统计建模 | PLS-SEM模型的理论与应用:企业声誉模型
本学期给硕士生开设了结构方程式模型课程,主要讲解了AMOS进行结构方程式模型SEM的相关理论和软件操作,同时也讲解了PLS-SEM模型的新思路。

PLS-SEM模型更具预测性,是一种非常好的实证研究方法,特别适合进行理论和因果模型验证,也有了预测能力。当然也更适合新闻传播类相关理论的实证研究,适合撰写硕博论文。
下面是俺的两位硕士生对PLS-SEM模型的学习和总结:
定义:PLS-SEM模型:基于偏最小二乘法的方差分析方法,它是一种将主成分分析与多元回归结合起来的迭代估计,也是一种因果建模的方法。
SEM:结构方程式模型。PLS:偏最小二乘法
结构方程式模型
结构方程式模型(Structural Equation Modeling)是一种包含了回归分析、因子分析和方差分析等一系列多元分析方法的技术,它实际上是一种借助于假设检验进行多元分析的统计模型和方法。
在现实生活中,我们常常会想要探寻一系列行为之间是否存在关系,比如收入水平、情绪状况与消费水平之间的关系,那么SEM就为我们提供了一种途径:我们可以假定这三个行为之间的因果关系模型,并通过统计检验来证实这个模型是否成立。
然而,像“消费水平”这种概念是不能被直接测量的,我们称之为潜变量(Latent Variable)。但是,它却可以通过一系列的行为反映出来。比如“每周平均花费多少钱”、“每周逛街的次数”或者“常去的商场是高档、中档还是低档”等等,并且这些行为可以直接测量出来,我们就称之为观测变量(Observerd Variable)。
