利用磁共振成像数据估测脑年龄
文 / SimonJégou
医疗保健行业对人工智能 (AI) 的潜在优势抱有殷切期待。医生和医学研究员无法一夕之间成为程序员或数据科学家,亦不会为其所取代。但他们需要了解 AI 的实际含义及工作原理。同样地,数据科学家需要与医生开展密切合作,从而聚焦相关医学问题并了解数据背后的患者。
本案例研究旨在通过提供有关如何将机器学习应用于特定医学用例的见解,将两方受众(医生/医务人员和数据科学家)联系起来。我们将带您了解我们方法的推理过程,并与您携手开展实践(通过 Colab 笔记本),重点了解应用机器学习模型背后的机制。
注:Colab 笔记本 链接
https://colab.research.google.com/drive/1SWUcKT6bJLaTlxVLMvjHgLOD7Rdy3MQY#scrollTo=emyzNaHln9qa&forceEdit=true&offline=true&sandboxMode=true
我们的实验重点是创建和比较日益复杂的算法,并根据磁共振成像 (MRI) 数据成功估测大脑的生理年龄。基于此实验,我们提出这种影像生物标记对于了解阿兹海默症等神经退行性疾病的影响。

通过确定必要的输入值 (X) 和输出值 (Y) 来设计用于机器学习的有趣医学问题并非易事,但以下部分示例可供您作为参考:
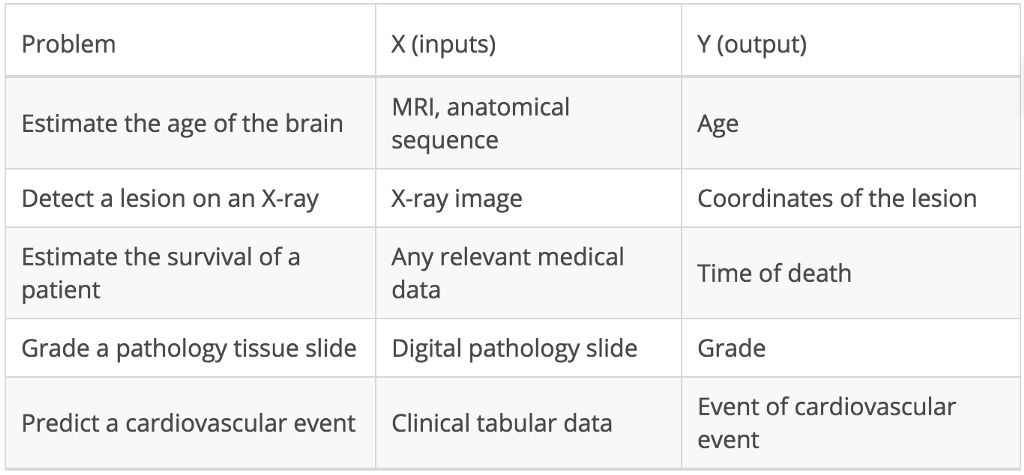
医学问题被设计成监督式机器学习问题
面对这类问题时,无论 X 及 Y 值为何,数据科学家总是会采取相似的方法:
获取并清理数据
分析数据并提取与问题相关的特征
设计验证策略
针对数据训练算法、分析错误并解读结果
执行迭代,直到算法达到最优
注: 在本次工作中,我们使用的是 Python,机器学习领域最流行的编程语言之一。若您是新手,不妨执行 Colab 笔记本的前几行代码,以便大致了解其工作原理。
数据收集
在本项目中,我们使用两个来自健康受试者且公开、匿名的大脑 MRI 数据集。第一个数据集(数据集 A)收集自伦敦三家不同的医院,包含近 600 位受试者的数据。第二个数据集(数据集 B)包含来自美国、中国和德国 25 家医院超过 1,200 位受试者的数据。
