谷歌又闹大乌龙!Jeff Dean参与的新模型竟搞错Hinton生日
![]()
新智元报道
新智元报道
【新智元导读】最近,谷歌研究员发布了关于指令微调的最新工作!然而却宣传图中出现了可笑的乌龙。
几个小时之前,谷歌大脑的研究员们非常开心地晒出了自己最新的研究成果:
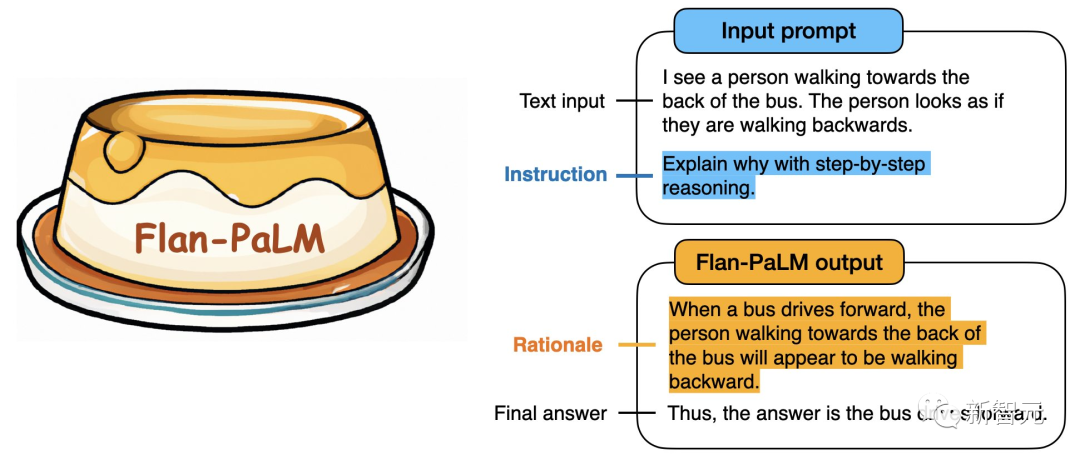
「我们新开源的语言模型Flan-T5,在对1,800多种语言的任务进行指令微调后,显著提高了prompt和多步推理的能力。」
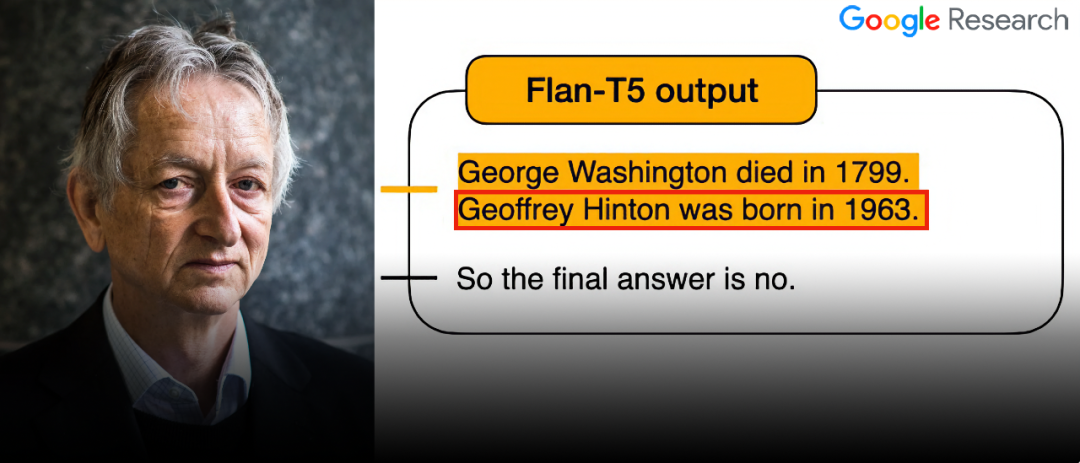
然而,就在这张精心制作的「宣传图」上,竟藏着一个让人哭笑不得的bug!

