一文读懂FM算法优势,并用python实现!(附代码)

作者:ANKIT CHOUDHARY
翻译:张媛
术语校对:冯羽
文字校对:谭佳瑶
本文共3933字,建议阅读9分钟。
本文带大家了解因子分解机算法并解析其优势所在,教你在python中实现。
介绍
我仍然记得第一次遇到点击率预测问题时的情形,在那之前,我一直在学习数据科学,对自己取得的进展很满意,在机器学习黑客马拉松活动中也开始建立了自信,并决定好好迎接不同的挑战。
为了做得更好,我购买了一台内存16GB,i7处理器的机器,但是当我看到数据集的时候却感到非常不安,解压缩之后的数据大概有50GB - 我不知道基于这样的数据集要怎样进行点击率预测。幸运地是,Factorization Machines(FM)算法拯救了我。
任何从事点击率预测问题或者推荐系统相关工作的人都会遇到类似的情况。由于数据量巨大,利用有限的计算资源对这些数据集进行预测是很有挑战性的。
然而在大多数情况下,由于很多特征对预测并不重要,所以这些数据集是稀疏的(每个训练样本只有几个变量是非零的)。在数据稀疏的场景下,因子分解有助于从原始数据中提取到重要的潜式或隐式的特征。
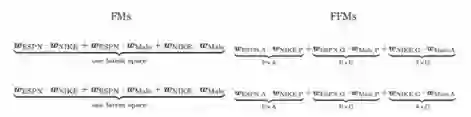
因子分解有助于使用低维稠密矩阵来表示目标和预测变量之间的近似关系。在本文中我将讨论算法Factorization Machines(FM) 和Field-Aware Factorization Machines(FFM),然后在回归/分类问题中讨论因子分解的优势,并通过python编程实现。
目录
1. 因式分解的直观介绍
2. FM算法如何优于多项式和线性模型
3. FFM算法介绍
4. 在python中使用xLearn库进行算法实现
因式分解的直观介绍
为了直观地理解矩阵分解,我们来看一个例子:假设有一个用户-电影评分(1-5)矩阵,矩阵中的每一个值表示用户给电影的评分(1-5)。
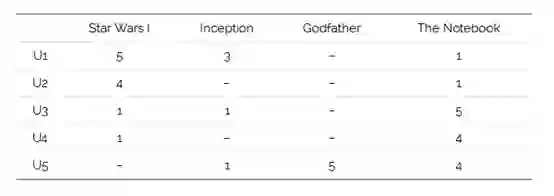
从上述表格中我们可以看出,一些评分是缺失的,我们想设计一种方法来预测这些缺失的评分。直观上来讲,利用矩阵分解来解决这个问题的关键是应该有一些潜在的特征决定用户如何评价一部电影。举例来说 - 用户A和B都是演员阿尔·帕西诺的粉丝,那么他们就会对阿尔·帕西诺的电影评分较高。在上述例子中,对特定演员的偏好是一个隐藏的特性,因为我们没有明确地将其包含在评分矩阵中。
假设我们要计算K个隐藏或潜在的特征,我们的任务是找出矩阵P (U x K)和Q (D x K) (U – 用户, D – 电影),使得 P x QT 近似等于评分矩阵R。
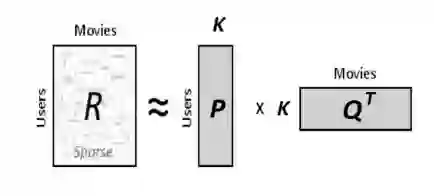
P矩阵的每一行表示用户与不同特征的相关性,Q矩阵的每一行表示该特征与电影同样的相关性。为了得到用户ui对电影dj的评分,我们可以计算对应于ui和dj两个向量的点积。
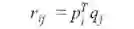
接下来要做的就是求出矩阵P和矩阵Q。我们使用梯度下降算法来计算,目标函数是使用户的实际评分与通过矩阵P和Q估计的评分之间的平方误差最小,这里的平方误差由以下方程求出。
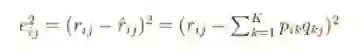
现在我们要给pik和qkj定义一个更新规则,梯度下降法中的更新规则是由最小化误差值的梯度来定义的。
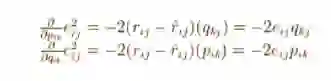
获得梯度值后,接下来可以定义pik和qkj的更新规则。
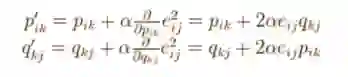
这里α是控制更新步长的学习速率,使用上述更新规则,我们可以迭代地执行操作,直到误差收敛到最小,同时使用下面的公式计算总的误差,以此来确定什么情况下应该停止迭代。
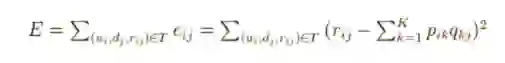
上述解决方案很简单并且经常会导致过拟合,即现有的评分都被准确预测到,但是不能很好地推广到未知的数据上。为了解决这个问题,我们可以引入一个正则化参数 β,它将分别控制矩阵P和Q中向量“用户-特征”和“电影-特征”,并给出一个更好的评分的近似值。
如果对利用python实现上述功能和相关细节感兴趣,请参考这个链接http://www.quuxlabs.com/wp-content/uploads/2010/09/mf.py_.txt。一旦我们用上述方法计算出了矩阵P和Q,得到的近似评分矩阵如下:
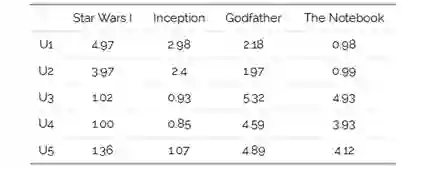
现在,我们既能够重新生成现有评分,也能对未知的评分进行一个合理的近似。
FM算法如何优于多项式和线性模型
首先考虑一组点击率预测数据的训练示例。以下数据来自相关体育新闻网站(发布商)和体育用品公司(广告商)。
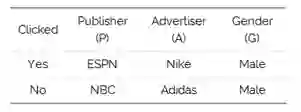
当我们讨论FM或者FFM的时候,数据集中的每一列(比如上述表格中的出版商、广告商等)将被称为一个字段,每一个值( ESPN、Nike 等)都被称为一个特征。
线性或逻辑回归模型在很多问题上表现很好,但缺点是这种模型只能学习所有变量或者特征各自的影响,无法学习变量之间的相互作用
。
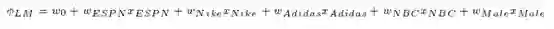
在上述等式中,w0、wESPN等代表参数,xESPN、xNike等代表数据集中的各个特征,通过最小化上述函数的对数损失,得到逻辑回归模型。捕获特征之间相互作用的一种方法是使用多项式函数,将每个特征对的乘积作为单独的参数来学习,并且把每一个乘积作为一个独立的变量。
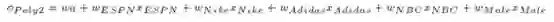
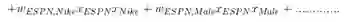
这也可以称为 Poly2模型,因为每一项都只考虑了两个特征之间的相互影响。
问题在于,即使面对一个中等大小的数据集,也需要一个庞大的模型,这对存储模型所需要的内存空间和训练模型所花费的时间都有很大的影响;
其次,对于一个稀疏数据集,这种技术不能很好地学习所有的权重或参数,因为没有有足够的训练样本使每一个特征对的权重是可靠的。
救星FM
FM算法解决了成对特征交互的问题。它使我们能够根据每一对特征组合中的可靠信息(隐藏特征)来训练模型,同时在时间和空间复杂度上更有效地实现上述目标。具体来讲,它将成对交互特征作为低维向量的点积(长度为K)进行建模,以下包含了一个二阶因子分解的方程。
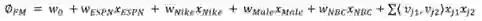
FM(K=3)项中每个参数的表示方法如下:
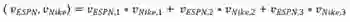
上述等式中,我们分别计算了与2个特征对应的2个长度为3的潜因子的点积。
从建模的角度来看,这是非常强大的,因为每一个特征最后都会转换到一个相似特征被互相嵌套的空间,简而言之,点积基本上表示了潜在特征的相似程度,特征越相近,点积越大。
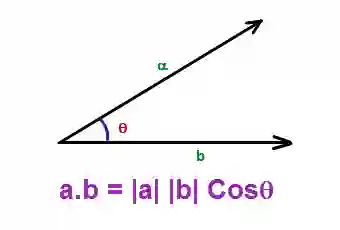
对于余弦函数,当 θ是0时,得到最大值1;当 θ是180度,得到-1,所以当 θ接近于0时,相似性最大。
FM算法的另一个巨大优势是能够在线性时间复杂度下使用简单的数学方法计算模型中成对特征的相互作用。如果你想进一步了解具体的实现步骤,请参考链接中关于FM算法的原始研究论文。
https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
示例:FM算法性能优于 POLY2算法的演示
考虑以下一组虚构的点击率数据:
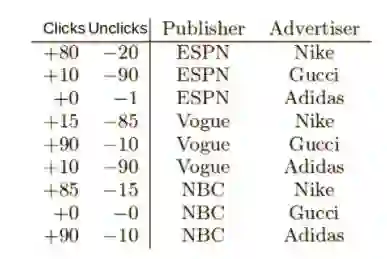
这个数据集由作为发布者的体育网站和体育用品广告商构成。广告是以弹出的方式来显示的,用户可以选择点击广告或者关闭广告。
特征对(ESPN,Adidas)只有一个负的训练数据,那么在Poly2算法中,这个特征对可能会学到一个负的权重值wESPN,Adidas;而在FM算法中,由于特征对(ESPN,Adidas)是由wESPN·wAdidas决定的,而其中的wESPN和wAdidas分别是从其他特征对中学到的(比如(ESPN,Nike),(NBC,Adidas)等),所以预测可能更加精确。
另一个例子是特征对(NBC,Gucci)没有任何训练数据,对于Poly2算法,这个特征对的预测值为0;但是在FM算法中,因为wNBC和wGucci可以从其他特征对中学到,所以仍然有可能得到有意义的预测值。
FFM算法介绍