注:数据集 A 链接
http://brain-development.org/ixi-dataset/
数据集 B 链接
http://fcon_1000.projects.nitrc.org/fcpClassic/FcpTable.html
注:这部分工作对我们而言比较轻松,因为我们所使用的图像数据集之前便已完成收集和精选,而且从法律和监管角度而言,这些数据集也可供使用。不同于电子健康记录、基因组学数据或数字病理学,医学影像还能享受 DICOM 标准格式带来的好处。然而,对医生和研究员而言,医学数据集的编译通常是最为困难和耗时的任务,编译几百位患者的数据一般需要耗时数月。
与所有数据科学项目一样,本项目也从数据清理开始。而这会带来一些麻烦:ID 问题、工作表中的行数据丢失、质量图像低等。 这类错误在医学数据集中屡见不鲜。
之后,我们从数据集 A 中获得 563 位 “干净的” 受试者(共 600 位,占比 94%),从数据集 B 中获得 1034 位 “干净的” 受试者(共 1,200 位,占比 86%)。我们是在 Colab 笔记本中捕获该数据。我们在同类群组中观察到以下人口统计数据:55% 是女性,最小的 18 岁,最大的 87 岁,四分位数为 22、27 和 48。
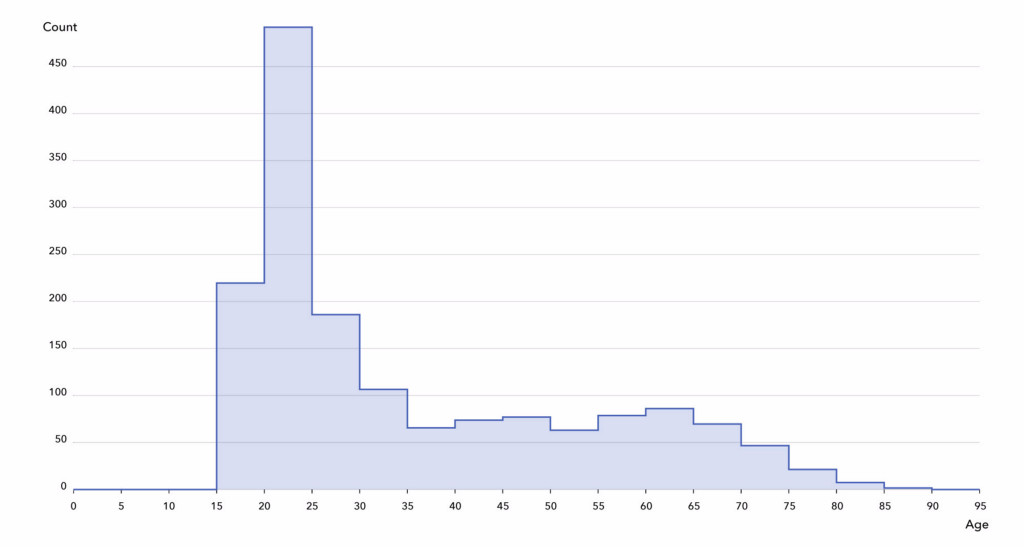
1597 位受试者的年龄分布直方图(从中可看出,研究员更偏向选择年轻受试者)
数据预处理
为把握问题的复杂度,我们定义了一个简单的基线算法。我们决定不使用整个 3D MRI,而是用体素强度直方图更为简单地反映其内容。下方所示便是一种典型的 T1-MRI 直方图(您可以在 Colab 笔记本中自行构建直方图)。
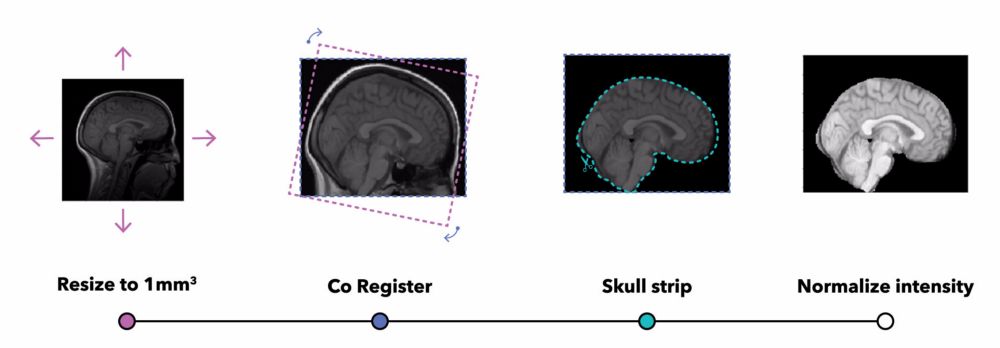
MRI 预处理管道
医生对脑衰老了解多少?
医生不可能单凭大脑图像确定受试者的精确年龄。然而,放射科医师至少了解三种与脑衰老相关的解剖特征,这在本项目所用的 MRI T1 序列中有所体现:
脑萎缩,灰质厚度减少(由于神经元丢失)
脑白质疏松,表现为白质低信号(由于血管老化)
脑室扩张,脑萎缩和脑脊液在脑室积聚的结果
