection以及Huber loss确实起到了积极作用。并且还探索了对抗训练增加的方式以及冷启动的实验效果。
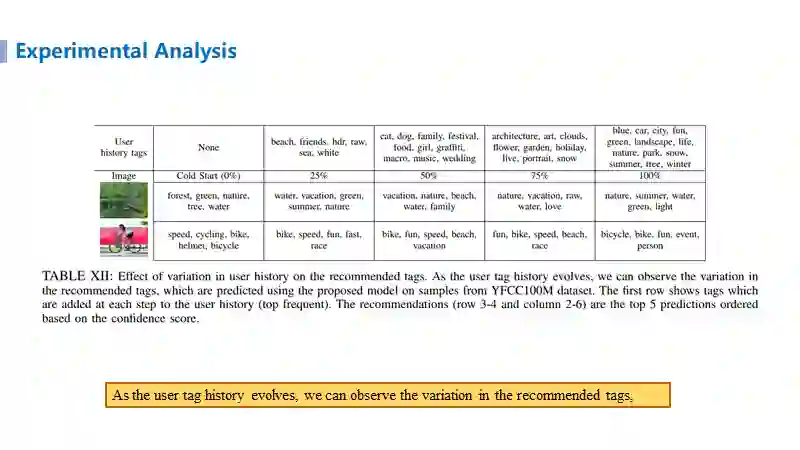
通过对用户历史标签的变化进行模拟,可见该方法随着用户历史标签的变化,给对应用户所见到的图片推荐的标签也随着时间变化(标签的变化)而产生了相应的变化,证明了所提出方法能够捕捉用户的标签行为偏好演变。
讨论
-
个人觉得本文最重要的创新是提出一种结合视觉特征抽取与个人偏好的多标签推荐算法,较好的将打标签问题建模为了特征提取与偏好学习的问题,使得对于同一副图像能够标记出个性化的多标签内容。
-
第二个值得关注的创新点是多标记生成问题,以往的多标签是人工进行标注,但常常会存在千差万别的情况,因此本文利用对抗学习的思想利用机器学习模型来学习用户真实的偏好,以此来解放宝贵的标记时间。
-
第三个比较吸引我的点是该文利用了许多巧妙的小技巧来提升训练精度。比如文中提到的Jittering trick 和Huber loss,可谓是simple yet effective。
-
最后想说本文关于多标记生成过程中的扩展想法,目前在生成的时候没有考虑标记之间的关系,未来可以引入标签关联矩阵来进一步的提高生成性能。


