论文:Dual Graph enhanced Embedding Neural Network for CTR Prediction
下载地址:https://www.zhuanzhi.ai/paper/1f510f5593c680c7d1db10a9bc634a3f
来源“图与推荐”
1. 背景介绍
基于特征交互建模和基于用户兴趣挖掘的方法是两种最流行的方法,已被广泛探索多年,并在点击率预测方面取得了很大进展。
然而,基于特征交互的方法严重依赖于不同特征的共现,可能会遇到特征稀疏问题; 基于用户兴趣挖掘的方法,需要丰富的用户行为来获取用户的多样化兴趣,容易遇到行为稀疏问题。
为了解决这些问题,原文提出了一个新的模块命名为 Dual Graph Enhanced Embedding,以分治法(
divide-and-conquer) 和课程学习(curriculum-learning) 的思路来改进 Embedding 的初始化以及表征学习 ,配合使用各种 CTR 预测模型来缓解这两个问题。
2. 方法介绍
推荐系统中一条样本包括 用户(
)、商品(
)、用户属性(
)、商品属性(
)、用户点击过的商品序列(
)、背景信息(
) 6个部分。
一个 ctr 模型的训练一般分为三个阶段:初始化 Embedding,表征学习(representation learning),模型训练和预估。
在初始化 Embedding 阶段,对上述特征进行向量化,向量化后的样本为
传统的方法这一步往往采用简单的随机初始化,会受到特征稀疏和行为稀疏问题的影响。在表征学习阶段,会对特征进行变换,产生新的特征。变换方式比如 FFM 中的特征交叉等。在模型训练阶段,将表征学习的输出作为输入放入接入全连接层
。
原文重点关注
初始化和
表征学习阶段的优化,原作者认为,在