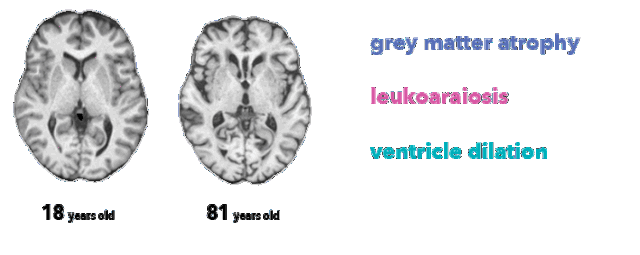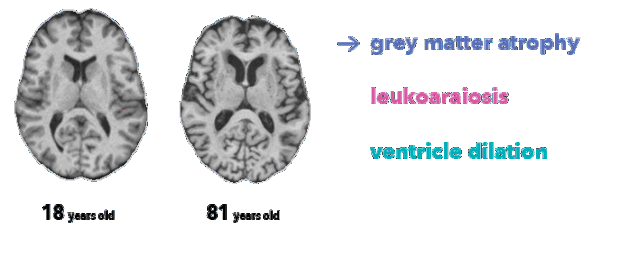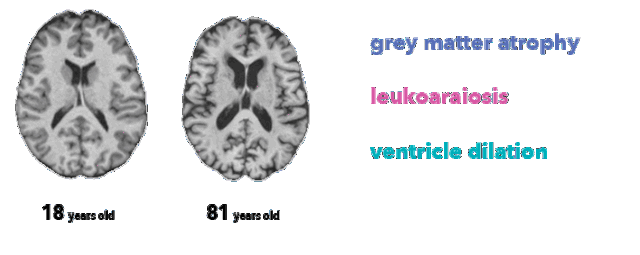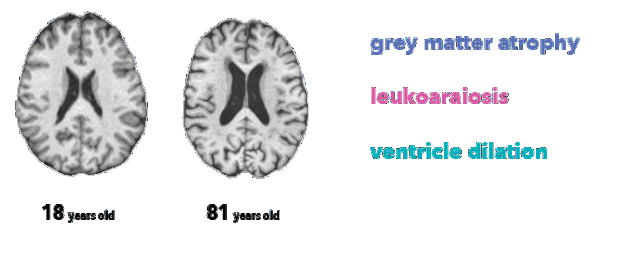
大脑生理年龄对比(突出显示特征)
一些研究员已针对通过解剖数据预测脑年龄,以及脑年龄与脑疾病或基因的关系进行研究。伦敦国王学院的研究员 James Cole 已就此主题撰写一系列优秀的论文(Cole 等,2017 这篇论文与我们的研究最为相似)。一项规模更大(针对约 37,000 位患者)的研究(Kaufmann 等,2018)目前正处于审查阶段,而这篇刊登在 《量子杂志》上的 文章 对以上两项研究进行充分介绍。
注:文章 链接
https://www.quantamagazine.org/functional-fingerprint-may-identify-brains-over-a-lifetime-20180816/

首先确定基线
为把握问题的复杂度,我们定义了一个简单的基线算法。我们决定不使用整个 3D MRI,而是用体素强度直方图更为简单地反映其内容。下方所示便是一种典型的 T1-MRI 直方图(您可以在 Colab 笔记本中自行构建直方图)。
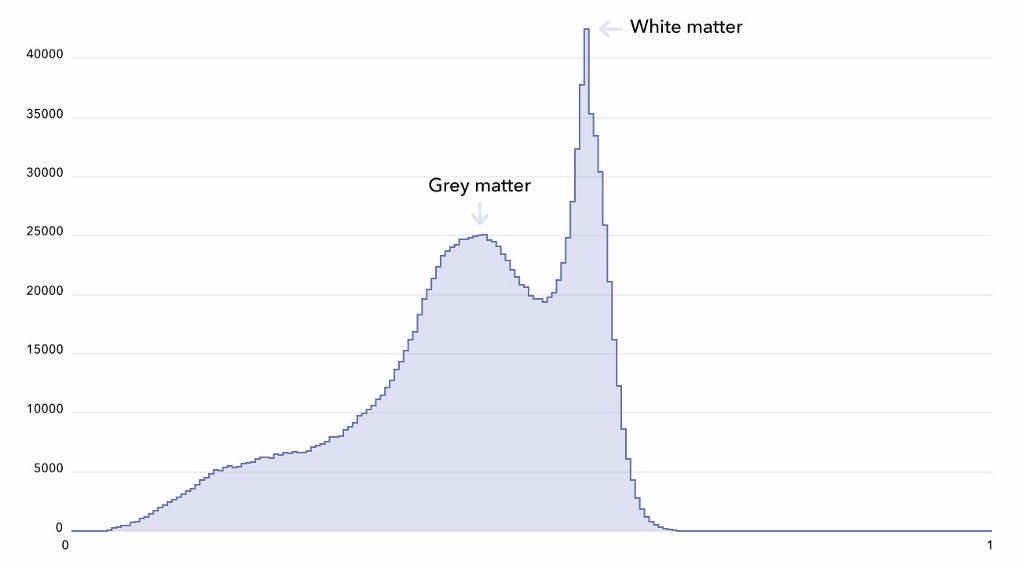
两个峰值对应灰质和白质。众所周知,脑衰老与灰质萎缩有关。那么,我们可以利用这种基本表征预测脑年龄吗?
针对这些直方图进行线性岭回归训练后,得出 9.08 年的平均绝对误差(使用 5 倍交叉验证,随机划分)。梯度提升树能产生更出色的结果,并将误差减少至 5.71 年,这一数字更接近于当前的最佳表现(Cole 等,2017 这篇论文中报告的 4.16 年)。达到最佳之后,我们不免会想停下脚步,但这却是犯了大错。遗憾的是,这种错误相当普遍。
重新审视交叉验证
MRI 中的体素强度范围没有生物学意义,并且在不同的 MRI 扫描仪之间存在较大差异。在交叉验证过程中,我们将受试者随机分为训练组和测试组。然而,如果随机化的对象并非受试者,而是医院(相当于随机划分 MRI 扫描仪),结果会如何?