请注意看Geoffrey Hinton的出生日期:

但实际上,Hinton出生于1947年……

虽然没有必然联系,但是谷歌自己的模型,竟然会把自家大佬的生日搞错?
马库斯同志看完直接就惊了:你们谷歌,没人负责审核的吗……

理论上,这篇拥有31位作者,外加Jeff Dean这种大佬参与的论文,不应该发生这种「低级错误」才对啊。

「复制」的时候「打错了」而已!
很快,论文的共同一作就在马库斯的推文下面进行了回复:「我们都知道,模型的输出并不总是符合事实。我们正在进行负责任的AI评估,一旦有了结果,我们将立即更新论文。」

没过多久,这位作者删除了上面那条推文,并更新留言称:「这只是在把模型的输出复制到推特上时,『打错了』而已。」

对此,有网友调侃道:「不好意思,你能不能给我翻译翻译,什么叫『复制』来着?」

当然,在查看原文之后可以发现,「图1」所示的生日,确实没错。
至于在宣传图中是如何从「1947」变成「1963」的,大概只有做图的那位朋友自己知道了。

随后,马库斯也删除了自己的这条推文。
世界重归平静,就像什么也没有发生一样。
只留下谷歌研究员自己推文下面的这条在风中飘摇——

扩展指令微调语言模型
既然误会解除了,我们就让话题重新回到论文本身上来吧。
去年,谷歌推出了一个参数量只有1370亿的微调语言网络FLAN(fine-tuned language net)。

