CrossWOZ,一个大规模跨领域中文任务导向对话数据集

2018 年,任务导向对话数据集 MultiWOZ 横空出世,并被评为当年 EMNLP 最佳资源论文。由于其大规模多领域的特点,引发了任务导向对话领域新的一轮发展热潮。
为了进一步推动多领域(特别是跨领域)的研究以及填补中文任务导向对话数据的空白,清华大学计算机系、人工智能研究院 CoAI 小组构建了 CrossWOZ,一个大规模跨领域中文任务导向对话数据集。论文已被 Transactions of the Association for Computational Linguistics (TACL) 接收。

▲ CrossWOZ的一个对话片段,具体酒店名字被A,B,C替代
相比于之前的任务导向对话数据集(特别是MultiWOZ),CrossWOZ有三大特点:
1. 在对话中,用户在某个领域的选择可能会影响到与之相关的领域的选择。如上面的这个例子,用户选择了北京欢乐谷作为景点领域的结果,那么之后选择的酒店就要在它附近。不同的景点选择会对酒店产生不同的约束。这种跨领域约束随着对话的进行而具体化,需要对话双方都能对上下文有更好的理解,因而更具有挑战性。
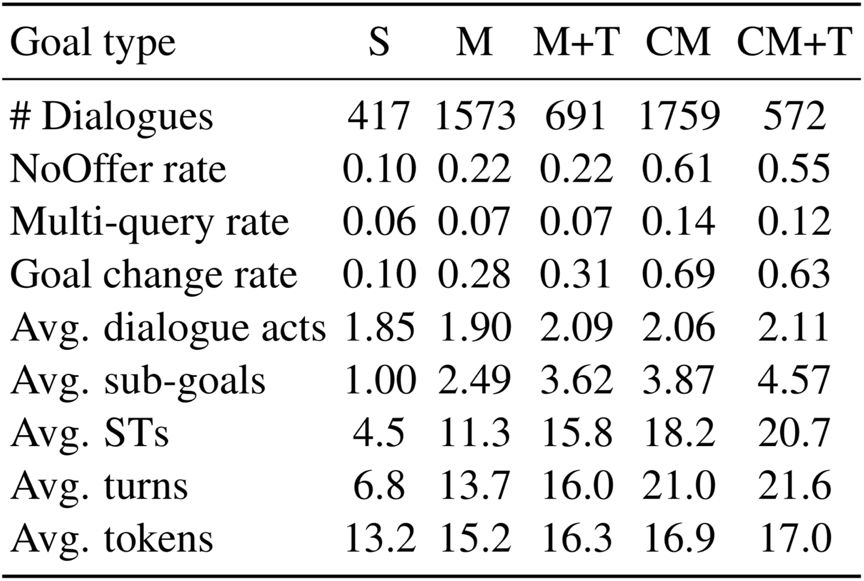
2. 这是第一个中文大规模多领域任务导向对话数据集,包含 6K 个对话,102K 个句子,涉及 5 个领域(景点、酒店、餐馆、地铁、出租)。平均每个对话涉及 3.2 个领域,远超之前的多领域对话数据集,增添了对话管理的难度。
3. 标注信息全面,可以用于研究任务导向对话系统中各个方面。除了提供对话双方的对话意图、系统端的对话状态这些信息之外,还额外提供了每轮用户端的对话状态。用户端状态记录了目标的完成情况,每轮根据系统回复动态更新,可用于研究用户模拟器的搭建。