按医院划分(附带约束条件是训练集的大小大致保持不变)之后,线性回归和梯度提升树模型的平均绝对误差便显著增加约 5 年和 6 年。
以下两张图表明,我们在仔细分析数据后便能避免这种错误。从第一张图中,您可以看出每家医院的年龄分布大相径庭:某些医院的数据集中只有年轻受试者,而其他医院只有老年受试者。
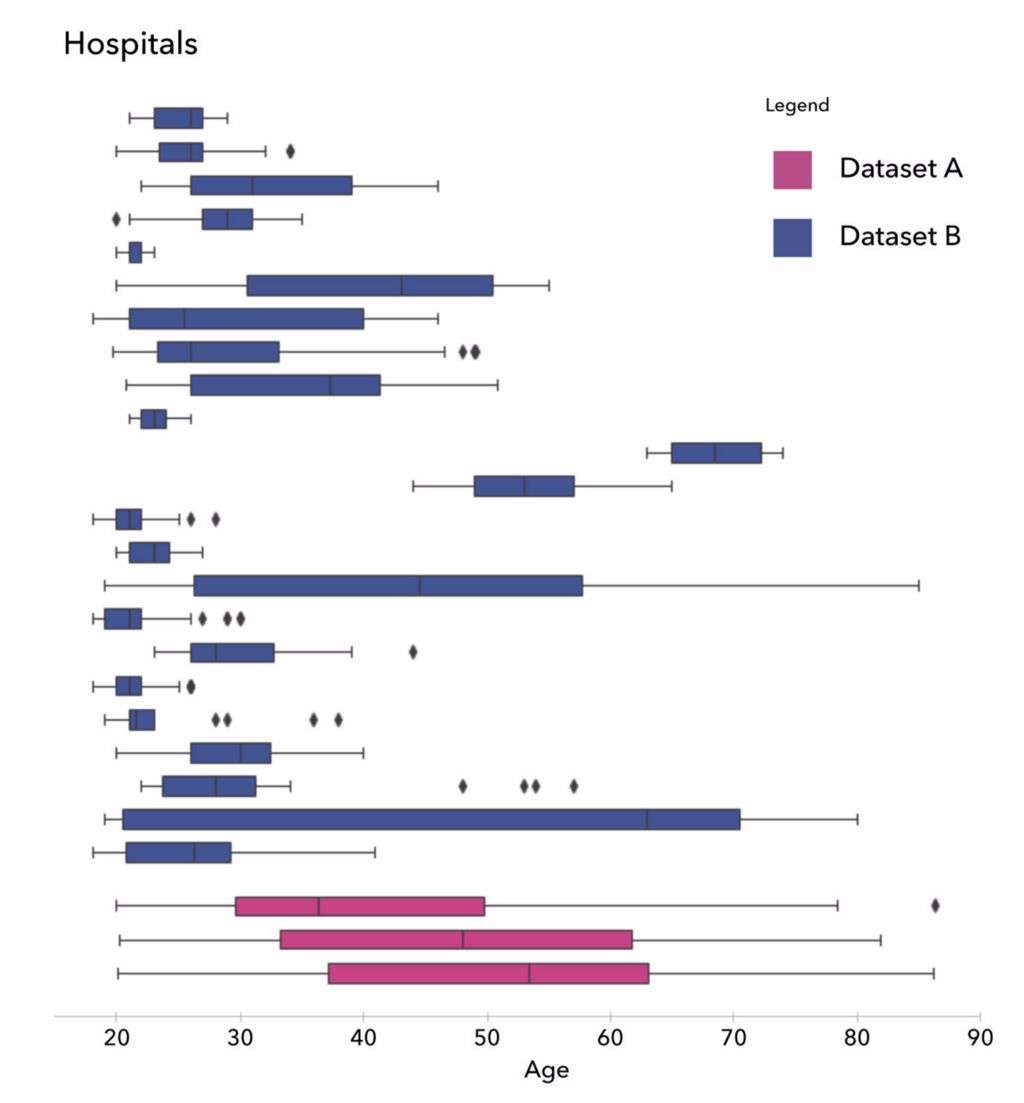
每家医院的年龄分布
在第二张图中,我们展示了每家医院受试者的平均直方图(左侧)并作出说明:虽然不同医院的白质峰值完全一致,但灰质峰值却分布广泛。这种不均匀性将产生算法可学习的偏差,并且可能会导致预测出错。为消除这种影响,我们使用自创的归一化方法来修正灰质峰值,如下图右侧所示:
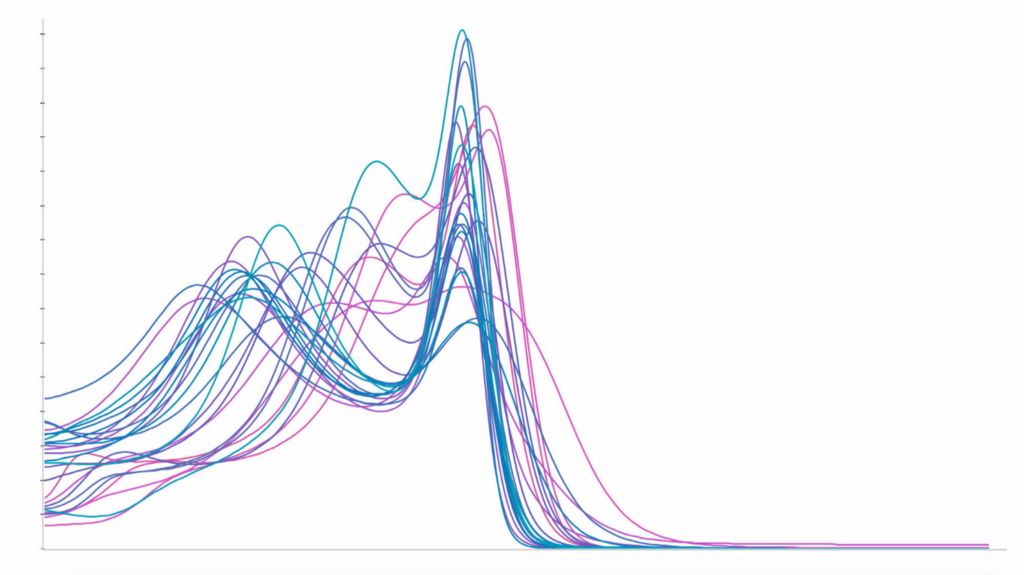
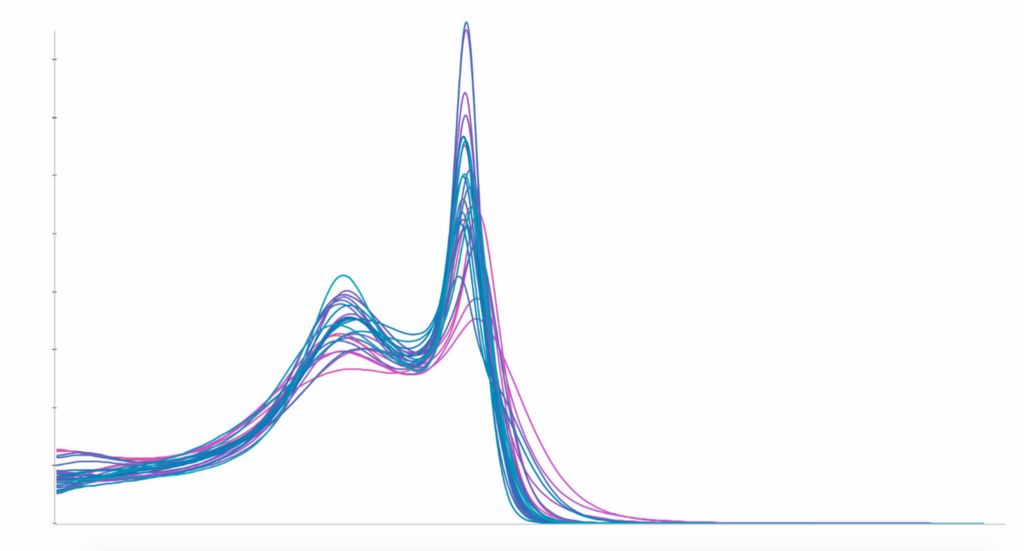
如大家所料,在实施完新的归一化方法后,随机交叉验证的误差增大,而医院交叉验证的误差减小,如下图所示:
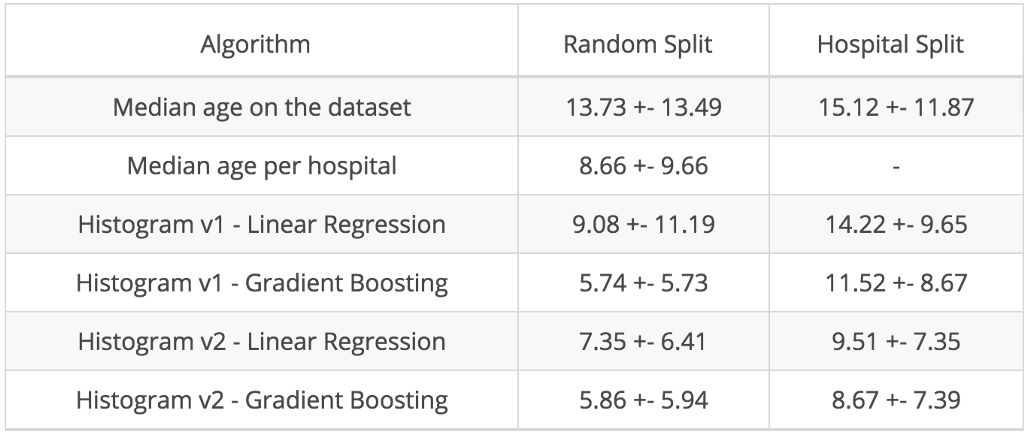
不同算法的平均绝对误差 (MAE) 和标准差(以年为单位)
本部分强调交叉验证必须经过仔细分层,以免引入混淆变量(如 MRI 扫描仪)。我们认为,验证算法的最佳做法是在外部和预期数据集上对其进行测试。从循证医学中推断真相存在一种瓶颈,即科学论文中的研究结果缺乏外部真实性。用机器学习的专业术语来说,这可能会导致算法缺乏 “普遍性”。医学中的 “证据等级” 概念允许针对同行评审论文中发布的给定结果,对其置信水平进行分级。而在现今的机器学习领域中,并没有这种等同概念。
利用组织分割更进一步
