最近看到ICLR2020关于特征学习和计算机视觉的论文,发现VGG组Andrew Zisserman (做CV领域应该都知道,不知道的请自行补课)和Andrea Vedaldi(用过VLFeat的应该知道)两位大佬挂名了一篇论文:"AUTOMATICALLY DISCOVERING AND LEARNING NEW VISUAL CATEGORIES WITH RANKING STATISTICS"。这篇论文的问题和想法比较有意思,所以就写一个笔记记录一下。 论文:https://openreview.net/pdf?id=BJl2_nVFPB
发现新的视觉类别(Discover New Visual Categories)
New Visual Categories Discovery这个问题的定义如图1,首先我们给定有标签的已知类别图像数据,目标是对未知并且无标签的图像集合进行聚类(视觉类别发现),使聚类结果尽可能接近图像的真实语义类别。视觉类别发现与半监督学习以及领域自适应等问题的区别在于,这里无监督数据和有监督数据的类别是不同的。图1. New Visual Categories Discovery任务定义。这个任务通过利用已知的有标签图像,对类别不确定的无标签数据进行聚类,使得聚类结果尽可能接近真实的视觉语义类别。需要指出,视觉类别发现区别于简单聚类任务,这里有监督的数据是必不可少的。直观的理解如图2,如果没有任何先验知识,那么聚类结果不具有唯一性。根据颜色、形状、边框类型,我们分别可以得到不同且合理的聚类结果。有了有标签数据之后,我们可以得到关于视觉类别的先验知识作为聚类参考,从而消除了很多歧义和不合理的聚类。图2. 如果没有任何先验知识,聚类结果不具有唯一性。例如我们根据颜色、形状、边框类型,可以得到3组不同但是都合理的聚类结果。
自监督学习最近得到越来越多的关注,而且在不同任务里面得到了体现,包括但不限于提升特征表达能力、提高模型稳定性、防止过拟合等等。 视觉类别发现,是一个比较有意思的任务。 相关论文:1. AUTOMATICALLY DISCOVERING AND LEARNING NEW VISUAL CATEGORIES WITH RANKING STATISTICS, ICLR20202. Learning to Discover Novel Visual Categories via Deep Transfer Clustering, ICCV2019

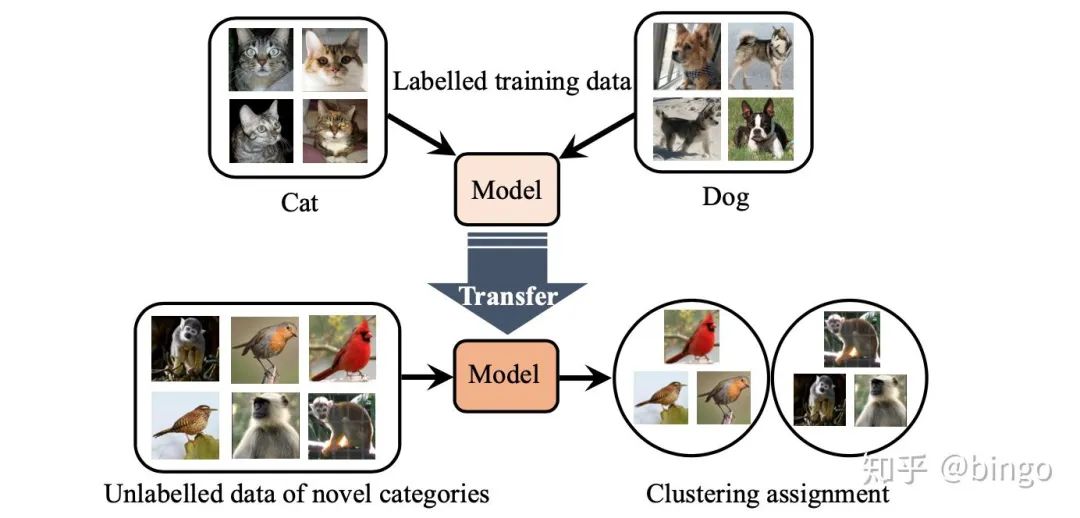
 图2. 如果没有任何先验知识,聚类结果不具有唯一性。
例如我们根据颜色、形状、边框类型,可以得到3组不同但是都合理的聚类结果。
图2. 如果没有任何先验知识,聚类结果不具有唯一性。
例如我们根据颜色、形状、边框类型,可以得到3组不同但是都合理的聚类结果。


 。
。





 。
。







