【论文分享】ACL 2020 多模态相关任务分享
![]()
引言
![]()

引言

![]()
文章概览
![]()
文章概览
Multimodal Neural Graph Memory Networks for Visual Question Answering
论文地址:https://www.aclweb.org/anthology/2020.acl-main.643.pdf
这一篇关于VQA任务,尝试通过利用图像区域生成的字幕来辅助图像和文本的交互和推理,使用了多模态神经图记忆网络。
Improving Image Captioning with Better Use of Caption
论文地址:https://www.aclweb.org/anthology/2020.acl-main.664.pdf
这一篇是image caption任务,构建了caption引导的视觉关系图来提高生成质量,使用了弱监督多实例的训练框架,图卷积表示,多任务生成等。
Clue: Cross-modal Coherence Modeling for Caption Generation
论文地址:https://www.aclweb.org/anthology/2020.acl-main.583.pdf
这一篇也是关于image caption任务,重点关注了字幕与图像之间的连贯关系,希望能够生成有一致关系引导的字幕。
![]()
论文细节
![]()
论文细节

动机
文章提出了一种新的多模态神经图记忆网络(MN-GMN)来解决VQA任务。MN-GMN的输入模块通过图片生成一组视觉特征和相应的区域字幕(RGC)。从图像区域中生成的RGC可以反映对象属性及其关系。随后分别构造出两个GNs,每个节点迭代地更新视觉/文本的上下文表示。之后,将更新后的表示合并到外部空间记忆中。应答模块使用存储单元的最终状态预测答案。
模型
模型主要有四个模块:输入、问题、多模态图记忆网络和应答模块。
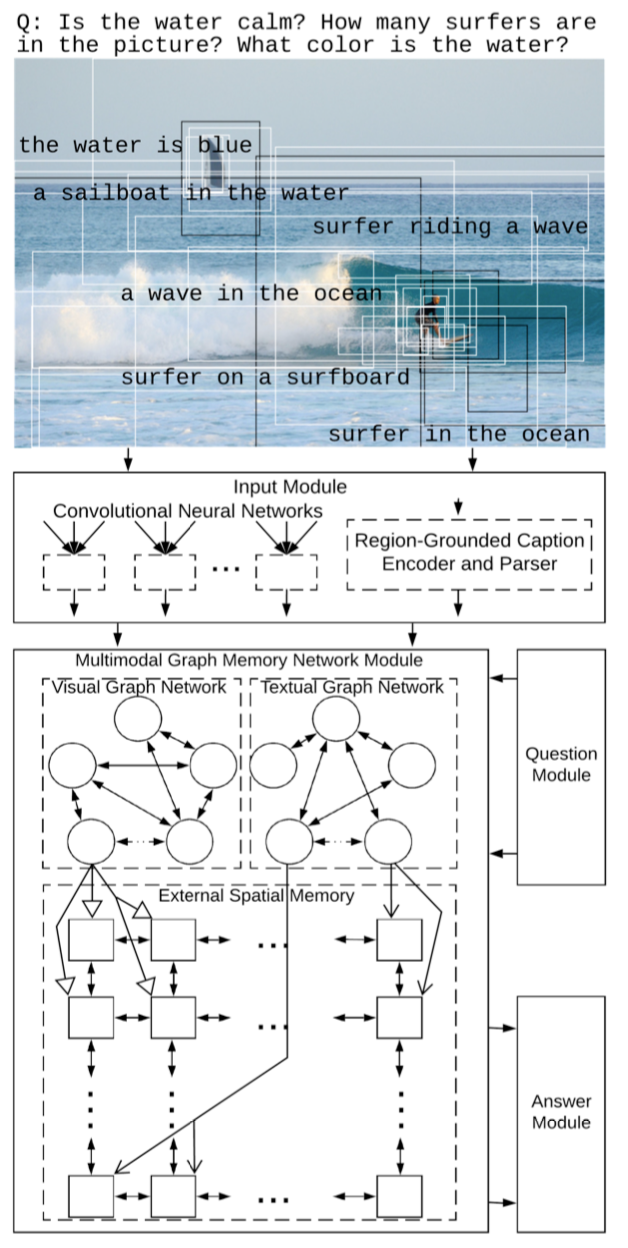
输入模块使用Faster R-CNN 抽取图像区域特征,使用字幕生成模型提取出区域对应的描述(RGCs),并用GRU和句法分析器来编码。句法分析可以将RGC分解为关系三元组集。
多模态图记忆网络模块包括视觉图网络、文本图网络和外部空间记忆三部分。两个图网络分别通过区域视觉特征和区域文本特征(RGC)构建。通过问题向量来引导节点初始化。外部记忆网络的单元是将图像的均分P×Q块。覆盖到某个单元的图网络节点会分别将信息传入该单元进行更新。