在将整个 MRI 简化为直方图时,我们忽略了关于脑结构的空间信息。为进一步提高算法的有效性和可解读性,我们使用另一种软件包 FSL FAST 将每个 MRI 分割为灰质、白质和脑脊液 (CSF)。本次分割以体素值为基础,且能够产生令人信服的结果(您可以在我们的 Colab 笔记本中对其进行研究)。
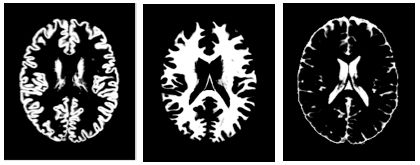
不同的脑组织分割掩膜。从左至右依次为灰质、白质和脑脊液 (CSF) 掩膜
在这些分割的基础上,我们观察到年龄与灰质总量之间的皮尔逊相关系数为负数(即 -0.75),证实了灰质萎缩的假设。接着,我们进一步计算了分割组织的局部量,并将其用作线性模型的输入值。通过这些专业特征,我们获得比简单直方图更出色的结果,如下图所示:
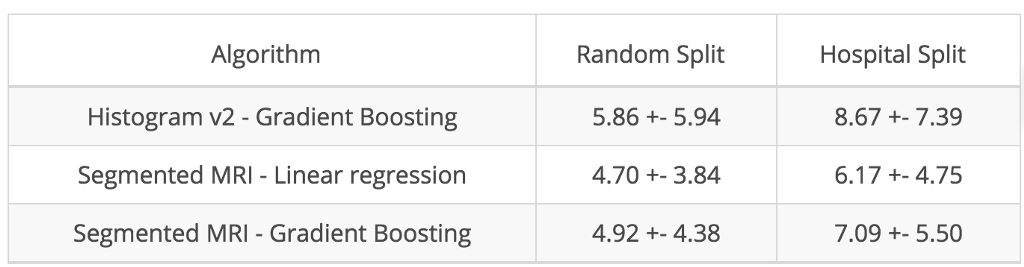
不同算法的平均绝对误差 (MAE) 和标准差(以年为单位)

我们先从 CNN 开始!
这是本次旅程的最后一站。到目前为止,我们是通过操控数据来提取自认为与年龄预测相关的特征。深度学习则采取另一种方法,并使用一系列称为卷积神经网络 (CNN) 的函数直接处理原始图像。这些函数无需人工指导,即可针对给定的任务识别最相关的特征。
在本次案例研究中,我们通过将每个 MRI 轴向维度的图像从 200 张减少至 10 张来简化问题。每张图像代表脑室级别 1 毫米的轴向区域,而我们可借此检测出萎缩、脑室扩张和脑白质疏松。我们设计出一种简单的 CNN(10 个卷积层,5 百万个参数),针对随机分割和医院分割,该网络产生的平均绝对误差分别为 4.57 年和 6.94 年。
然后,我们通过数据增强来改进模型。数据增强内容包括通过对数据集进行轻微变形模拟更多数据,以及通过旋转、缩放和改变像素强度产生微弱的失真效果。您可以在 Colab 笔记本中加载并使用这种经过训练的模型。