初始化阶段可以通过 user-user 和 item-item 的相似关系,对每个属性域中的属性特征
和
进行调整,以减轻数据稀疏问题造成的影响。在
表征学习阶段阶段,可以进一步利用图关系中 user-user, item-item, user-item 的联系,对用户特征和商品特征进行交叉,进而对用户特征
,商品特征
,和点击序列特征
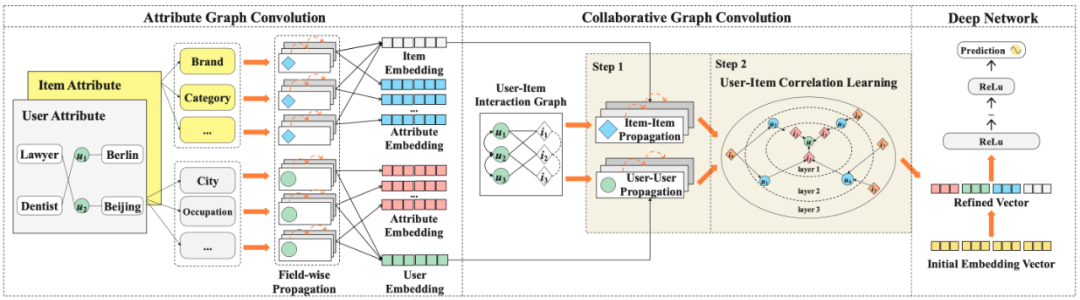
进行调整,流程如下图。
![]()
构图主要是用户和商品的属性图和三个协同过滤图,分别是
user-user 图、item-item 图、user-item图。
用户属性图由用户节点 U、属性节点 A、以及他们之间的边
组
成,记为
,商品属性图由商品节点
、属性节点
、以及他们之间的边
组成 ,记为
。
其中,
代表用户 i 的用户-商品交互向量(点击为1,否则为0),
代表用户 i 的属性。原文中取
,即两个用户的相似度由用户的历史行为和属性共同决定。计算完相似度之后,对每个用户取相似度最大的 k 个邻居,建立 u-u 网络
。
item-item 图
基于用户的行为,如果两个商品被同一个用户相继点击,则认为这两个商品相连,使用的是类似 Itemcf 的算法来计算相似商品,建立 v-v 网络
。
将上面的
user-user 图、
item-item 图,结合用户-商品交互矩阵
( 即当用户点击该商品时
为 1,否则为 0) ,得到 user-item 协同过滤图
。
2.2 属性图优化
属性图主要用来解决特征稀疏性问题。
用户属性图的优化基于
相似用户的属性也相似