为了理解FFM算法,我们需要认识field的概念。field通常是指包含一个特定特征的更广泛的类别。在上述训练示例中,field分别指发布者(P)、广告商(A)和性别(G)。
在FM算法中,每一个特征只有一个隐向量v,来学习其他特征带来的潜在影响。以ESPN为例,wESPN被用来学习特征Nike(wESPN·wNike)和Male(wESPN.wMale)之间的潜在作用。
但是,由于ESPN和Male属于不同的field,所以对特征对(ESPN,Nike)和(ESPN,Male)的起作用的潜在作用可能不同。FM算法无法捕捉这个差异,因为它不区分field的概念,在这两种情况中,它会使用相同参数的点积来计算。
在FFM算法中,每个特征有若干个隐向量。例如,当考虑特征ESPN和Nike之间的交互作用时,用符号wESPN,A来表示ESPN的隐藏特征,其中A(广告商)表示特征Nike的field。类似的,关于性别的field的一个重要的参数wESPN,G也会被学习到。
事实证明,FFM算法对获得由 Criteo、Avazu、Outbrain举办的点击率(CTR)比赛第一名是至关重要的,同时也帮助赢得了2015年RecSys挑战赛的三等奖。关于点击率数据集可以从Kaggle获得。
在python中使用xLearn库进行算法实现
一些在python中实现FM & FFM的最流行的库如下所示:

为了在数据集上使用FM算法,需要将数据转换为libSVM格式。以下为训练和测试的数据文件格式:
<label> <feature1>:<value1> <feature2>:<value2> …
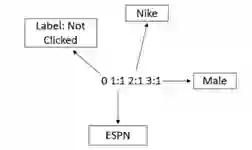
在增加了field的概念之后,每个特征被唯一编码并被赋值,上述图中,特征ESPN用1表示,特征Nike用2表示,以此类推。每一行包含一个等效的训练示例并以“\ n”或换行符结尾。
对于分类(二进制/多类),<label>是一个指示类标签的整数。
对于回归,<label>是任何实数的目标值。
测试文件中的标签仅用于计算准确度或误差,未知的情况下可以用任何数值填写第一列。
同样,对于FFM算法,需要将数据转换为libffm格式。在这里,我们也需要对field进行编码,因为该算法需要field的信息来学习。格式如下:
<label><field1>:<feature1>:<value1><field2>:<feature2>:<value2> …
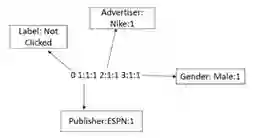
有关数值特征的重要说明
数值特征需要被离散化(通过将特定数值特征的整个范围分成较小的范围并且分别对每个范围进行标记编码而转换为分类特征),然后如上所示转换为libffm格式。
另一种可能性是添加一个与特征值相同的虚拟field值,它将是该特定行的数值特征(例如,具有值45.3的特征可以被变换为1:1:45.3)。 但是虚拟field值可能不包含任何信息,因为它们仅仅是这些数值特征的复制品。
xLearn
最近推出的xLearn库提供了一个在各种数据集上实现FM和FFM模型的快速解决方案。 它比libfm和libffm库快得多,为模型测试和调优提供了更好的功能。

在这里,我们将用一个例子来说明FFM算法,数据来自Criteo点击率预测挑战赛中CTR数据集的一个微小(1%)抽样。 你可以从这里[Office1] 下载这个数据集。
但首先我们需要将其转换为xLearn所需的libffm格式以拟合模型。 以下函数将标准数据帧格式的数据集转换为libffm格式。
df = Dataframe to be converted to ffm format
Type = Train/Test/Val
Numerics = list of all numeric fields
Categories = list of all categorical fields
Features = list of all features except the Label and Id


xLearn可以直接处理csv以及libsvm格式的数据来实现FM算法,但对FFM算法而言,我们必须将数据转换为libffm格式。
一旦我们有了libffm格式的数据集,就可以使用xLearn库来训练模型。
类似于任何其他机器学习算法,数据集被分成一个训练集和一个验证集。xLearn使用验证/测试对数损失来自动执行提前停止的操作,并且我们还可以在随机梯度下降的迭代中为验证集设置其他的监控指标。
下面的python脚本可以用于在ffm格式的数据集上使用xLearn来训练和调整FFM模型的超参数。


该库还允许我们使用cv()函数进行交叉验证:

可以使用以下代码片段对测试集进行预测:

结语
在这篇文章中,我们已经演示了对一般分类/回归问题的因式分解的用法。如果您在执行这个算法的过程中遇到任何问题请及时告知我们。有关xLearn详细文档将在这个链接中给出,并会得到定期更新和支持。
http://xlearn-doc.readthedocs.io/en/latest/python_api.html
原文链接:
https://www.analyticsvidhya.com/blog/2018/01/factorization-machines/

张媛,某云计算公司不务正业服务工程师一枚。喜欢下雨天,读闲书,缺乏技术细胞,欣赏并喜欢有态度有立场的人,爱浪漫,注重仪式感,喜欢记录。最近的愿望是拥有自己的小窝,给想念的人写一封信。
翻译组招募信息
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。

点击“阅读原文”加入组织~