应答模块也是一个图网络,节点也是外部记忆单元。使用最终更新后的全局特征来分类。
模型
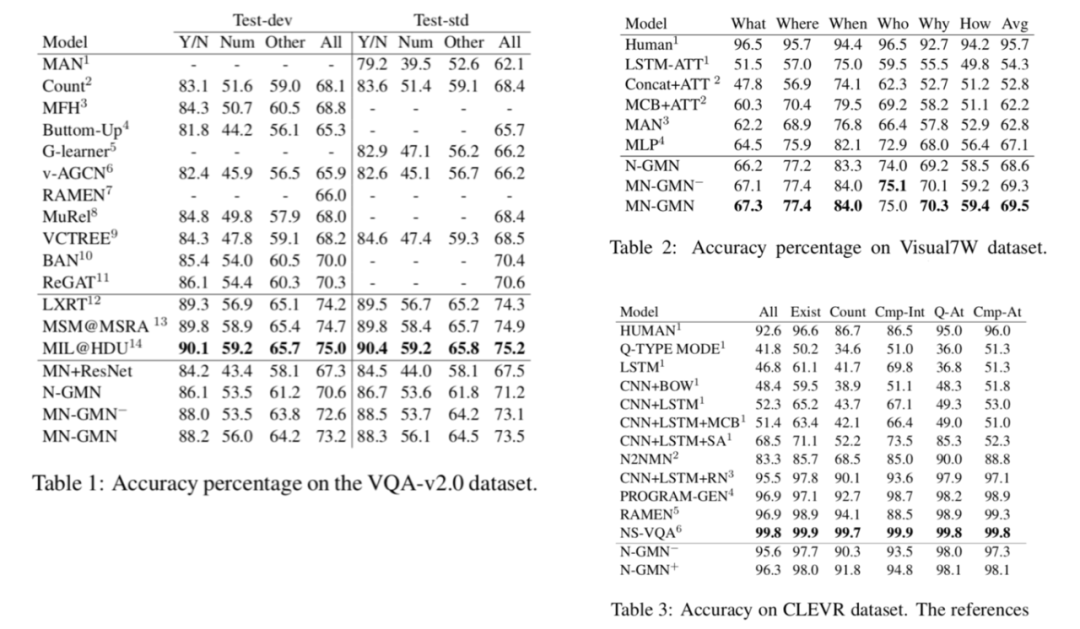
完整模型和不同的消融模型在三个数据集上的表现如下图:
一些案例研究和注意力可视化如下图:


动机
图像字幕生成需要有一个合适的语言和图像的语义表示。为了解决忽略重要的断言(predicates)以及断言和物体对之间连接的模糊性,文章提出了一种新颖的图像字幕架构,以探索字幕中可用的语义,并利用它来增强图像的表示和字幕的生成。模型首先使用弱监督多实例学习来构造字幕引导的视觉关系图,引入有益的归纳倾向。然后通过相邻节点和上下文节点以及它们的文本和视觉特征来增强表示。在生成过程中,该模型进一步结合视觉关系,使用多任务学习来联合预测单词和相对应的标记序列。大量的实验表明提出的框架显著优于基准。
模型
模型有三个部分:利用弱监督多实例学习构造字幕引导的视觉关系图(CGVRG);建立环境感知的CGVRG;进行多任务生成,使模型得以考虑到显式的对象/断言约束。
