初学者系列:FFM:Field-aware Factorization Machines
导读
点击率(CTR)预测在广告行业中起着重要作用。FM、FFM、Deep FM广泛用于此任务。本文我们主要介绍FM的变体,Field-aware Factorization Machines (FFM)的原理、推导过程,以及使用Tensorflow的简单实现。
获取代码
请关注专知公众号(点击上方蓝色专知关注)
后台回复“ 初学者系列FFM”即可获取数据集以及全部代码。
FFM是FM的变体,在开始介绍FFM之前,我们一起回顾一下FM的基本原理,FM使用分解参数对变量之间的所有交互进行建模,学习每个特征学习隐层向量,其输出公式如下:
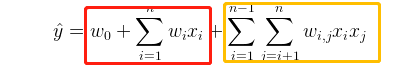
在FM中所有的样本都使用同一个V,即对于x_{11}与x_{12}都使用同一个v_1
FFM与FM的不同
01
FFM提出了Field-aware 的思想,即每一维特征(feature)都归属于一个特定的field,field和feature是一对多的关系。为更好的解释FFM与FM之间的不同,我们以论文中的数据为例:

对于FM每个特征只有一个隐藏向量来学习具有任何其他特征的潜在影响。

w_ESPN用于了解耐克(w_ESPN·w_Nike)和男性(w-ESPN·w-Male)的潜在影响。然而,由于Nike和Male属于不同的领域,(EPSN,Nike)和(EPSN,Male)的潜在影响可能不同。而对于FFM,每个特征都有几个潜在的向量。
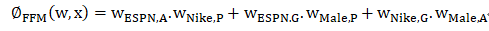
FFM原理
02
在FFM中,每一维特征 x_i,针对每一种field( fj)的特征,都会学习一个隐向量 v_{i,fj}。因此,隐向量不仅与特征相关,也与field相关。与FM模型类似,FFM模型方程定义为(为了计算简便只有交叉项):

其中:
fi和fj分别是x_i和x_j所属的field.
与FM模型不同,在FFM模型方程中,由于隐向量与fields有关故交叉项不可以化简。
在FFM中划分不同的fields是十分重要的一步,对于连续特征与离散特征有不同的field划分方法:
类别特征(Categorical Features ):采用one-hot编码,同一种属性的归到一个Field。
连续特征(Numerical Features ):一个特征对应一个Field。或者对连续特征离散化,应用类别特征的表示方法。
优化
03
我们将FFM问题定义为分类问题,使用的是logistic loss,加入正则项后FFM优化目标为:
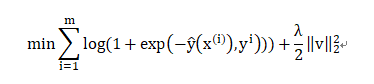
通过梯度下降方法(SGD)可以有效地学习FFM的模型参数v_{i,fj},v_{j,fi}.
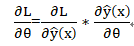
对于logistic 损失函数
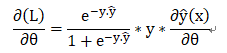
为了更好的理解对于不同的field特征是如何计算的,我们用如下例子进行推倒:
对于如下电影评分数据,我们以x^(0)为例:
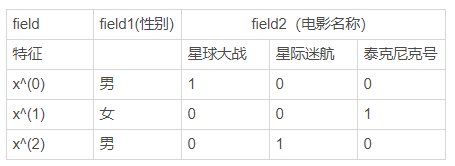
则x^(0)的输出y^(0)为:

则对v_{1,f2}求偏导得:

由于同一个field下只有一个feature的值不是0,其他feature的值都是0,故:
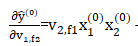
则
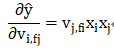
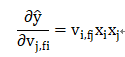
我们选择AdaGrad优化器进行优化,AdaGrad计算第t步之前累加的梯度平方和,作为学习率的分母,在训练的每一步自主地选择合适的学习率。具体过程如下:
随机采样一个点(y,x)来更新参数,计算一次梯度,并且只用计算非0值输入对应的参数,其梯度的计算如下所示
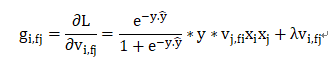