https://arxiv.org/abs/2109.01652
FLAN是Base LM的指令调优(instruction-tuned)版本。指令调优管道混合了所有数据集,并从每个数据集中随机抽取样本。
研究人员称,这种指令调节(instruction tuning)通过教模型如何执行指令描述的任务来提高模型处理和理解自然语言的能力。
结果显示,在许多有难度的基准测试中,FLAN的性能都大幅超过了GPT-3。
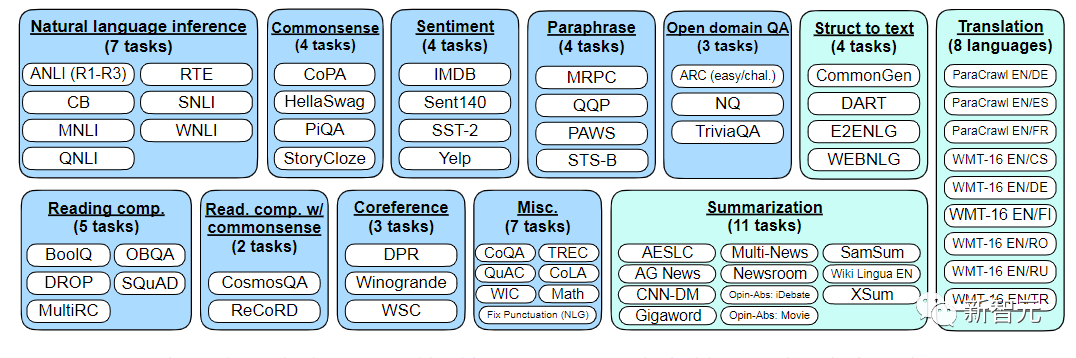