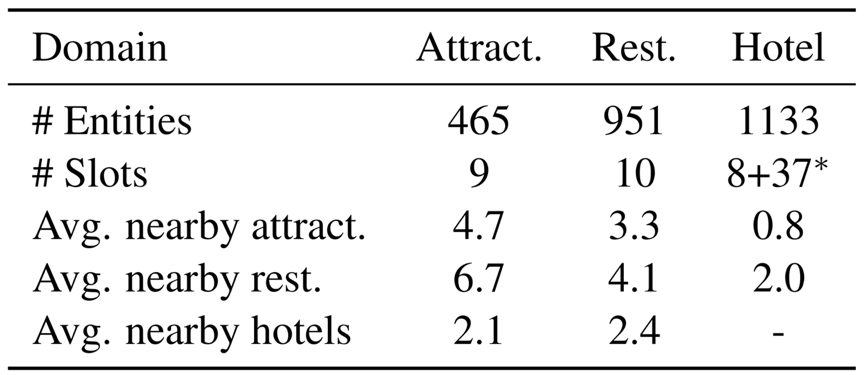
▲ 数据库统计信息
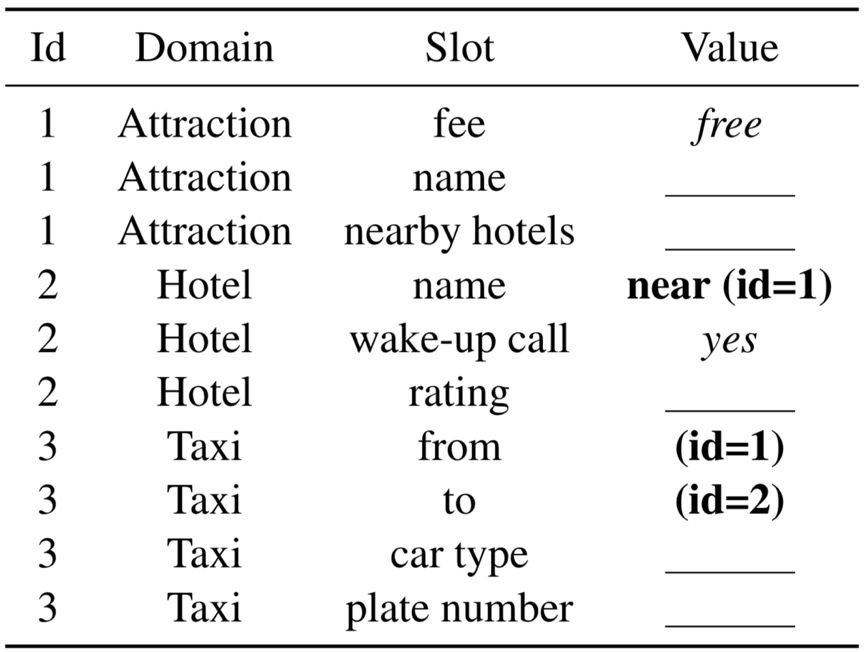
▲ 用户目标示例
3. 对话数据收集:雇佣人员在线匹配进行实时对话。用户端以用户目标作为初始状态,通过对话获取信息,每轮更新用户状态,填写需求的信息和替换跨领域的约束。并选择本轮要表达的约束或者要询问的信息。系统端每轮维护各个领域的查询表单作为系统状态,根据查询结果回复用户。
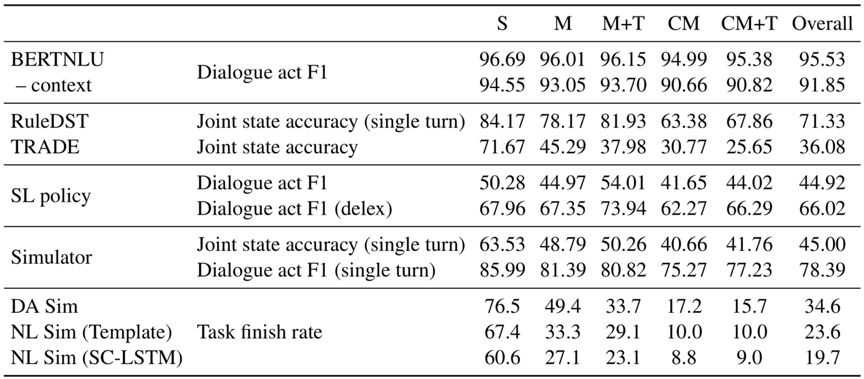
4. 数据处理:使用一些规则根据用户和系统的状态推导出对话意图。经过三个专家对少量对话的核验,数据标注质量较高。



点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。