的假设。对每个属性节点 h,都使用该用户的 user-user 图中的邻居用户的对应属性节点对其调整。这里的属性信息,其实已经是 embedding 的形式,将邻居节点的属性 embedding 放入 aggregator,计算得出该节点属性的 embedding。这里主要考察了三种 aggregator:GCN,NGCF,LightGCN。其中 LightGCN 被证明效果最好且效率最高:
其中
,是归一化参数。
为节点 h 的邻居节点,其实就是每一个节点的下一层的 embedding 都由它的邻居节点在本层的 embedding 加权得到。如果进行
层的迭代,则对每一个节点,最后有
个 embedding,将所有 embedding 的平均值作为输出:
在进行属性图的优化计算的时候,原文认为,不同的属性的数据特征有较大的差别,比如商品价格和商品类目不论在含义上和在数据分布上都有较大区别,不应被一概而论。因此,原文提出使用分治法,先对同一个域内的属性特征进行学习,再将不同域的学习结果合并。
协同过滤图主要用来解决行为稀疏性问题。
由于协同过滤部分是由三张子图 (i.e., user-user, item-item, user-item) 合并在一起的大图,在优化的时候,图中的边多且复杂,直接在整个大图中进行搜索效率较低。原文利用
课程学习
的思想,对 user-user 子图和 item-item 子图先分别进行学习,最后再对 user-item 边进行学习。
在 user-user 图内学习时,仍然采用前面提到的 aggregator 进行节点间的迭代,每一层的迭代公式如下:
其中,
函数即为上面提到的 GCN,NGCF,LightGCN 其中之一。事实上,采用的就是最简单的 LightGCN。
和
即为属性图优化的输出
。item 图的优化过程类似,最终将每层的输出取平均得到修正过的 user embedding
和 item embedding
:
因此,在这个阶段,更新过的样本为:
其中,除了
外的向量都被更新了。
在对 user-item 的关系进行学习时,输入改为上面两个图的输出 embedding,用户 u 的邻居节点
也从上面定义的「相似用户」变为了「被该用户点击过的商品」,其他方法类似,迭代公式如下
其中
,依然是对所有层的 embedding 取平均
同样的,对于商品节点得到
因此,最终输入深度学习网络的向量化样本被更新为
3. 实验
3.1 实验设置
![]()
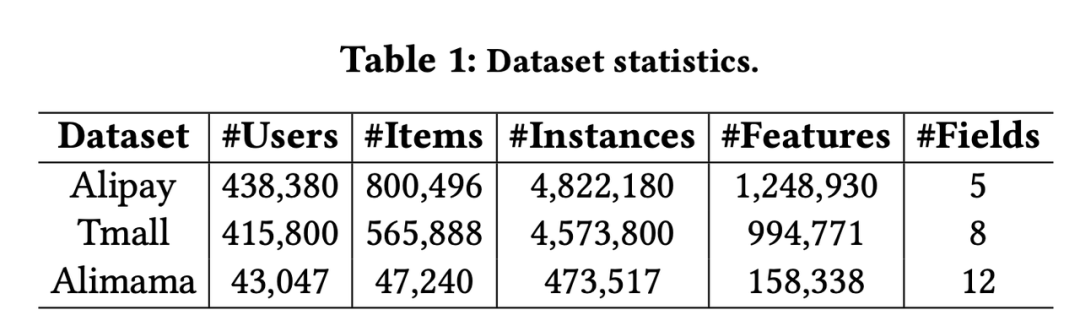
数据集为 Alipay,Tmall,Alimama 三个公开数据集。
数据集的划分处理如下:假设用户有
个历史点击行为,则
训练集样本:
,标签:
校验集样本:
,标签:
测试集样本:
,标签:
另外使用随机负例生成10个该用户没点击过的负样本。
参数设置
Embedding dimension: 10Batch size: 2000Learning rate: {1e-1, 1e-2, 1e-3, 1e-4}L2: {0,1e-1, 1e-2, 1e-3, 1e-4, 1e-5}Dropout ratio: [0, 0.9]Deep layers: [400, 400, 400, 1]Optimizer: AdamGCN layer: {1,2,3,4}
3.2 基线
对比 LR、FM、AutoInt、DeepFM、PNN、DIN、DIEM、GIN、FiGNN 等模型。
3.3 实验结果
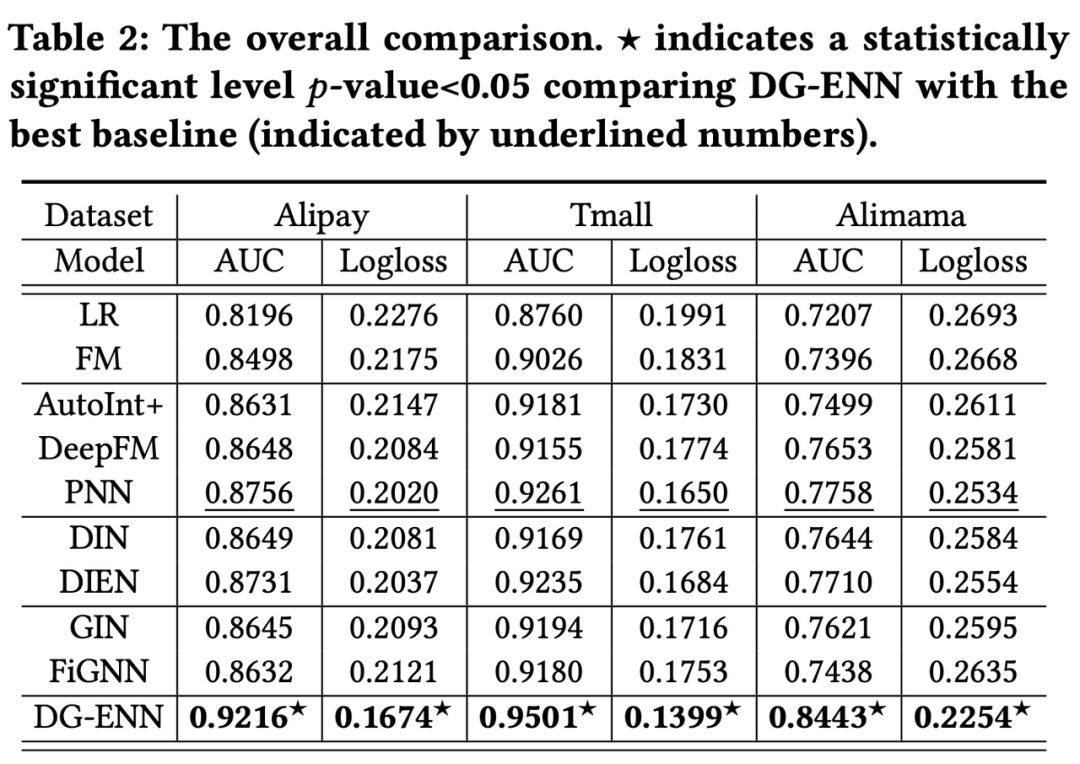
整体实验结论,由 Table 2 可见,DG-ENN 对比结果最好的 PNN 在三个数据集上 AUC 分别提升 5.25%,2.59% ,8.83%。而从 Table 1 来看,效果提升最明显的 Alimama 数据集似乎存在更严重的数据稀疏性问题。