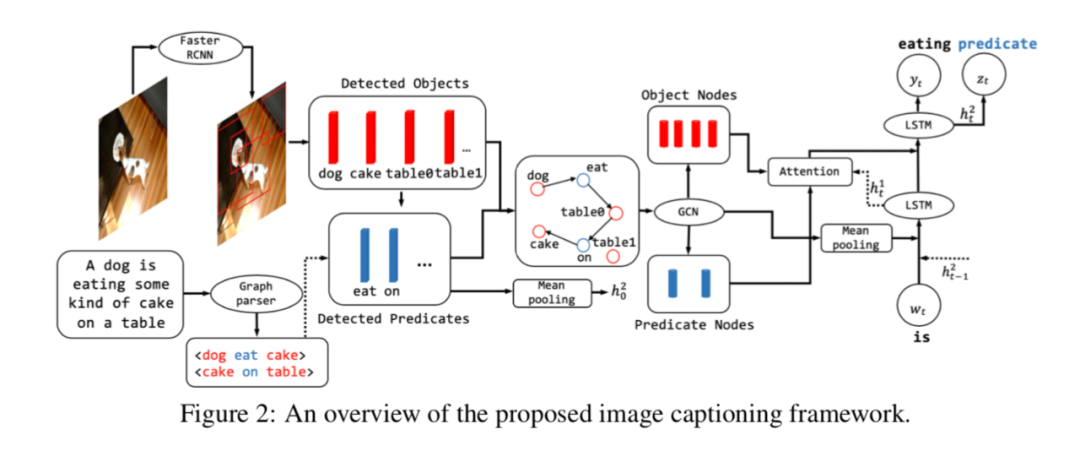
(1)基于弱监督学习的字幕引导视觉关系图的构建
首先使用场景图分析器从文本中提取出视觉关系三元组,用Faster R-CNN识别图像中目标实例。通过区域对的图像特征可以计算出该区域对的断言分布概率。由于训练过程中,目标对可能会对应多个区域对,文章使用弱监督多实例学习方法训练。具体来说,先建立一组带标签的包,每个包包含一组实例(本文中就是区域对)。如果一个包中的所有实例都不包含字母中的断言,那么它将被标记为负。另一方面,如果包中至少有一个包含字幕中的断言,则该包被标记为正。可以计算得到每个包有断言 的概率为:
这样就可以通过对包的标注训练断言分布概率:
通过弱监督模型构建的关系图可以包含在训练字幕中存在的断言,而不仅仅是预训练VRD模型训练集中的,有助于提高生成质量。
(2)增强关系图的表示
文章进一步使用图卷积网络,增强CGVRG的表示能力。对于目标先集成视觉和文本特征,断言则只有文本特征:
随后通过GCN进行更新:
(3)多任务生成
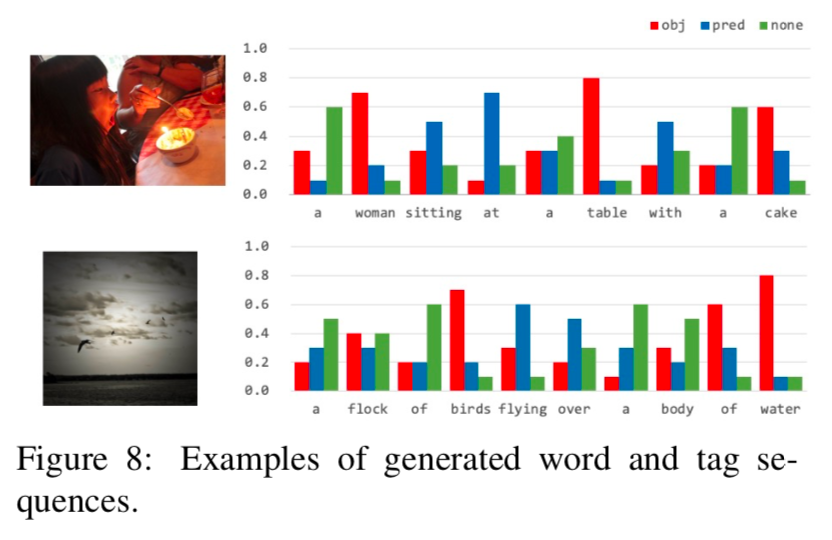