SEM的原理即假定在一组潜变量中存在因果关系,这些潜变量可以分别用一组观测变量表示。SEM中所假设的模型通常包括某个基本线性回归模型和很多观测变量,基本的线性回归模型即为一组潜变量的结构关系模型,而这一组潜变量分别是那些观测变量中的某几个的线性组合。从技术上,通过验证观测变量之间的协方差,可以估计出这个基本线性回归模型的系数值,从而在统计上检验所假设的模型是否合适。如果合适,则可以认为我们建构的关系模型是合理的。
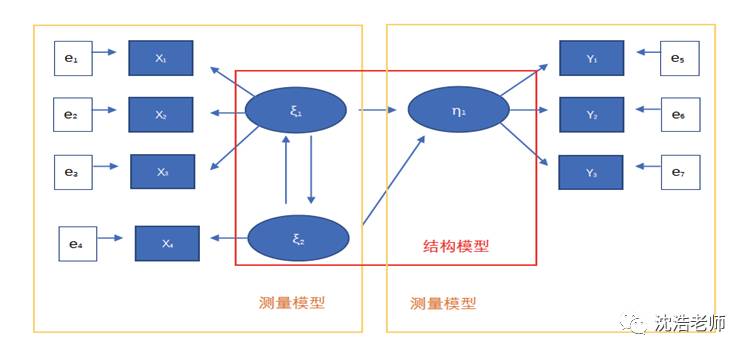
另外,在结构模型中,能够影响其他变量但是其自身的变量是由结构模型外部的因素所引起的变量,我们称为外生变量;而由外生变量和其他变量来影响的变量,我们称之为内生变量。
如图所示:其中,X1……X4、Y1……Y3表示观测变量,ξ1、ξ2是潜在的外生变量,η1是潜在的内生变量,e1……e7表示与观测变量相关的误差(error)项
PLS-SEM模型
什么是PLS-SEM模型
结构方程模型主要分为两大类,一种是基于最大似然估计的协方差结构分析方法,以LISREL(Analysis of Linear Structural Relationship)方法为代表,也就是上文所介绍的传统的SEM。另一种是
形成性指标和反映性指标的概念
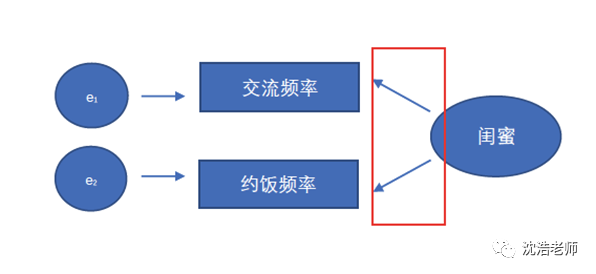
在传统的SEM中,观测变量与潜变量之间为线性函数关系,潜变量的意义通过观测变量反映,潜变量的变化会导致观测标量的变化。(X1表示观测变量,e1表示误差, ξ1表示潜变量,λ1表示系数)
可用公式:ξ1=λ1·X1+e1
这类模型就被称为反映性测量模型(Reflective Measurement Model),相应的观测变量即为反映性指标(Reflective Indicator)。举个例子:鉴定两个女生是否为闺蜜,就反映在她俩交流频率与约饭频率等方面。