![]()
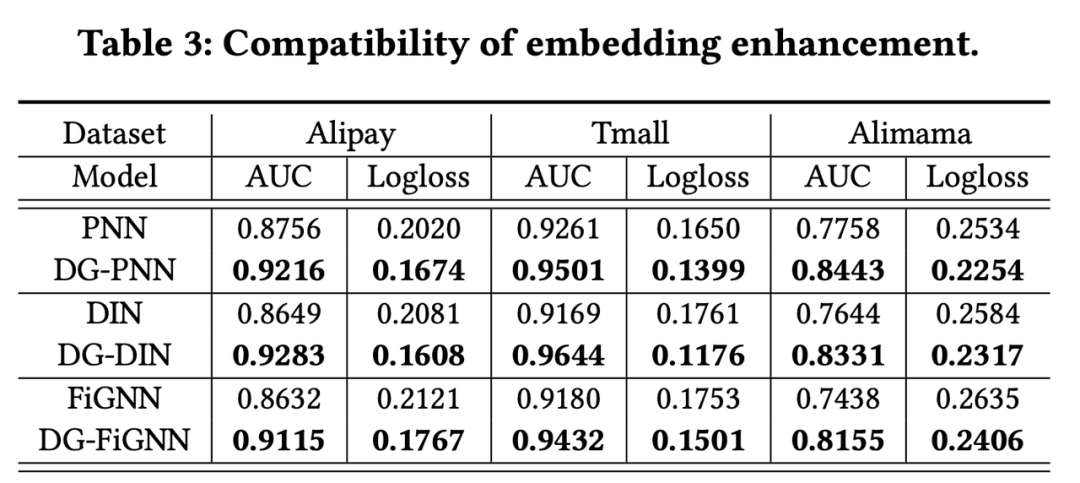
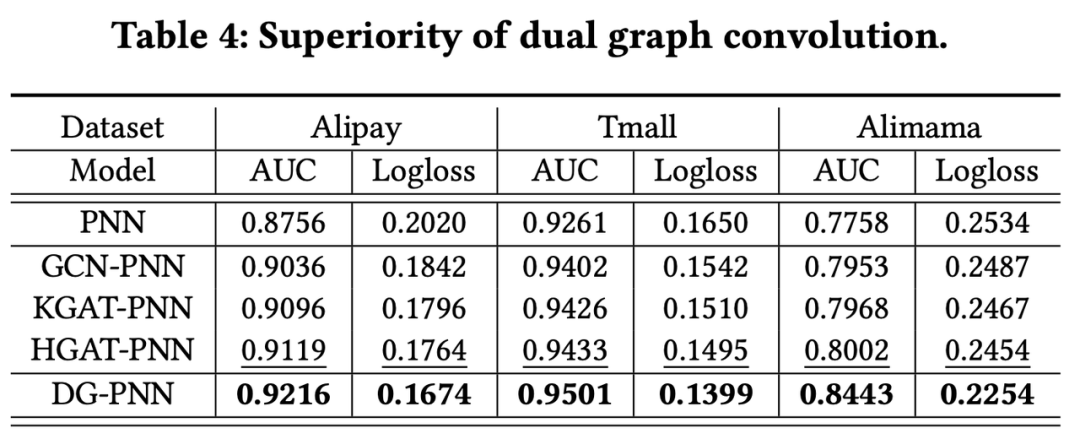
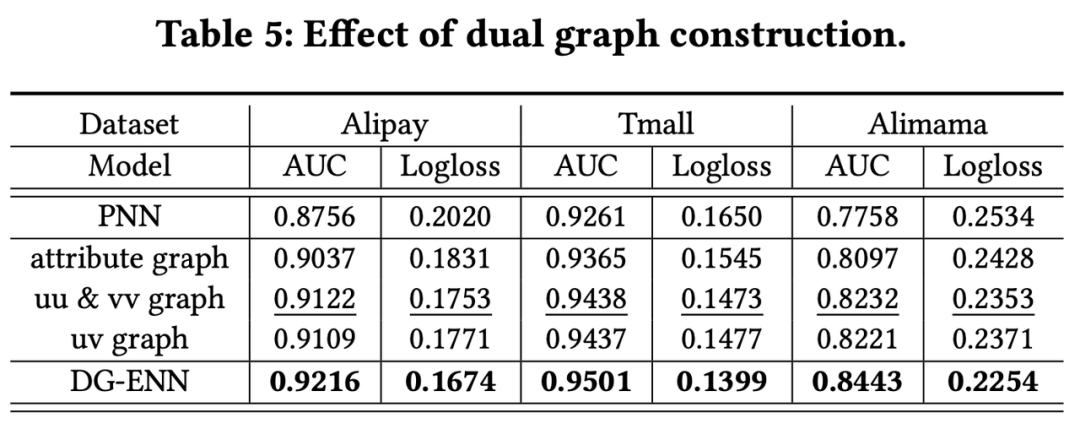
为了证明 DG-ENN 每一部分的必要性,原文还分别对以下三个问题做了消融实验:1. 对不同模型进行 dual-graph embedding 的优化是否总是有效?2. 原文提出的 dual-graph 方式是否优于其他的图优化方式?3. Dual-graph 中的每一部分是否都是必要的?
对于问题1 ,原作者认为 CTR模型主要分为三类:1.特征交互类模型如 LR,FM,DeepFM,PNN,AutoINT+;2. 用户兴趣类模型如 DIN,DIEN;3. GNN类模型如GIN,FiGNN。作者分别选取了这三类模型中的代表模型,对比实验了加入DG embedding 优化和不加的效果,在三类模型上,使用修正过的 embedding 总是优于原始的 embedding,结果见 Table 3。
![]()
对于问题2,
对比了 GCN, KGAT, HGAT 等其他的方式,效果更优,结果见 Table 4。
![]()
对于问题3,原
文涉及到属性图、协同过滤图,协同过滤图中又有 u-u, u-v, v-v 三种关系。作者想要验证是否这些关系都是有用的,所以进行了下面5组实验,分别是:
什么图关系都不使用,即PNN
只使用 attribute graph
只使用 u-u 和 v-v 关系
只使用 u-v 关系
全部关系都使用
结果如 Table5 所示,所有关系都是有用的,其中 uu&vv 关系单独对效果的提升最明显。