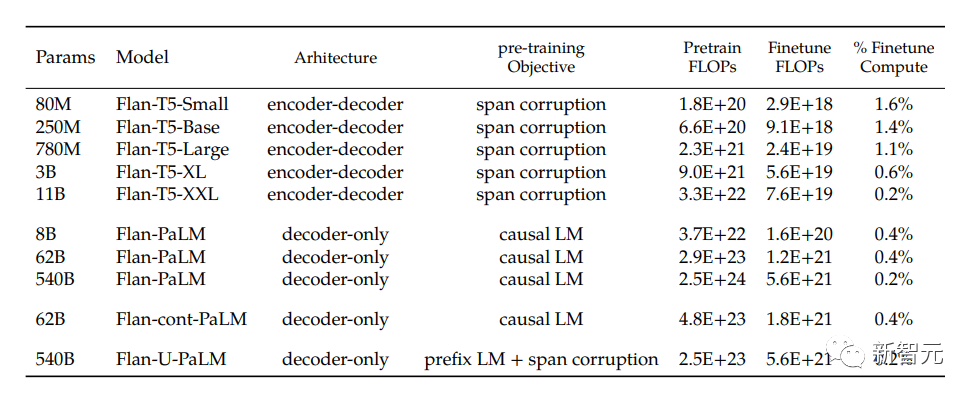
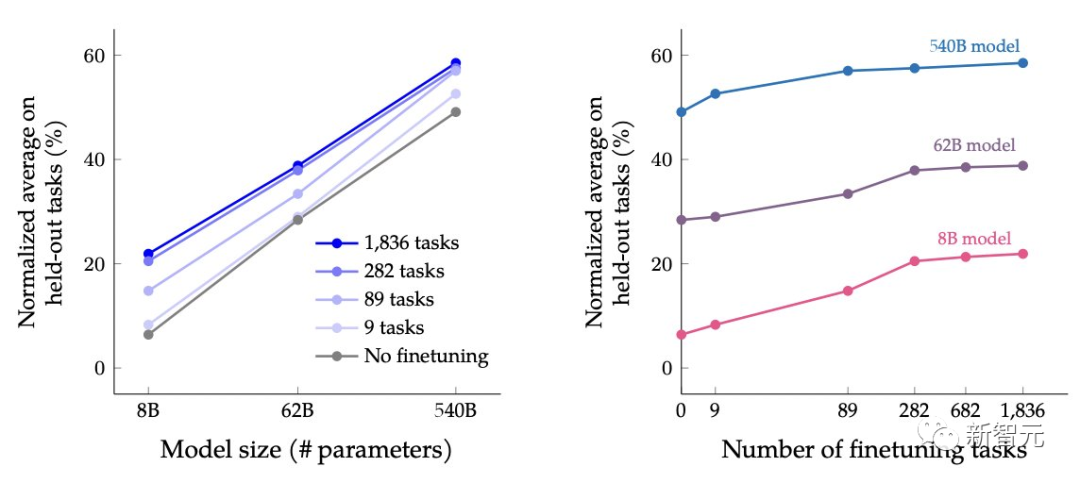
这次,谷歌将语言模型进行拓展之后,成功刷新了不少基准测试的SOTA。
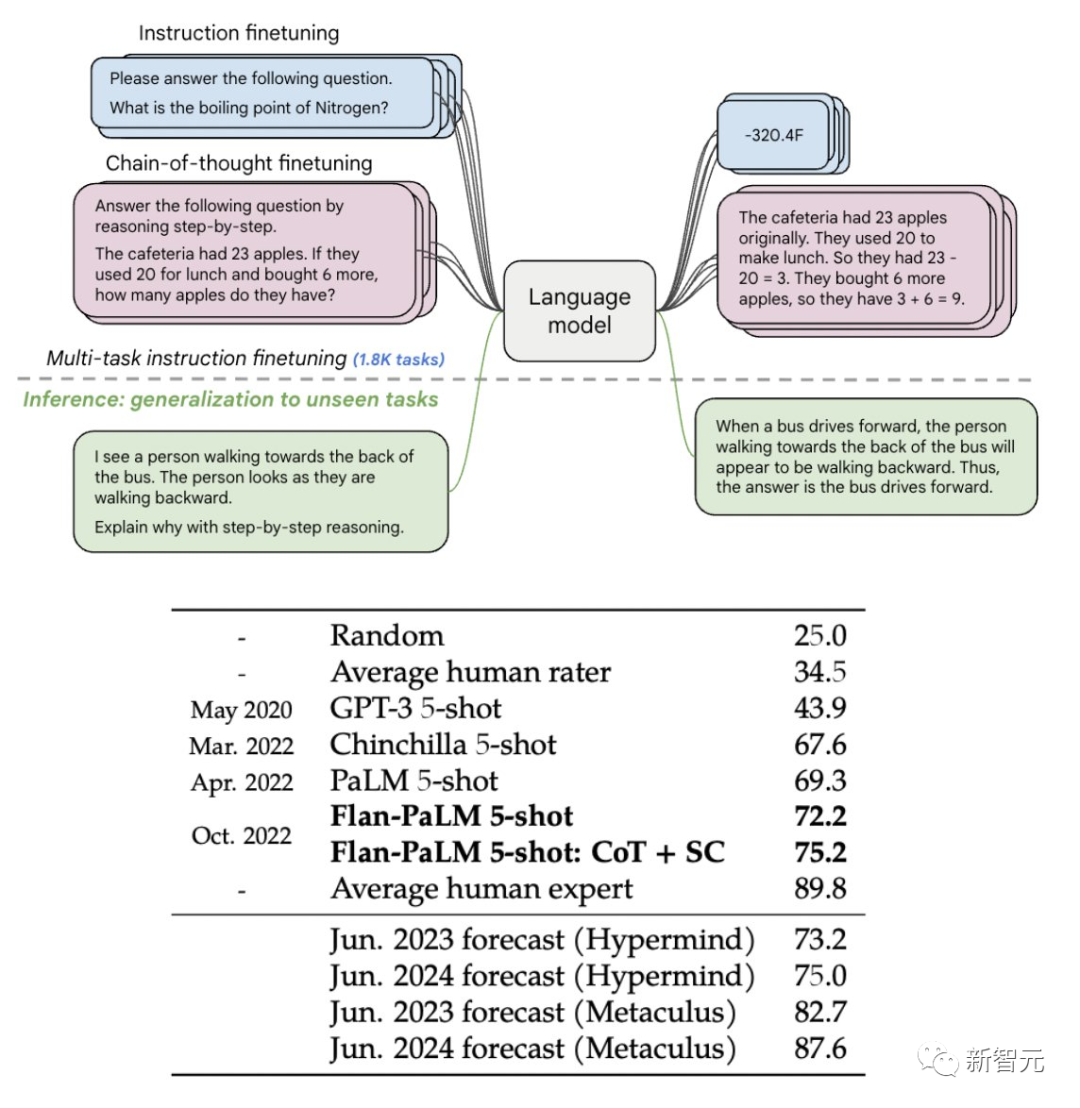
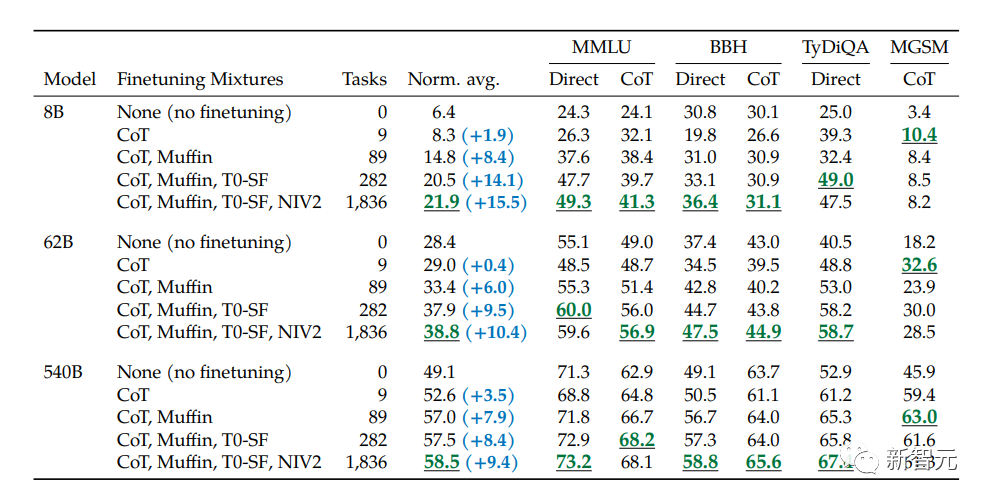
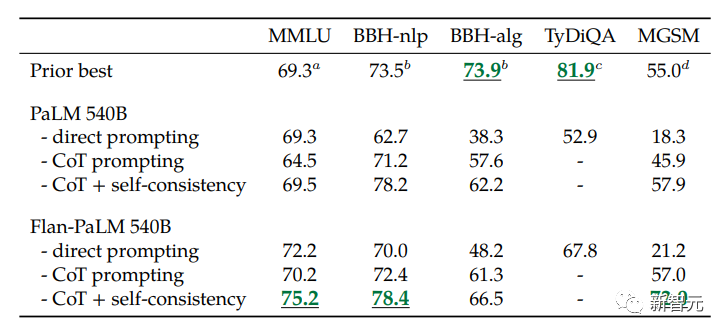
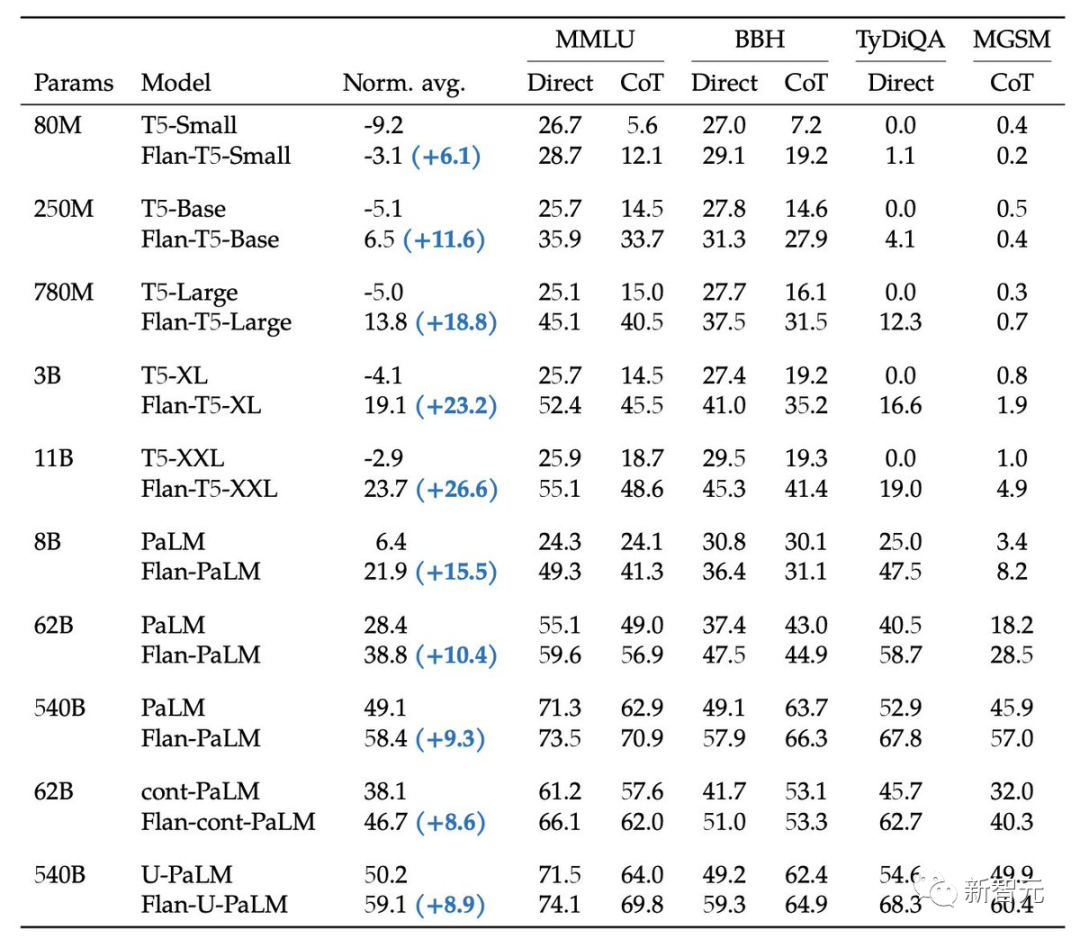
比如,在1.8K任务上进行指令微调的Flan-PaLM 540B,性能明显优于标准的PALM 540B(平均 + 9.4%),并且在5-shot的MMLU上,Flan-PaLM也实现了75.2%的准确率。
此外,作者还在论文中公开发布Flan-T5检查点。即便是与更大的模型(如PaLM 62B)相比,Flan-T5也能实现强大的小样本性能。