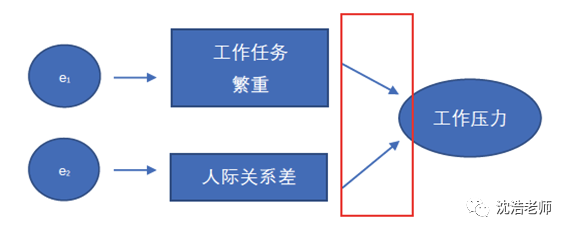
然而,有些时候,潜变量的意义是由测量变量来决定的,这一类测量模型就称为形成性测量模型(Formative Measurement Model),所对应的测量变量即为形成性指标(Formative Indicator)。举个例子:工作任务繁重,人际关系差等造成了工作压力。
PLS-SEM建模的优点
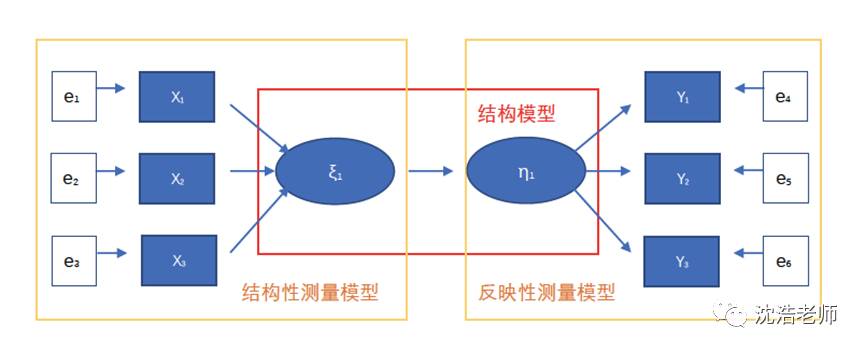
与传统SEM只可以建构反映性结构模型不同,在PLS-SEM建模中,既可以建构反映性测量模型,也可以建构形成性测量模型。除此之外,PLS-SEM还可以建构兼具两种模型的混合模型(注意:是模型中混合了两种结构,并非同一个结构中含有两种形式的指标)。因此,PLS-SEM特别适用于预测以及理论的发展,而非理论的验证。
相对于SEM对样本的需求较少,最小需求为30~100个样本
分析的数据无需服从正态分布
建模的限制
(1)模型必须是因果路径模型
(2)每一个潜变量至少应该和另一个潜变量相关
(3)每个潜变量至少需要一个观测变量
(4)每一个观察变量至少存在于一个潜变量上
(5)模型中只能存在一个结构模型
结构方程式模型的应用
当前,结构方程式模型在社会科学与心理学领域被广泛应用,尤其是在市场研究领域,结构方程式模型常常被用于以下几个方面:
市场满意度研究:
国际上已建立了瑞典顾客满意度晴雨表指数(SCSB),美国顾客满意度指数(ACSI)、欧洲顾客满意度指数(ECSI)、中国顾客满意度指数(CCSI)等经典模型。近年来,又出现了企业声誉模型,探寻企业声誉对于客户忠诚度的影响。
其他应用:
探索行为和态度动机
研究顾客对产品的偏好以及购买行为
生活方式研究
接下来,我们就将通过企业声誉模型的例子来介绍一下PLS-SEM的应用。
案例——企业声誉模型
企业声誉:
企业声誉是企业利益相关者根据自身的感知对企业过去行为结果的综合评价,企业声誉的评价主体包括很多,有普通群众、投资者、顾客、媒体机构等等。作为企业独特性的关键来源,企业声誉会为企业赢得支持并将其与竞争对手区分开来。良好的声誉能打开大门、吸引追随者、带来投资者和消费者以及赢得人们的尊敬。企业声誉作为企业的无形资产,漫长的培育过程使它具有竞争企业难以模仿的特性,势必成为企业竞争优势的主要来源。企业声誉正日益成为战略研者关注的焦点。
声誉的价值蕴涵在企业的社会网络中,不易直接量化。众多研究对声誉的测量以声誉的影响因素为中介,将其作为利益相关者所感知的企业特征,以解决声誉难以直接测量的问题。
运行软件:Smartpls
一款在国外常用的PLS-SEM软件,其基于JAVA开发,因而可以在任何平台下运行。Smartpls只能处理原始数据,结果以Html或图形格式显示。
主要步骤:
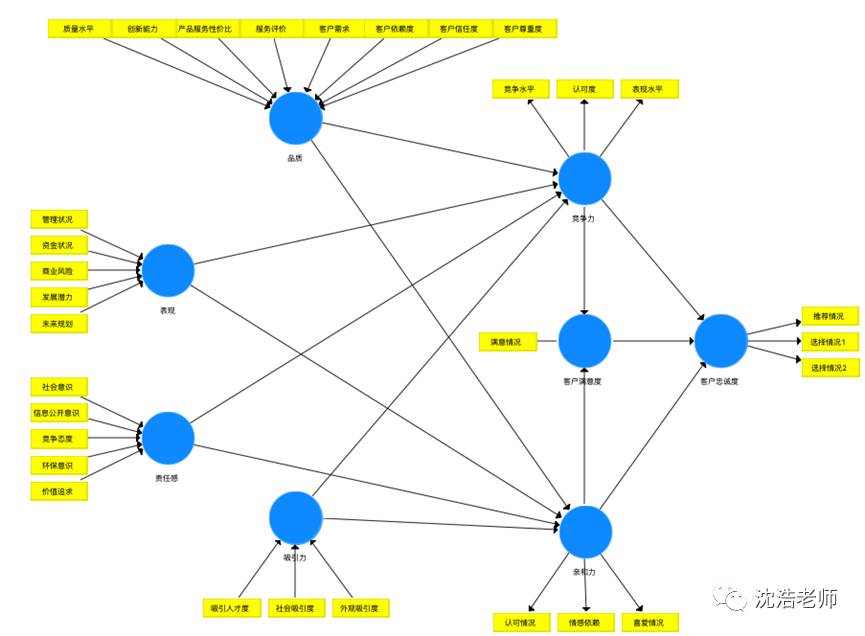
我们参考已有企业声誉建构得出以下模型。其中,企业品质、表现、责任感与吸引力构成企业声誉的四个方面,共同决定了企业的声誉好坏,并对企业的竞争力与亲和力产生了一定的影响,从而影响客户忠诚度。
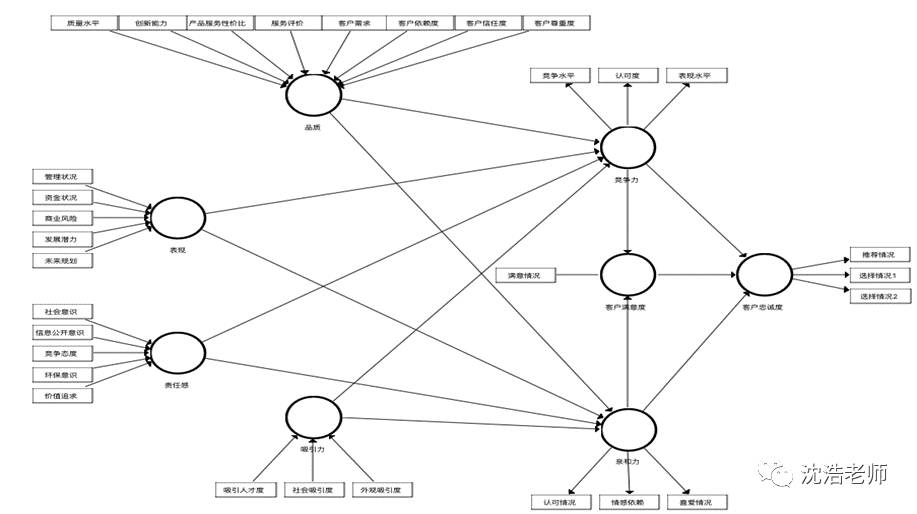
创建新项目, 并导入数据。由于数据有缺失值,且在源文件中标注为-99,故进行缺失值标注更改。
可以看到,一共有70个缺失数据。
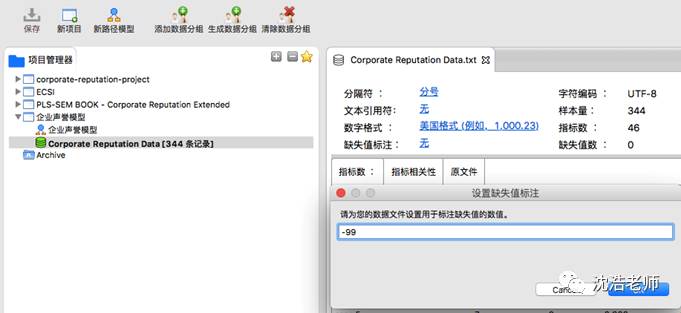
建模:
数据导入完整后开始建模,选中csor(责任感)的5项指标并拖动到建模界面中,可得一个潜变量建构。