迁移学习是一种广泛使用的技术,可以对这种预训练的 CNN 进行微调,从而使其适应全新的任务。我们使用其中的一种 CNN (ResNet50),并在我们的数据集上对其进行微调。下图所示即为这些不同 CNN 架构的完整结果集:
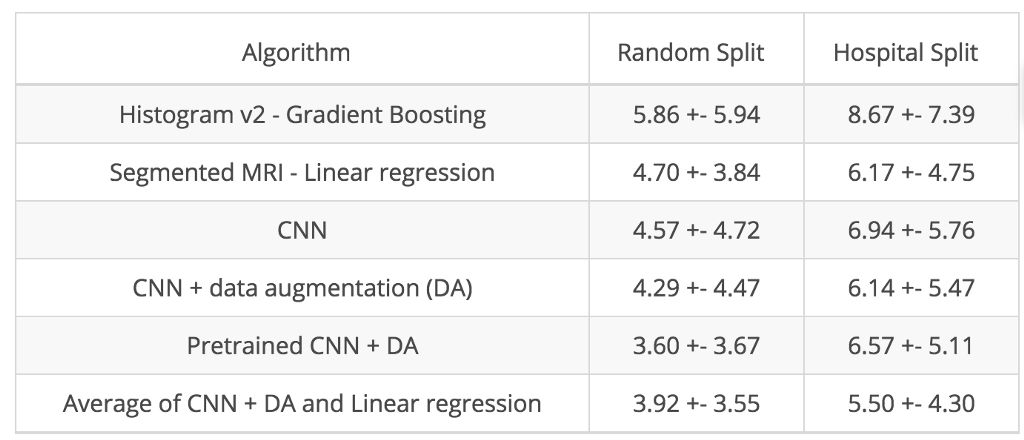
不同算法的平均绝对误差 (MAE) 和标准差(以年为单位)
实现最佳性能的集成方法
作为最后一项技巧,我们提取两种最优算法(采用数据增强的 CNN 和分割 MRI 上的线性模型)的平均预测值。集成方法可以媲美专家之间的合作,能够进一步提升性能,强调这两种不同模型的互补性。
在下表中,我们提供最终模型的更多指标。由于同类群组是年轻人(中间年龄为 27 岁),因此,我们的模型对年轻受试者而言比对老年受试者更可靠:
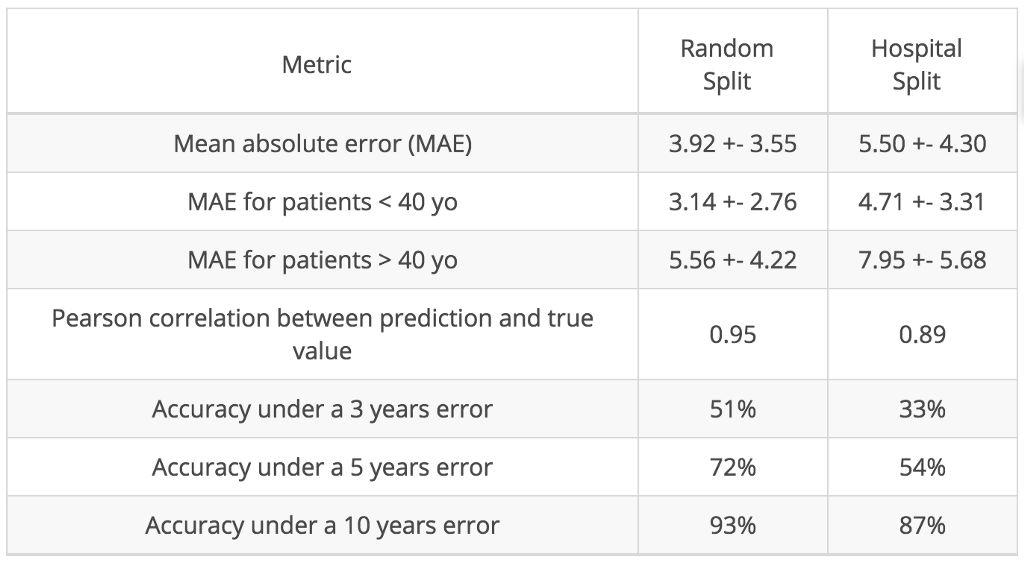
最终算法采用 5 倍交叉验证的平均性能
探查黑盒
性能指标可能会令人信服,但往往不足以产生信任感。如 CNN 这种带有数百万个参数的算法不仅令人费解,对试图了解幕后生物学的医生而言,也是令人沮丧的黑盒。
在首次了解黑盒时,我们使用了一种简单的遮挡技术。该想法是遮住测试集图像的小区域(此处为 4 平方厘米),并观察对应的平均绝对误差下降。如果性能显著下降,则说明遮住的区域对算法非常重要。在下图中,粉色区域与最大误差下降有关:
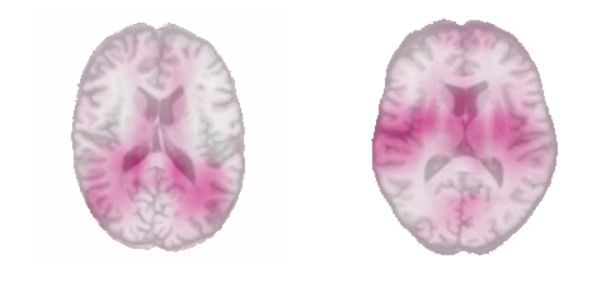
30 岁以下(左图)和 60 岁以上(右图)成年受试者的遮挡图
左图最年轻受试者的遮挡图表明:最靠近脑室的区域是预测中的重要区域。从科学角度来看,此结论成立。我们知道,年轻人的脑室是最薄的,因为它会随年龄的增长而扩张。对于年龄最大的受试者而言,其遮挡图揭示了两侧岛叶的重要性,这与 Good 等,2001 的研究结果一致。