在生成过程中,论文提出联合预测单词和标签序列,描述中的每个单词都会被分配一个标签,也就是object、predicate或none。使用双层lstm分别进行对齐和解码:
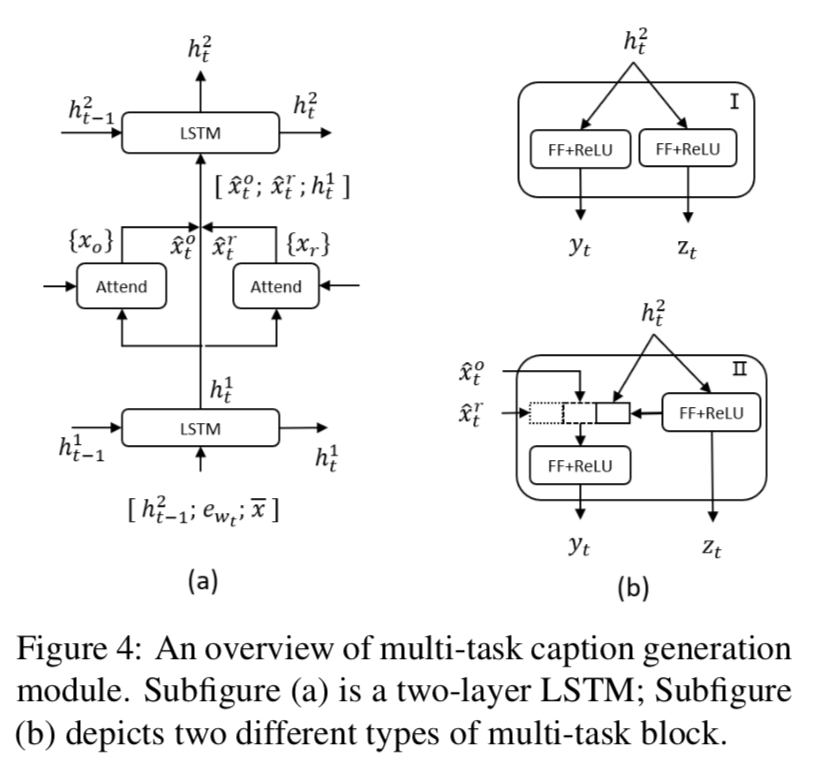
第一种方式独立的生成单词和标签:
第二种方式利用标签的分布来影响单词的预测:
实验
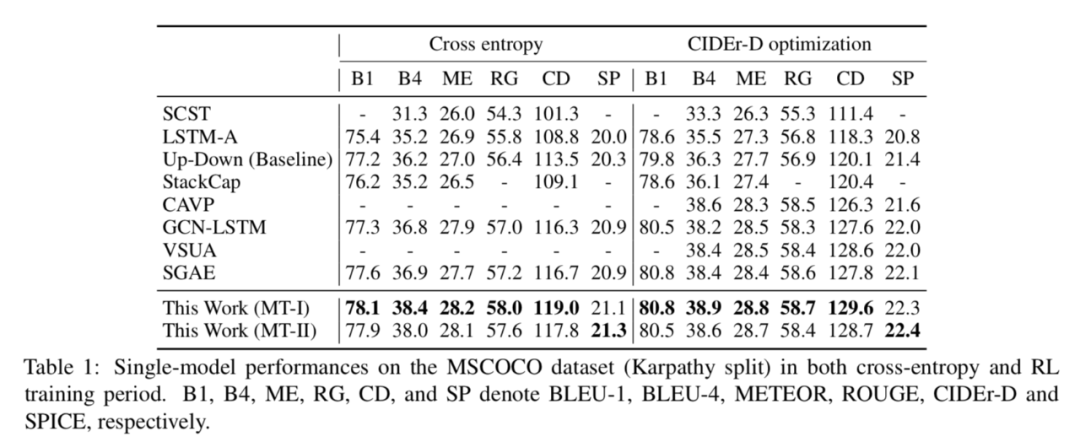
与单模型比较,效果显著超过了基准模型:
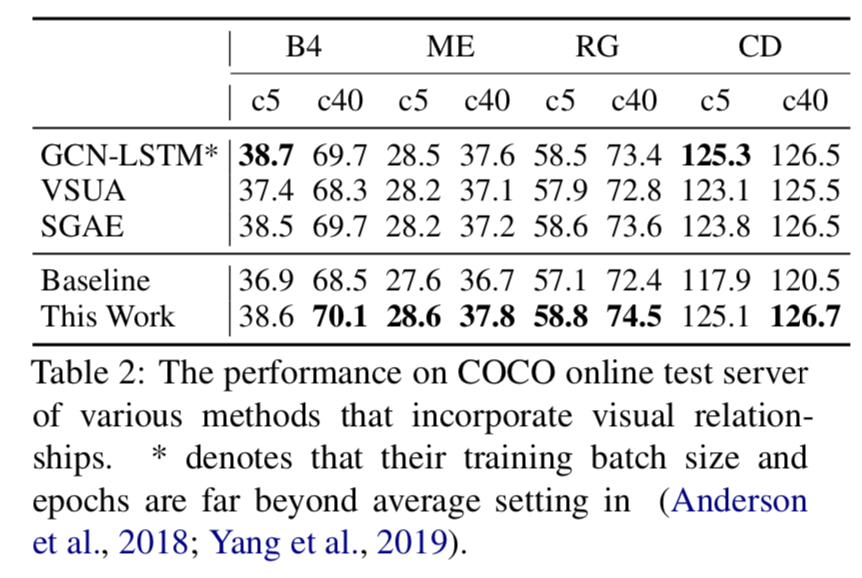
与使用视觉关系图的基准模型比较,效果也是大部分占优:
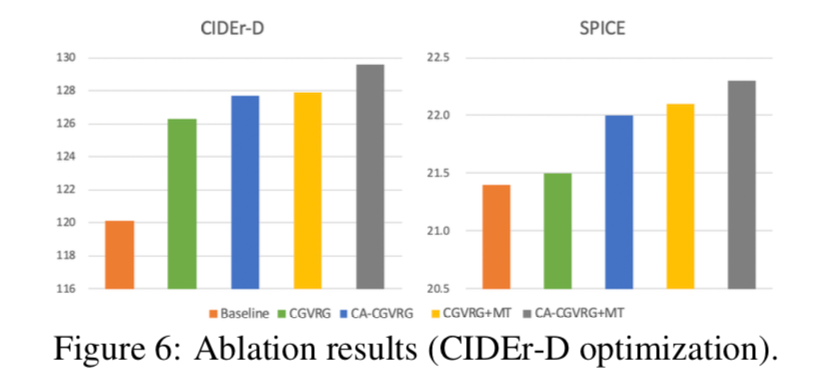
消融实验表明了各个部分的有效性:
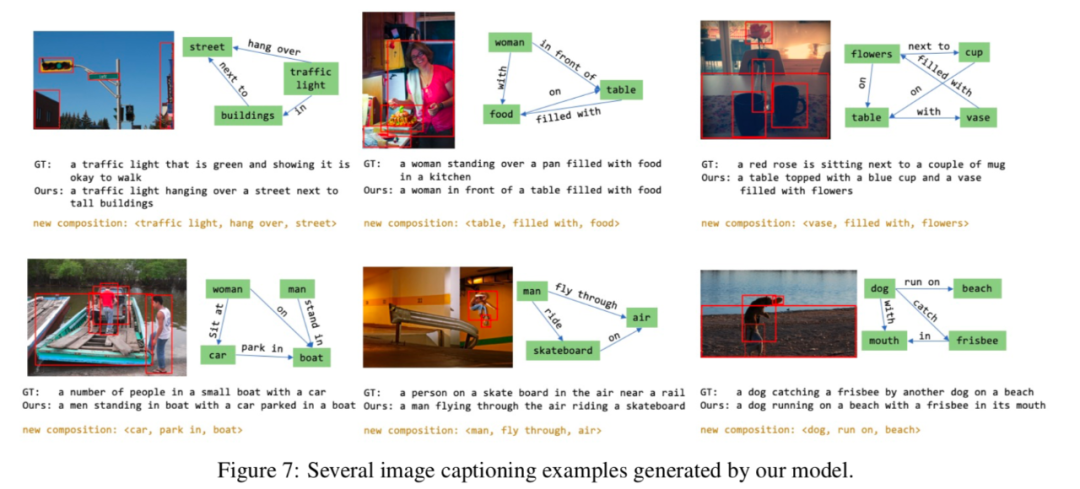
还有案例研究:

动机
借鉴论辩计算模型,该论文从图像和语篇连贯性关系研究图像字幕的信息需求和目标,使用一个专门的连贯关系注释协议,从公共图像字幕注释了10000个实例,并提出了一个新的推理图像和文本连贯关系的任务,表明这些连贯注释可以作为中间步骤学习关系分类,还可训练具有连贯关系意识的图像字幕模型。根据连贯关系确定的信息需求,生成的字幕在一致性和质量上都有显著提高。