对每个坐标d=1,...,k ,累计梯度的平方和:
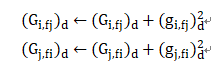
最后,进行梯度更新(红色框为每一步的学习率)
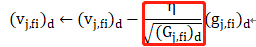
实践
04
FFM是一个细化隐向量非常好的方法,官方也给了实现FFM的libffm。为了更好地理解FFM是如何工作的,我们用FFM来实现一个简单的二分类。代码主要包含两部分内容,分别为data.py、FFM.py.
数据处理(data.py)
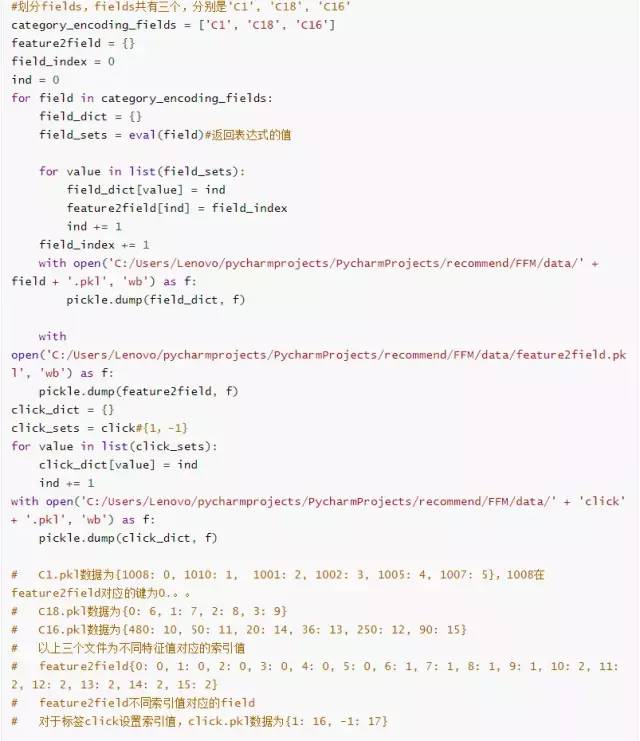
原始输入数据以点击率预测为例,共有16个特征,三个fields。数据处理主要包括特征提取、field划分以及将数据转化为one-hot类型这三部分内容。
类别型特征提取

field划分
根据每一个特征所属的field,构造字典。例如在feature2field={0: 0, 1: 0, 2: 0, 3: 0, ...}中, value为field,key为变量名的映射;在C1.pkl={1008: 0, 1010: 1, 1001: 2, 1002: 3,....}中,key为变量值,value为变量名的映射。这样就可以通过变量名映射找到各变量值所属的field。
数据集构造
在得到特征所属的field后,还需要对特征值进行one-hot处理才可以构建数据集。

经过处理后的输入x如下图所示,同一个field的特征值只有一个为0
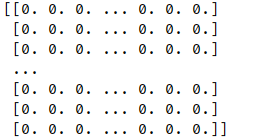
构造模型(FFM.py)
权重变量初始化(b,w1,v)

定义模型输出

加载数据
在进行训练之前需要先加载训练数据集,并将数据通过调用get_batch()函数,获得一个batch内传入的数据,再将每个batch内的输入特征通过transfer_data()转化为one-hot类型。


tips:get_batch()与transfer_data()在data.py中已经定义过。
优化
在该部分主要进行梯度计算与损失函数计算(加入了正则项)

开始训练
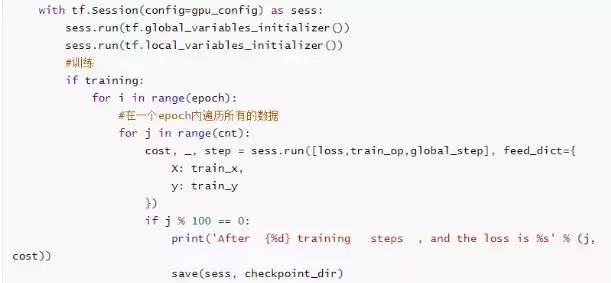
训练结果:

测试
在测试部分,输出了测试集的损失函数以及预测值。

测试结果如下:

参考链接:
https://github.com/sladesha/machine_learning/tree/master/FFM
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程