这篇 博客 很好地总结了一些更成熟的技术,您可以借此了解深度学习算法。
注:博客 链接
http://blog.qure.ai/notes/deep-learning-visualization-gradient-based-methods
使用我们的模型来预测阿兹海默症
本次练习的实际应用是估测大脑的生理年龄,以便更好地了解阿兹海默症等神经退行性疾病。在这最后一个实验中,我们针对 ADNI 数据库中的 489 位受试者应用模型,受试者分为两类:正常对照组(269 位受试者)和阿兹海默症组(220 位受试者)。
接下来,我们下载数据、清理数据、通过我们的预处理管道传递数据,并应用经过训练的线性回归模型和 CNN 模型。相较于我们用来训练的数据集中患者的年龄(平均年龄 35 岁),该数据库中患者的年龄要大得多(平均年龄 75 岁)。正如大家所料,我们的模型一直低估了健康受试者的年龄。此失败案例凸显出机器学习模型的一个重要局限性:如果模型未针对具有代表性的人群样本进行训练,则其在针对看不见的受试者时便会表现糟糕。在医疗保健领域,医疗保健数据缺乏可移植性和非稳定性可能是使用机器学习最严重的障碍之一。
然而,在我们绘制记录的受试者年龄与使用最终算法预测的脑年龄之间的差异分布时,我们发现:阿兹海默症患者和健康受试者之间的平均差异为 6 年,这也符合 ROC-AUC 76% 的分数。这种结果往往能够证实,阿兹海默症受试者的脑部在某种程度上具有与加速脑衰老相关的特征(Gaser 等,2013),以及脑年龄可能成为神经退行性疾病新生物标记的假设(Rafel 等,2017、Koutsouleris 等,2014、Coleet 等,2015)。
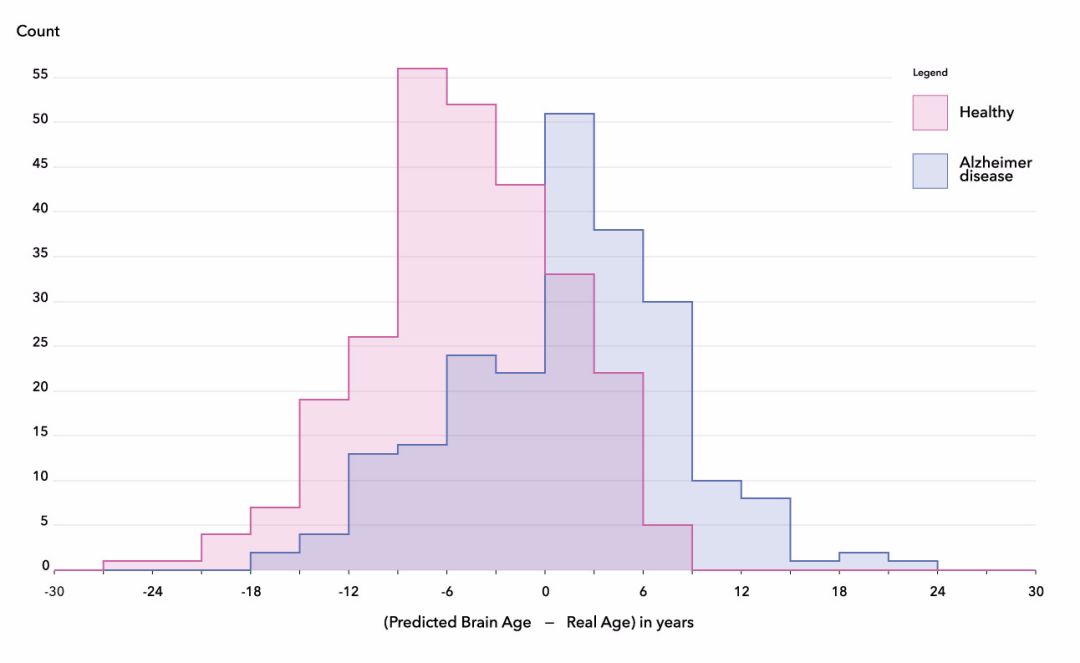
受试者预测年龄和记录年龄的差异分布(在 ADNI 数据库的 489 名患者中,正常对照组和阿兹海默症组之间的平均差异为 6 岁)