图像和标题的连贯关系
考虑的连贯关系主要有5种:
Visible指的是文本的信息旨在识别图像中描述的内容;Subjective,即文本描述了说话人对图像中所描述的事物的反应或评价;Action 中文本描述了一个扩展的动态过程,图像是其中的一个瞬间快照;Story中文本提供了图像中环境的独立描述,包括指导、解释和其他背景关系;Meta,还可以推断图像本身的生成和呈现。

标注的数据集
标注的数据集有5000个人工图像字幕对是随机取自Conceptual Captions dataset的训练集,还有5000个机器编写字幕的代表性样本是由图像字幕挑战赛的前5个模型获得。数据集注释的分析:
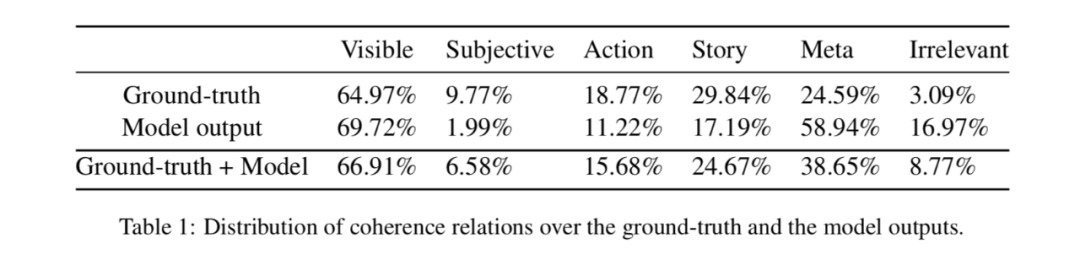
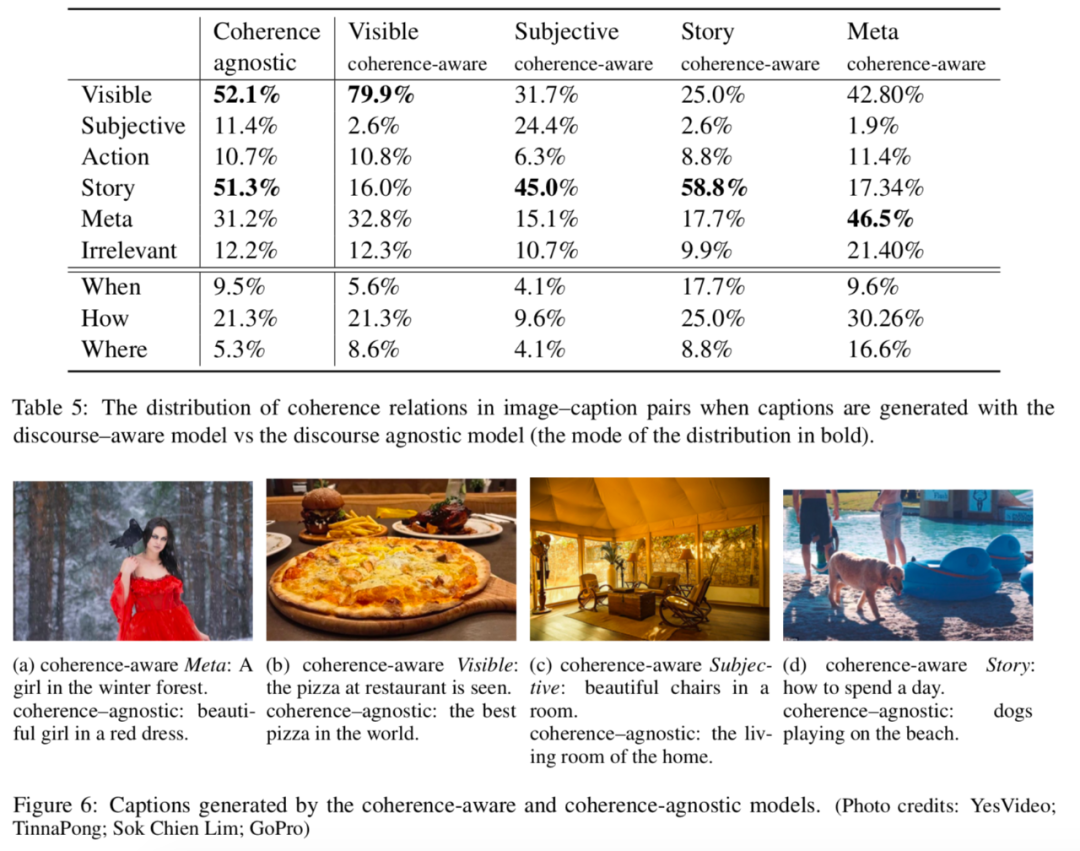
总的来说,visible在两种字幕的标注中都占了很大部分(65%和70%)。模型输出的字幕中subjective和story的比率显著降低,且meta的比率增加了25%左右,这表明这些模型可能容易产生上下文幻觉效应。