二阶优化!训练ImageNet仅需35个Epoch
选自arXiv
作者:Kazuki Osawa 等
机器之心编译
在「x 分钟训练 ImageNet」问题上,人们通常采用的方法是增加批大小并加大算力。随着 ResNet-50 在 ImageNet 上的训练时间已用秒计,人们开始转向其他研究方向。来自东京工业大学的研究者近日采用二阶方法,实现了和优化 SGD 类似的准确率和效率。
随着神经网络的尺寸和训练数据的持续增长,人们对分布式计算的需求也逐渐增大。在深度学习中实现分布式并行的常用方式是使用数据并行方法,其中数据被分配进不同进程中,而模型在这些进程中重复。当每个模型的 mini-batch 大小保持不变,以增加计算/通信比时,整个系统上的 mini-batch 大小会随着进程数量成比例增长。
在 Mini-batch 大小超过某一点之后,验证准确率就会开始下降。这一大尺寸 mini-batch 泛化限制广泛见于学习不同的模型和数据集的情况中,Hoffer 等人曾将这种限制归因于更新的限制,同时建议进行更长的训练。这引出了增大学习率,并成比例增加 mini-batch 的方向,同时在训练的前几个 epoch 里逐渐增加学习率。这种方法可以让训练 mini-batch 达到 8k,在使用 ResNet-50 训练 ImageNet 时可以达到训练 90 epoch,达到 76.3% 的 top-1 验证准确率。将这种学习速率方法与其他的一些技术,如 RMSprop warm-up、无动平均的批归一化,以及缓速启动学习率策略等技术结合,Akiba 等人曾经实现在相同的数据集和模型上,batch size 32k 的情况下,在 15 分钟时间里实现 74.9% 的准确率。
当然,人们在这之后还找到了更加复杂的方法,如 LARS,其中人们通过对不同层的权重和梯度的归一化实现不同的学习速率。这使得我们在 mini-batch 大小为 32k 的情况下,无需特别的修正就可以在 14 分钟的训练后(64 epoch)达到 74.9% 的准确率。另外,结合 LARS 和批归一化反直觉修正结合,我们可以在 mini-batch 大小 65k 的情况下实现 75.8% 的准确率。
使用小 batch size 帮助前几个 epoch 的快速收敛,随后逐步增加批大小的方法是另外一个被证明成功的思路。使用这种自适应批大小的方法,Mikami 等人曾实现在 224 秒钟内达到 75.03% 的准确率。人们还提出了 mini-batch 的分层同步,但这些方法目前还没有经过人们的广泛验证。
在东京工业大学最近的研究中,人们通过使用二阶优化,采用数学上更加严谨的方法来处理大 mini-batch 的问题。研究人员认为在大 mini-batch 训练中,每一个 mini-batch 都会更具统计稳定性,通过二阶优化方法可能会展现优势。新方法的另一个独特性是与其他的二阶方法相比,前者可以接近 Hessian 的准确性。与 TONGA 等粗近似 Hessian 的方法、非 Hessian 方法不同,新方法采用 Kronecker 系数近似曲率(K-FAC)方法,K-FAC 的两个主要特征是它要比一阶随机梯度下降方法(SGD)要快,而且它可以容忍相对较大的 mini-batch 大小而无需任何特定修正。K-FAC 已经被成功用在了卷积神经网络、ImageNet 分布式内存训练、循环神经网络、贝叶斯深度学习和强化学习上。