结论
在利用深度学习进行预测的过程中,部署简单的线性模型可能只需数秒,但构建用于训练的复杂 CNN 可能需耗费数日。在两种情况下,可解读性至关重要,尤其是在可发现新生物机制和生物标记的医学领域。
但是,实践者在构建和分析这些模型时必须谨慎小心。即使正确完成交叉验证的分层工作,有限用例上的卓越性能也无法保证出色的泛化能力。如果算法未针对具有代表性的人群样本进行训练,并且实践中时常出现偏差,那么这一结论便尤为适用。虽然从监管和组织的角度来看很困难,但投入时间收集和清理数据集却是机器学习项目成功的关键。我们希望您能通过本文,初步了解 AI 在应用到医学数据时的样子,以及需要避免的常见误区。
致谢
本次研究离不开 Owkin 团队以下几位成员的帮助:Simon Jégou*、Paul Herent*、Olivier Dehaene 和 Thomas Clozel。我们要感谢 Roger Stupp 博士、Julien Savatovsky 博士和 Olivier Elemento 博士的大力支持,Sylvain Toldo 和 Valentin Amé 在数据方面所做的工作,以及 Sebastian Schwarz、Eric Tramel、Cedric Whitney、Charlotte Paut 和 Malika Cantor 对手稿的编辑。如需查看本篇博文的完整内容,请点击 此处(https://medium.com/owkin/a-machine-learning-survival-kit-for-doctors-97982d69a375)
数据科学家 Simon Jégou:simon.jegou@owkin.com
放射科医师 Paul Herent:paul.herent@owkin.com
更多 AI 相关阅读:






