UNIMO 首次实现了仅用一个预训练模型同时处理多模任务和单模任务,验证了 AI 系统可以像人一样从各种不同模态数据中学习,从而获得更强大且统一的认知能力。
人类大脑能够处理文本、图像、语音等各种模态的信息,并通过模态间的交互增强提升对世界的认知能力。受此启发,百度提出统一模态学习方法,能够同时使用大量文本和图像的单模数据进行学习,并利用图文对的多模数据进行跨模态联想对比,通过预训练获得统一语义表示,从而在多种理解与生成的下游任务上超越 ViLBERT、Oscar 等多模预训练模型以及 RoBERTa、UniLM 等文本预训练模型,同时登顶视觉问答 VQA 权威榜单。
![]()
论文名称:
UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
论文地址:
https://github.com/weili-baidu/UNIMO
近年来,预训练技术在计算机视觉和自然语言处理领域均受到广泛关注。在视觉领域,通常在 ImageNet 数据上进行纯视觉的单模预训练,训练 ResNet、VGG 等图像特征抽取模型。在自然语言处理领域,基于自监督的预训练模型,如 BERT、UniLM、ERNIE,则利用大规模的单模文本数据,训练了强大的语义表示能力。为了处理多模场景的任务,各种多模预训练模型进一步被提出来,如 ViLBERT、UNITER 等。这些多模模型在图文对(Image-Text Pairs)数据上进行预训练,从而支持下游的多模任务。受限于只能使用图文对数据,多模预训练模型仅能进行小规模数据的训练,并且难以在单模下游任务上使用。
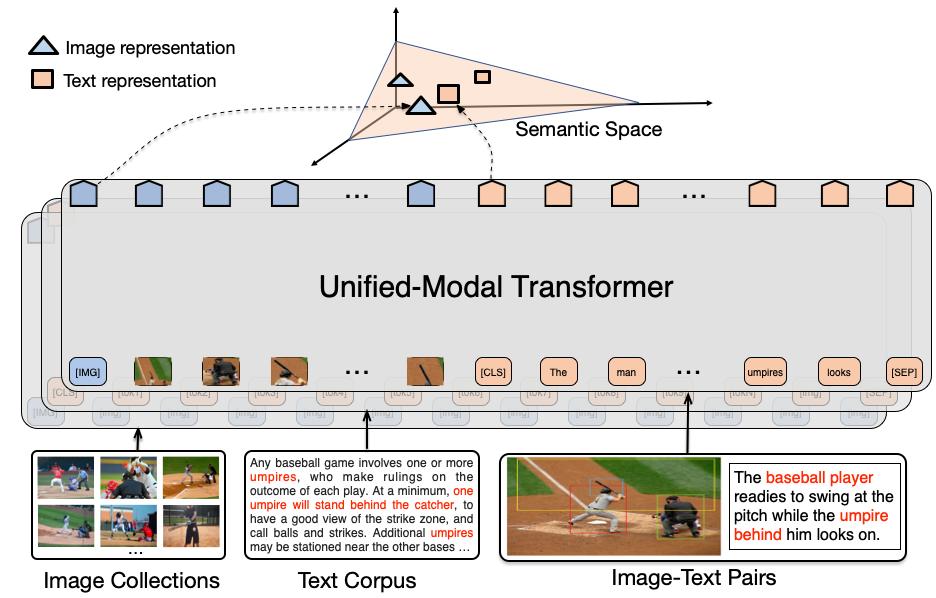
事实上,现实世界中同时存在大量纯文本、纯图像的单模数据,也存在图文对的多模数据。显然,一个强大且通用的 AI 系统应该具备同时处理各种不同模态数据的能力。为此,百度提出统一模态预训练,同时使用文本、图像、图文对数据进行预训练,学习文本和图像的统一语义表示,从而具备同时处理单模态和多模态下游任务的能力。对于大规模的单模图像数据和单模文本数据,UNIMO 采用类似的掩码预测自监督方法学习图像和文本的表示。同时,为了将文本和图像的表示映射到统一的语义空间,论文提出跨模态对比学习,基于图文对数据实现图像与文本的统一表示学习。
![]()
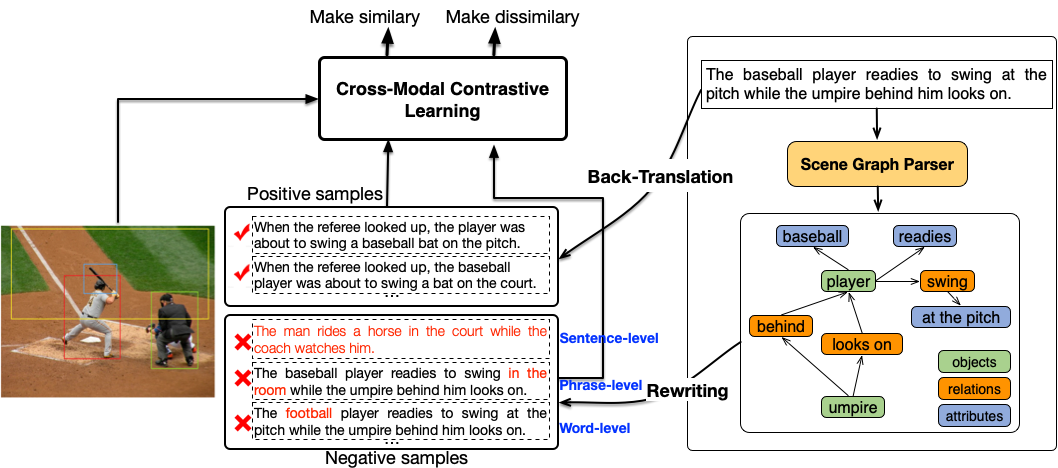
统一模态学习最大的挑战是如何跨越不同模态的语义鸿沟从而实现语义表示的统一。为了实现图像和文本的统一语义表示,百度提出了多粒度的跨模态对比学习。在句子级别,UNIMO 使用回译方法和检索方法获得大量正例和强负例。在短语和单词级别,UNIMO 首先根据图描述解析出结构化的场景图,然后通过单词级和短语级的替换改写,获得大量细粒度的强负例。这样利用扩充后的正例以及各种粒度的高质量强负例,并与图像进行语义相似度对比,UNIMO 能够学习到精确对齐的多模语义表示。
![]()
在实验方面,UNIMO 使用了大规模的单模和多模数据进行联合预训练,同时在各种单模和多模下游任务上进行验证。预训练数据部分,文本语料包括 Wikipedia、BookCorpus、OpenWebText 等语料;图像数据是从互联网爬取的 300K 图像;而多模图文对数据则包括 COCO Caption、Visual Genome、Conceptual Caption、SBU Caption。下游任务既包括视觉问答、图描述生成、视觉推断等多模任务,也包括文本分类、文本摘要、问题生成等各种文本任务。模型上,论文中使用 12 层的 Transformer 进行预训练。
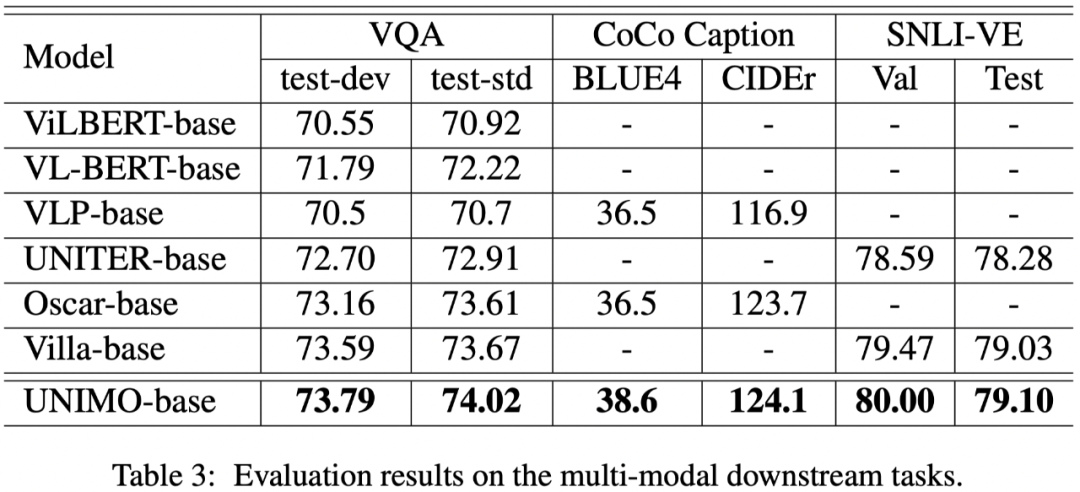
在多模任务上,论文主要对比 ViLBERT、VLP、UNITER、Oscar、Villa 等最新的多模预训练模型。实验结果表明,UNIMO 在视觉问答 VQA、图描述生成 CoCo Caption、视觉推断任务 SNLI-VE 上均稳定地超过此前的各种模型,充分说明了统一模态 UNIMO 模型能够有效地处理各种多模任务。