论文地址:https://arxiv.org/abs/2210.11416
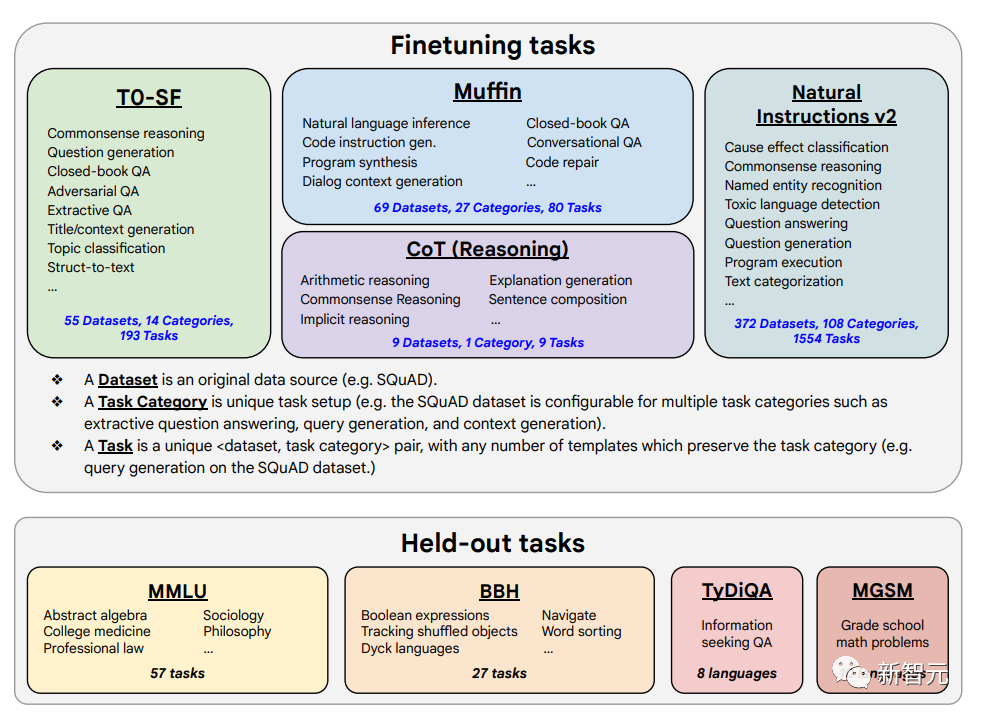
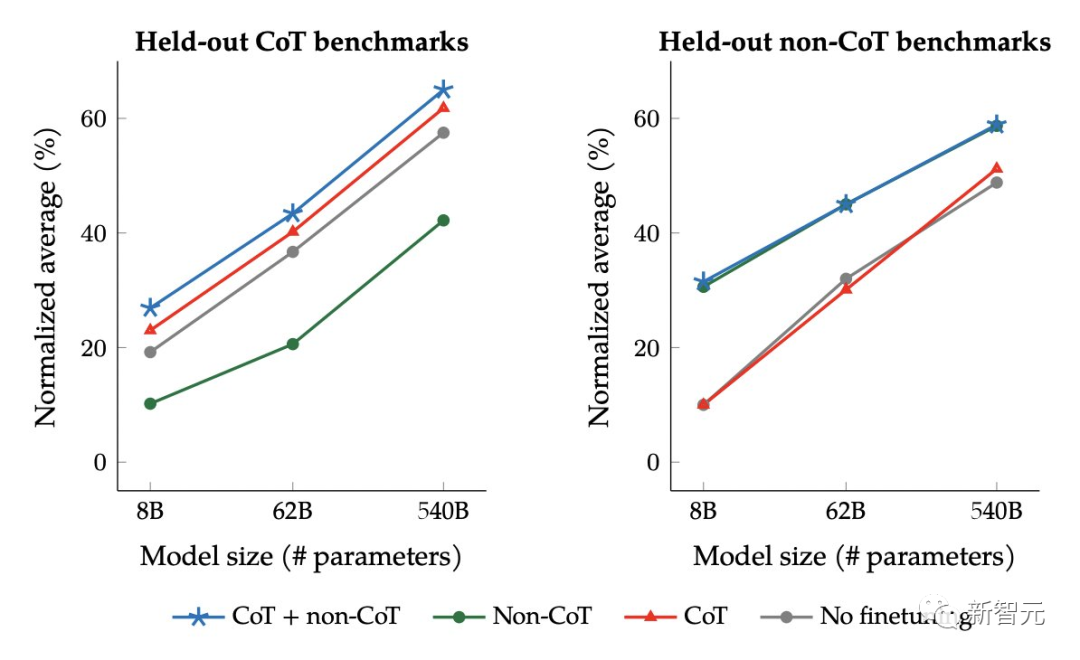
总结来说,作者通过以下三种方式扩展了指令微调:
-
扩展到540B模型
-
扩展到1.8K的微调任务
-
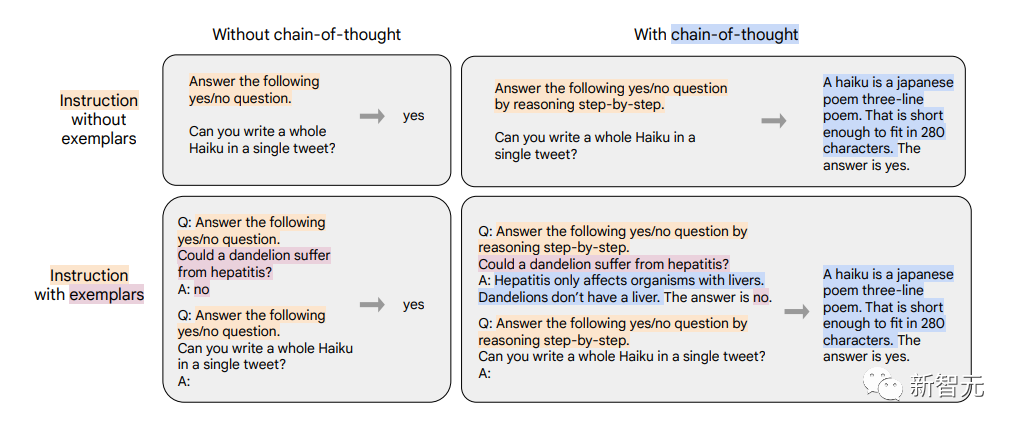
在思维链(CoT)数据上进行微调

谷歌的另一起「翻车」事件