在该论文中,研究人员的贡献包括:
使用同步 all-worker 的方式实现了分布式 K-FAC 优化器。研究人员使用半精度浮点数进行计算,并利用 Kronecker 系数的对称性减少算力消耗。
通过在 ImageNet 上训练 ResNet-50 作为基准,研究人员首次展示了二阶优化方法与高度优化的 SGD 相比可以实现类似的泛化能力。通过仅仅 35 个 epoch 的训练,研究人员即实现了 75% 的 top-1 准确率,其中 mini-batch 大小不到 16,384——而即使 mini-batch 达到了 131,072,准确度也为 75%。
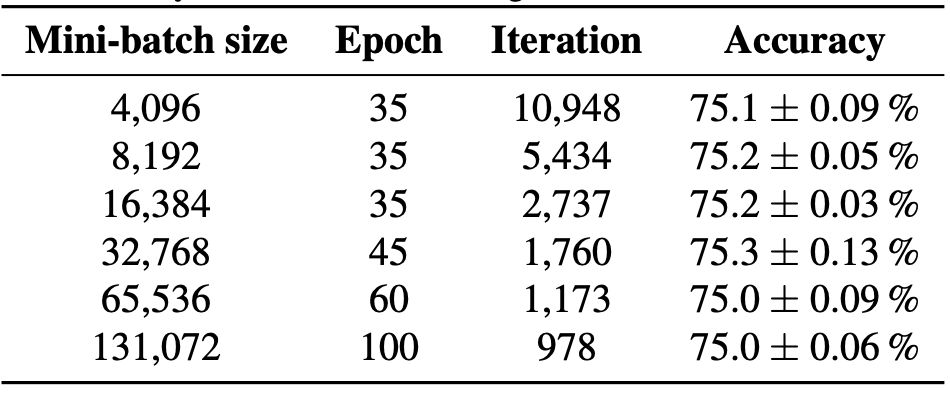
表 1:对带有 K-FAC 的 ImageNet,ResNet-50 的训练 epoch(迭代)和 top-1 单季验证准确率
论文展示了在经过数百次迭代后,我们能够减少更新 K-FAC Fisher 矩阵的频率。这么做我们能够减少 K-FAC 的成本。研究人员展示了在 10 分钟内,使用 1024 块 Tesla V100 GPU,训练 ResNet-50 的 Top-1 准确率准确率达到 74.9% 的结果。
论文显示,Batch 归一化层的 Fisher 矩阵可被近似为对角矩阵,进一步减少计算和内存消耗。
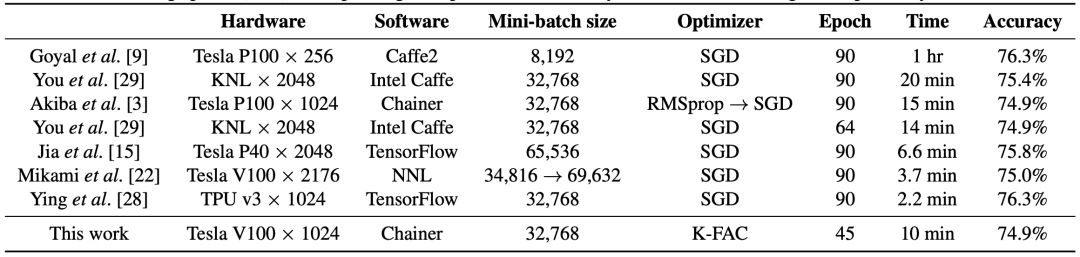
表 2:在 ImageNet 上训练 ResNet-50 的不同方法性能对比。
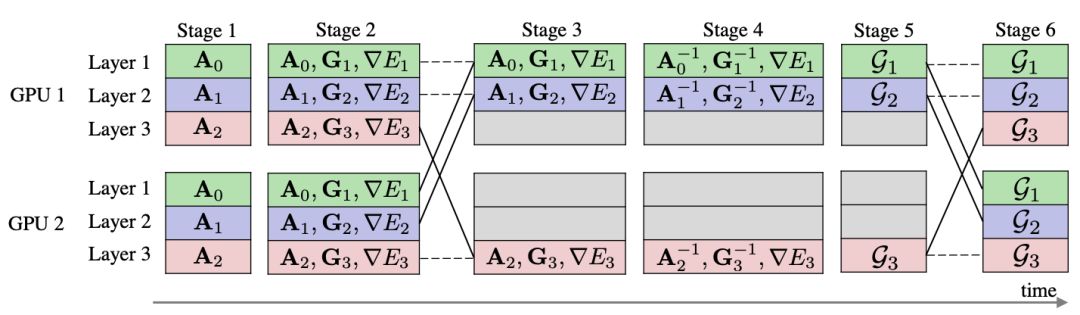
图 1:新的分布式 K-FAC 设计概览。在三层模型上有两个训练流程(GPU)。
论文:Second-order Optimization Method for Large Mini-batch: Training ResNet-50 on ImageNet in 35 Epochs

论文链接:https://arxiv.org/abs/1811.12019
摘要:深度神经网络的大规模分布式训练会遭受由有效 mini-batch 大小增加所带来的泛化差距。先前,曾有一些方法尝试使用改变 epochs 和层上的学习率来解决这一问题,或者对一些 batch 归一化做特别的修改。我们提出一种使用二阶优化方法的替代性方法,达到了类似于一阶方法的泛化能力,但其收敛更快且能处理更大的 mini-batch。为了在基准上测试我们的方法,我们在 ImageNet 上训练了 ResNet-50。在 35 个 epoch 内,我们的方法把低于 16,384 的 mini-batch 收敛到了 75% 的 Top-1 验证准确率,而即使是 mini-batch 大小为 131,072 时,我们花费 100 个 epoch 也只能取得 75% 的准确率。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