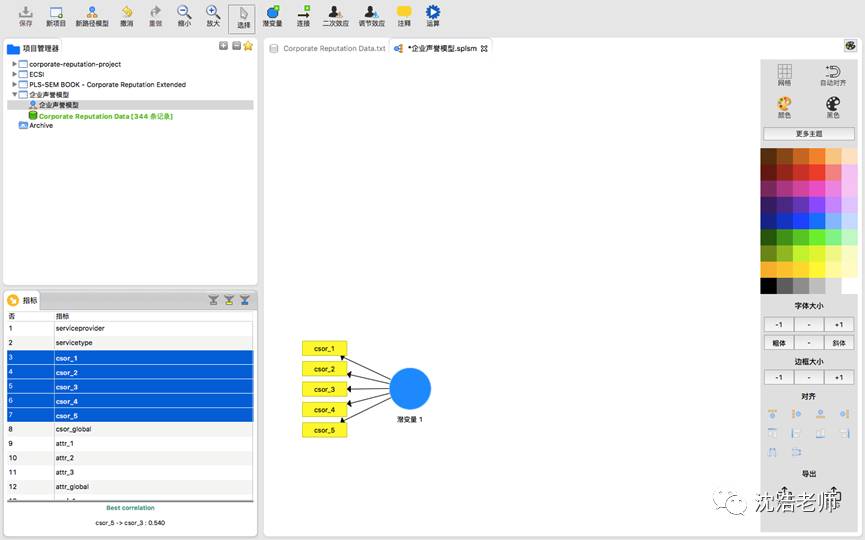
由以上的介绍可知企业声誉指标更适合形成性测量模型,故进行反映性模型——合成型模型的切换。
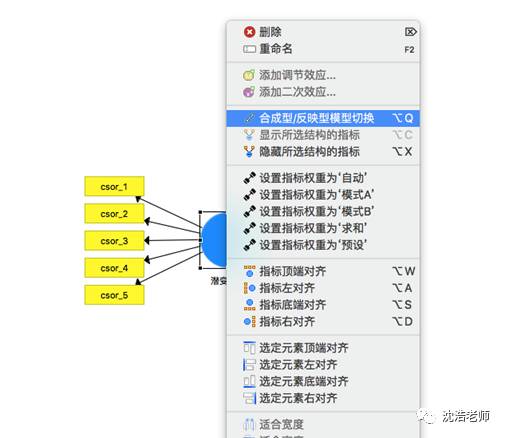
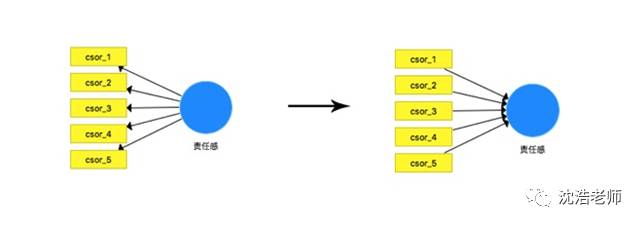
依照理论模型建构,把各个建构连接起来,选择“链接”按钮进行连接,得到模型:
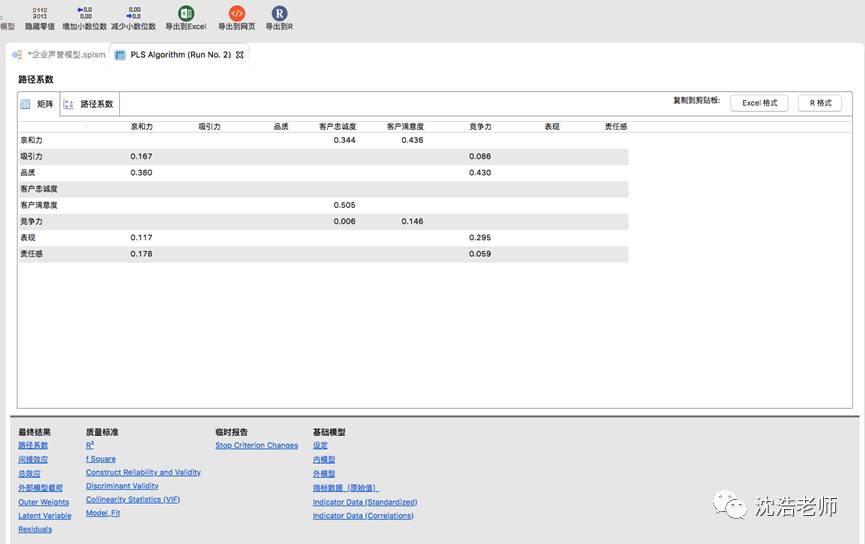
计算:
模型建好后进行计算,选择“运算”-“PLS算法”,查看运算结果,面板下方有最终结果、质量标准等数据供查询。
回到模型界面,我们可以更直观的观察数据。箭头上的数字表示权重,潜变量内的数字表示R2。
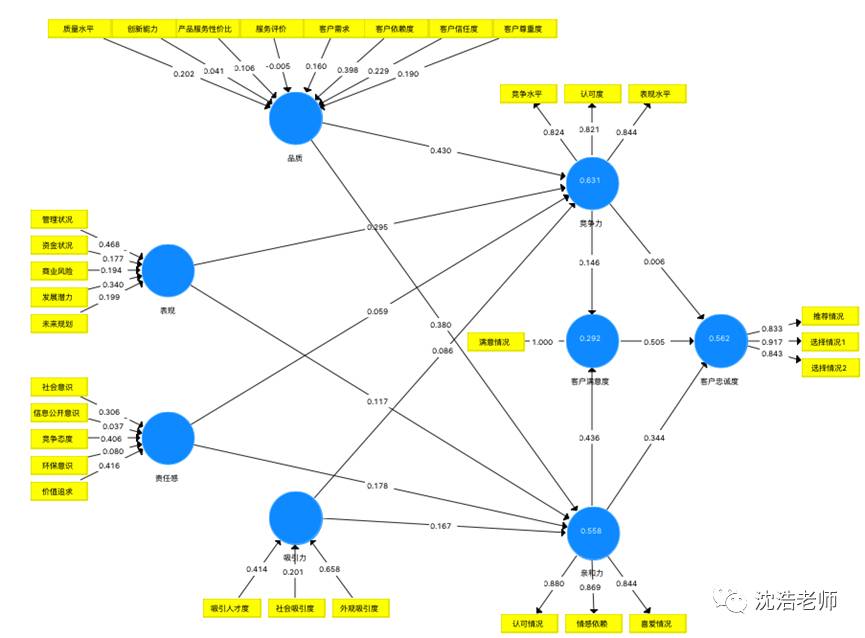
根据显示结果,我们可以推导出表示企业声誉的四个变量(品质、表现、责任感与吸引力)对客户忠诚度的相关预测公式。
此外,客户满意度(0.505)对客户忠诚度有较强影响,亲和力(0.344)和竞争力(0.006)对客户忠诚度的影响相较较低,接近于0。竞争力对客户满意度有影响但影响较小(0.146),但亲和力对客户满意度的影响较强(0.436)。对亲和力影响较大的指标是企业品质(0.380),同时对竞争力影响较大的指标是企业品质(0.430)和表现(0.295)。故公司应该更关注市场行为对顾客评价企业服务和水平品质的影响。
PLS-SEM可以建构形成性测量模型进行预测,且对样本量和样本分布要求较低,在商业模型分析中有较大优势。
沈浩老师
大数据挖掘与社会计算实验室主任
中国市场研究行业协会会长
欢迎关注沈浩老师的微信公共号




欢迎关注:灵动数艺
——数艺智训