![]()
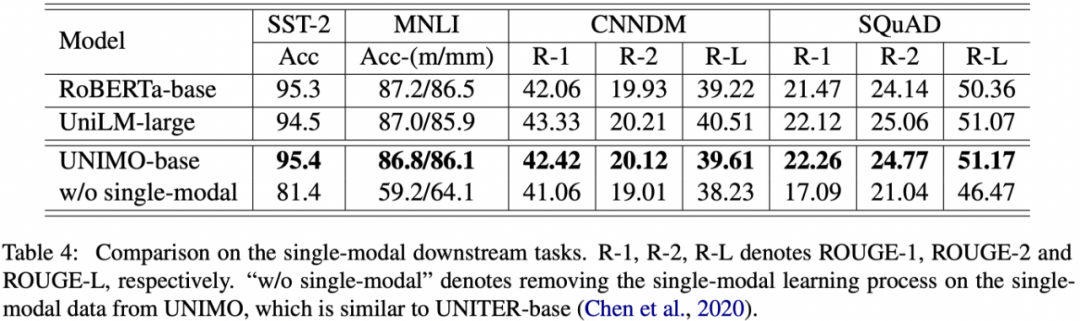
特别的,与以往多模预训练不同的是,UNIMO 同时还能处理纯文本的单模任务。此前的多模预训练模型,在处理单模文本任务的时候效果急剧下降,部分任务下降幅度甚至超过 10-20 个点。而 UNIMO 在各类文本理解和生成任务上,包括文本分类、文本推断、文本摘要和问题生成,均取得不错的效果,部分任务甚至超过 RoBERTa、UniLM 等文本预训练模型。
![]()
UNIMO 很大的优势是能同时使用单模数据和多模数据进行预训练,从而利用大规模数据学习更强大的统一模态语义表示。为了验证单模数据的有效性,论文还进行了分离实验。实验结果表明,当不使用文本单模数据进行预训练的时候,UNIMO 在多模任务上效果有所下降。而当不使用多模图文对数据和图像数据的时候,UNIMO 在文本理解和生成任务上同样会下降。这充分说明了单模数据在统一模态学习中的有效性,也说明了 UNIMO 模型可以有效利用不同模态数据进行跨模态联合学习。
![]()
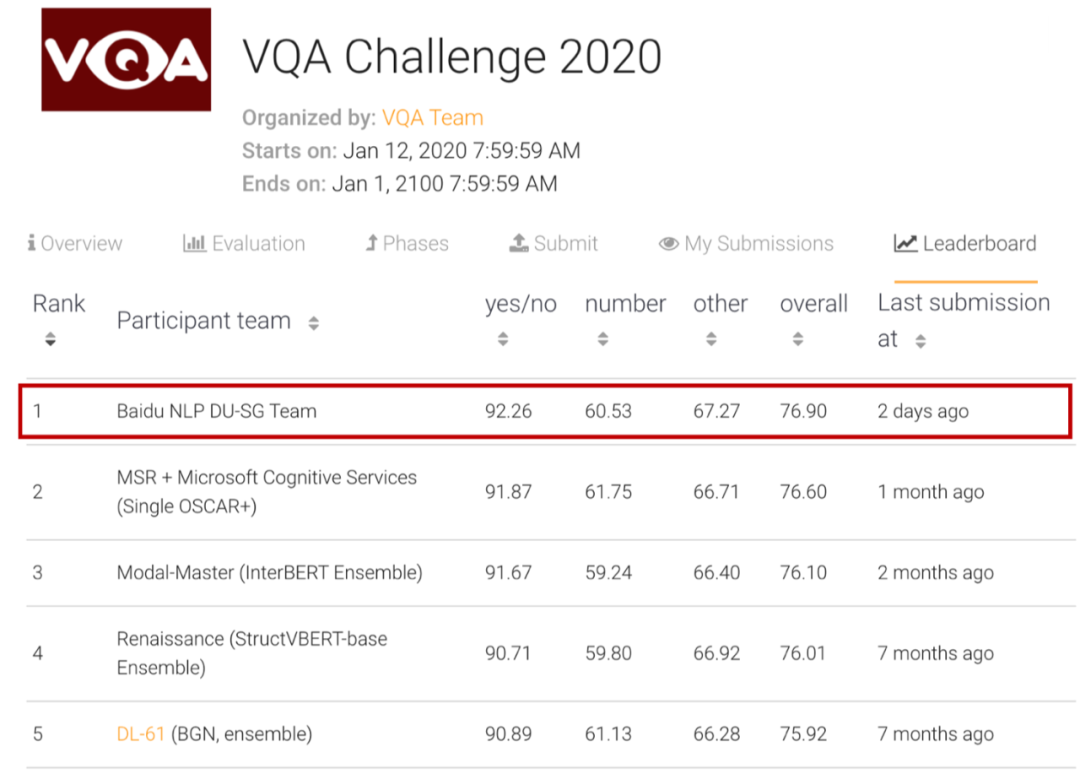
此外,百度基于 UNIMO 还刷新了视觉问答 VQA 权威榜单,超越了微软、阿里巴巴、Facebook 等知名单位,位列榜首,进一步说明了统一模态预训练的领先性。
![]()
总体上,百度提出了统一模态学习方法 UNIMO,通过利用跨模态对比学习,有效地将视觉和文本信息进行语义对齐,进而学习强大而统一的文本与视觉语义表示。UNIMO 首次实现同时利用单模和多模数据进行预训练,并能够同时有效处理单模和多模任务。UNIMO 提供了一种新的学习范式,让机器可以像人一样利用大规模不同模态的数据,学习统一的语义表示,提升机器的认知能力。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com