在模型生成的字幕中,irrelevant字幕的比例增加到17%左右,而在基本真实字幕中,这一比例仅为3%。此外,似乎模型有一定的能力来生成事件发生的位置,但它们生成时间信息的能力较低。
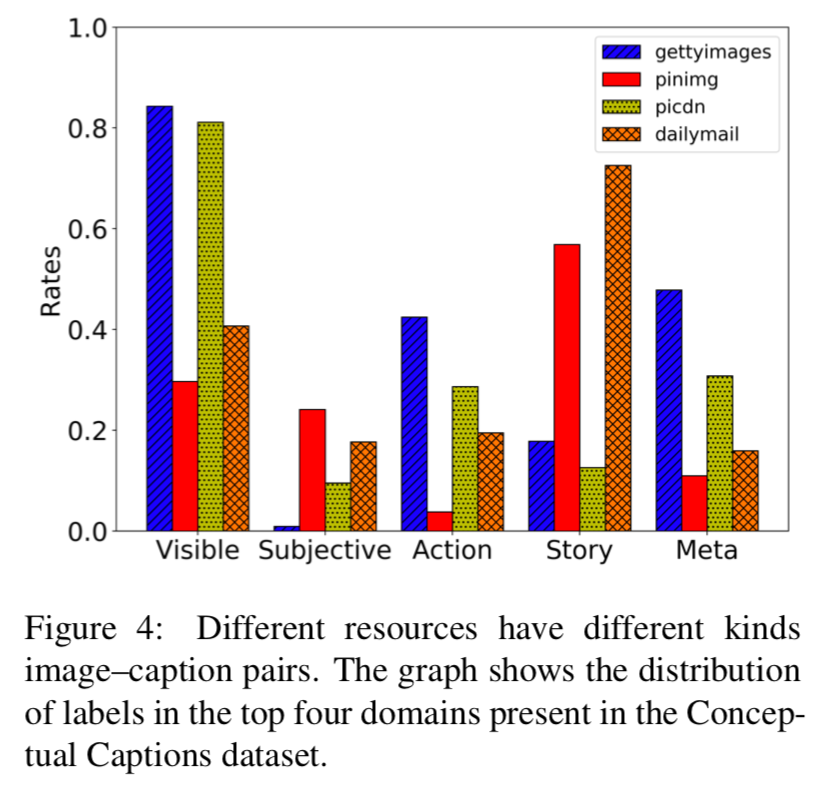
从注释根据字幕体裁的分布图可以得到,连贯关系可以反映语篇类型及其目的,也即不同出版来源的图片字幕对在连贯关系上有不同的分布。
预测连贯关系任务
在这一部分中,论文训练和测试了一些针对连贯关系预测的简单模型,表明了机器学习模型在文本和图像的连贯关系分类中的潜力。
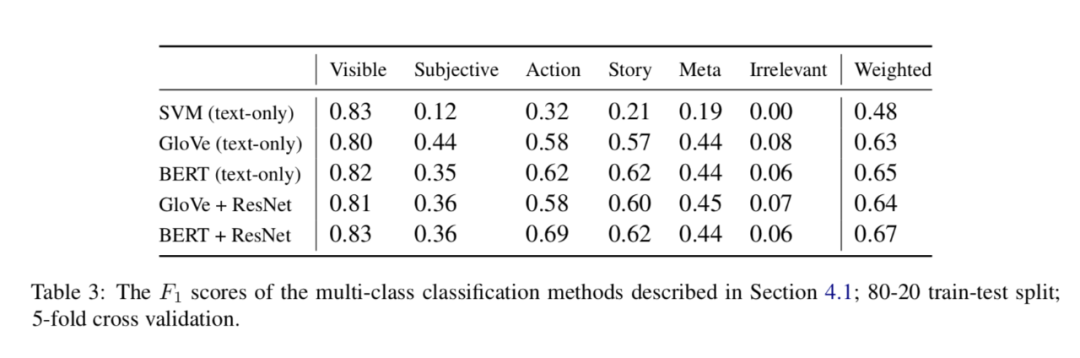
多标签预测结果
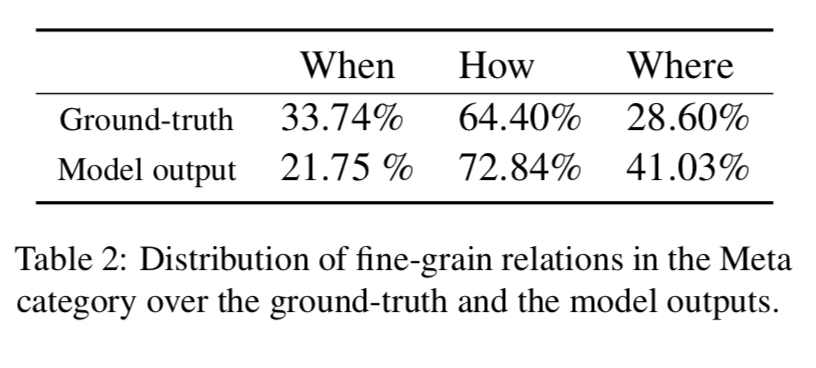
单标签预测结果
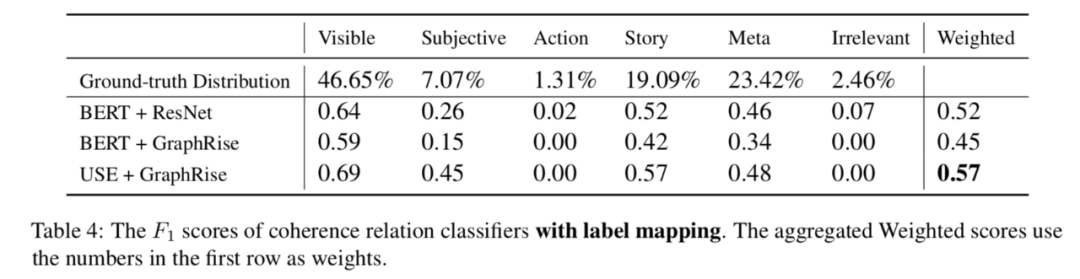
论文还通过一些启发式方法将图片标题对的注释映射到单个标签,然后进行预测。映射后的分布和实验结果如下图所示。
生成连贯关系引导的字幕
利用之前预测的连贯性标签,文章还提出了一个基于连贯性的字幕生成模型。
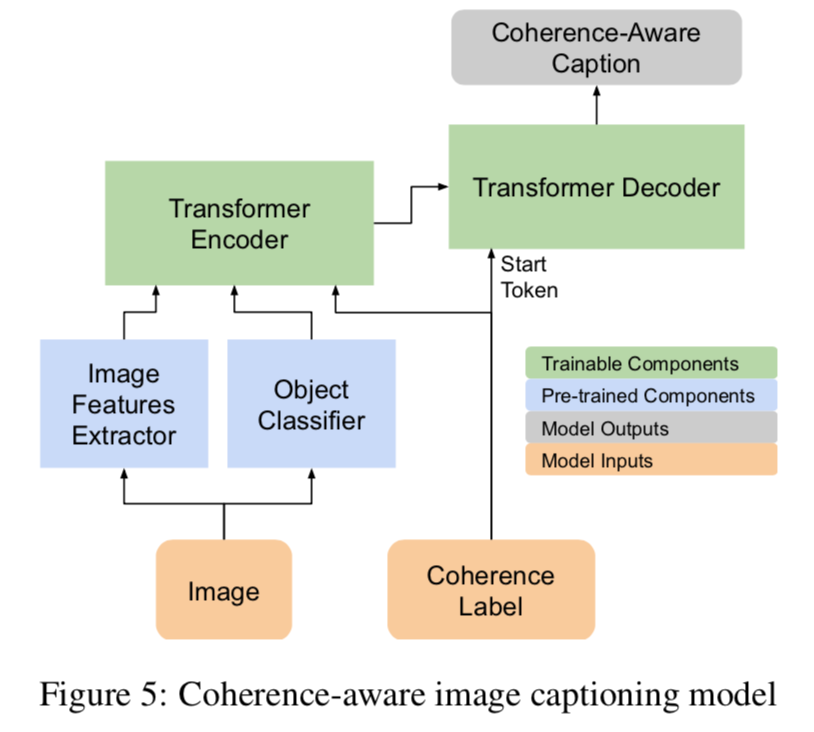
实验
跨模态连贯模型显著地提高了所生成文本相对于信息需求的一致性和质量。
参考文献
[1] Mahmoud Khademi. 2020. Multimodal Neural Graph Memory Networks for Visual Question Answering. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.
[2] Zhan Shi, Xu Zhou, Xipeng Qiu, Xiaodan Zhu. 2020. Improving Image Captioning with Better Use of Captions. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.
[3] M. Alikhani, P. Sharma, S. Li, R. Soricut, M. Stone. 2020. Clue: Cross-modal Coherence Modeling for Caption Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!