![]()
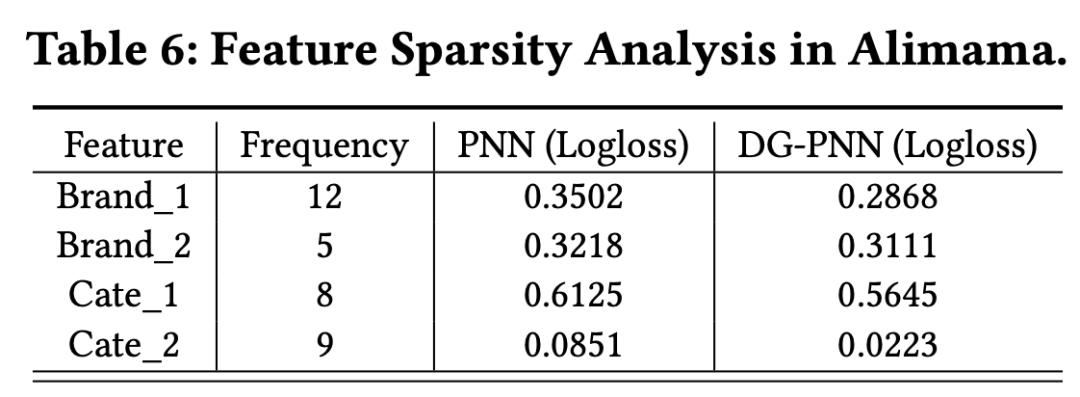
最后,为了验证本方法确实改善了
特征稀疏问题和行为稀疏问题
,原
文分别对特征稀疏和行为稀疏的两个具体例子进行了分析。
选取了 Alimama 数据中特征稀疏问题较严重的四个特征,对比了 PNN 结构和 DG-PNN 结构得到的 logloss。如 Table 6 所示,
DG-PNN 减小了这些稀疏特征的 loss。
![]()
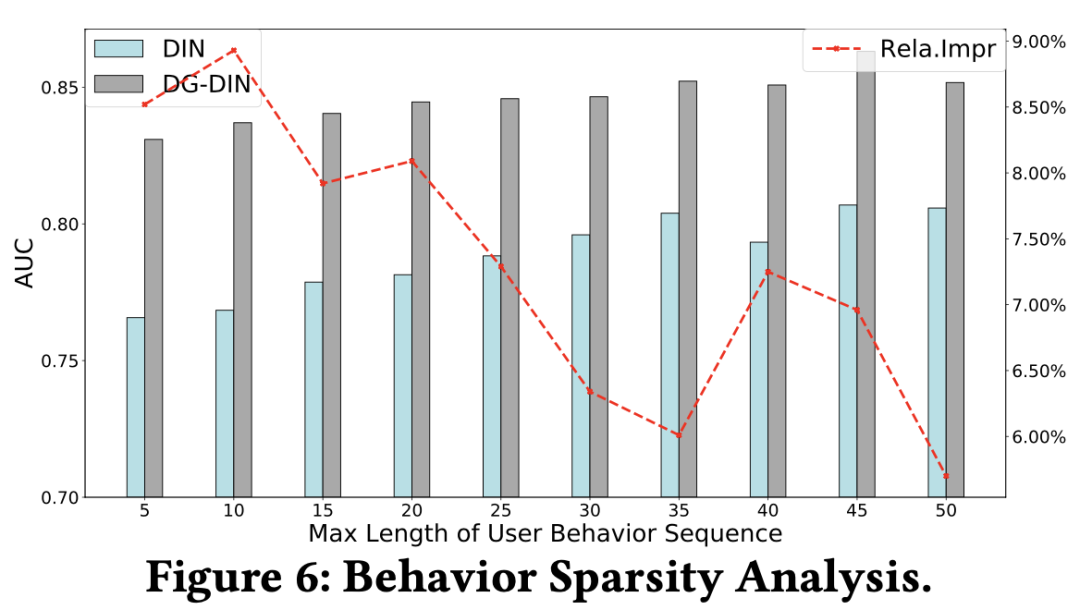
选取了特征稀疏问题较轻的 Alipay 数据,以减轻特征稀疏问题对分析行为稀疏问题产生的干扰。对比了 DIN 结构和 DG-DIN 结构在不同长度的用户行为序列上的结果。如Figure 6所示,
用户的行为序列越短(行为稀疏问题越严重),则 DG-DIN 结构的优势越明显
。
![]()
4. 创新点
在图建模的过程中,将建模分阶段为属性图和协同过滤图两个阶段,同时对协同过滤图建模时
以分治法
和课程学习的思路来改进 Embedding 的初始化以及表征学习,多阶段逐步对 Graph embedding 进行优化。
5. 点评
方法比较有意思,但是实际操作中仍有若干难点:比如配合CTR模型做 Online Learning 时,动态增加 user 和 item 时,图的更新代价很高,较难配合实时增量训练。
同时在实验的对比上有不公平之处:Graph 的增强实际上是一个预训练的过程,弥补了特征工程在建模中的缺失,同时所使用的总计算资源要远远高于对比基线,而对比的数据集是未经特征工程的数据,在经过一定程度特征工程的数据集上的效果未必一致。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源